-
正则表达式简介
正则表达式为高级的文本模式匹配、抽取、或者文本形式的搜索与替换提供了基础。正则表达式(regex)是由字符和特殊符号组成的字符串,它们描述了模式的重复或者表述多个字符(就是描述了一个可以识别各种字符串的模式),于是正则表达式能够按照某种模式匹配一系列有相似特征的字符串。
Python通过调用标准库中的re模块来使用正则表达式。(加载模块此文闭口不谈,默认自己会)
1.1 特殊符号和字符
常见的特殊符号和字符,这些就是正则表达式的根基。
| 表示法 | 描述 |
| 符号 | |
| str | 匹配字符串的字面值 |
| re1 | re2 | 匹配正则表达式re1或者re2 |
| . | 匹配任何字符(除了换行符\n之外) |
| ^ | 匹配字符串的起始部分 |
| $ | 匹配字符串的终止部分 |
| * | 匹配0次或者多次前面出现的正则表达式 |
| + | 匹配1次或者多次前面出现的正则表达式 |
| ? | 匹配0次或者1次前面出现的正则表达式 |
| {N} | 匹配N次前面出现的正则表达式 |
| {M,N} | 匹配M-N次前面出现的正则表达式 |
| {M,} | 匹配至少M次前面出现的正则表达式 |
| [...] | 匹配来自字符集的任意单一字符 |
| [x-y] | 匹配x-y范围中的任意单一字符(数字也可使用此方法[0-9]) |
| [^...] | 不匹配此字符集中出现的任何一个字符,包括某一范围的字符 |
| (...) | 匹配封闭的正则表达式(实际使用中就是可以满足你匹配一个词语、成语或者单词的需要),然后另存为子组 |
| .+?或者.*? | 非贪婪模式匹配(后面将会提到) |
| 特殊字符 | |
| \d | 匹配任何十进制数字,与[0-9]效果一样。\D与之相反 |
| \w | 匹配任何字母数字字符,与[A-Za-z0-9]相同, \W与之相反。 |
| \s | 匹配任何空格字符,与[\n\t\r\v\f]相同 (防止不懂,\n\r表示换行,\t为制表符,\v为垂直制表符,\f为换页符。) |
| \b | 匹配任何单词边界(\B与之相反) |
| \N | 匹配已保存的子组 |
| \c | 匹配特殊字符(去掉特殊字符的特殊含义) |
| 扩展表示法 | |
| (?iLmsux) | 在正则表达式中嵌入一个或者多个特殊“标记”参数 |
| (?:...) | 一个匹配不用保存的分组 |
| (?P<name>...) | 像一个仅由name标识而不是数字ID标识的正则分组匹配 |
| (?P=name) | 在同一字符串中匹配由(?P<name>分组的之前文本) |
| (?#...) | 表示注释 |
| (?=...) | 匹配条件是如果。。出现在之后的位置,而不使用输入字符串,称作正向前视断言 |
| (?!...) | 匹配条件是如果。。不出现在之后的位置,而不使用输入字符串,称作负向前视断言 |
| (?<=....) | 匹配条件是如果。。出现在之前的位置,而不使用输入字符串,称作正向后视断言 |
| (?<!...) | 匹配条件是如果。。不出现在之前的位置,而不使用输入字符串,称作负向后视断言 |
| (?(\d/name)Y\N) | 如果分组所提供的id或者name(名称)存在,就返回正则表达式的条件匹配Y,如果不存在,就返回N |
1.2 正则表达式模块下函数
re模块函数
re.complie(pattern,flags=0) 使用任何可选的标记来编译正则表达式的模式,然后返回一个正则表达式对象。
re模块函数和正则表达式对象的方法
re.match(pattern,string,flags = 0) 尝试使用带有可选的标记的正则表达式的模式是来匹配字符串(从字符串的起始部分 开始匹配)。如果匹配成功,就返回匹配对象;如果失败,就返回None。
re.search(pattern,string,flags= 0) 使用可选标记搜索字符串中第一次出现的正则表达式模式。如果匹配成功,则返回匹 配 对象;如果失败就返回None。
re.findall(pattern,string) 查找字符串中所有(非重复)出现的正则表达式模式,并返回一个匹配列表。
re.finditer(pattern,string) 与findall()函数相同,返回的是一个迭代器。对于每一次匹配,迭代器都返回一个匹配对象。
re.split(pattern,string,max=0) 根据正则表达式的模式分隔符,spilt函数将字符串分割成列表,然后返回成功匹配的 列表,分割最多操作max次。
re模块函数和正则表达式对象方法
re.sub(pattern,replace,string,count = 0) 使用replace替换所有正则表达式的模式在字符串中出现的位置,除非定义 count,否则就将替换掉所有出现的位置。
常用的匹配对象方法
group(num=0) 返回整个匹配对象,或者编号为num的特定子组 groups(deault = None) 返回一个包含所有匹配子组的元组(如果匹配不成功,则返回空元组) groupdict(deault=None) 返回一个包含所有匹配的命名子组的字典,所有子组名称作为字典的键(如果匹配失败,返回空字典) 常用的模块属性 re.I、re.IGNORECASE 不区分大小写的匹配 re,L、re.LOCALE 根据所使用的本地语言环境通过\w、\W、\B、\b、\S、\s实现匹配。 re.M、re.MULTILINE ^和$分别匹配目标字符串中行的起始和结尾,而不是严格匹配整个字符串本身的起始和结尾.
re.S 点号能够匹配所有字符 re.X 通过反斜线转义 1.3 疑点
1、匹配单词边界:\b(匹配的是位置,不是字符)
注意:边界位置指的是匹配的那一侧单词与紧接着的是非字母数字之间的位置。
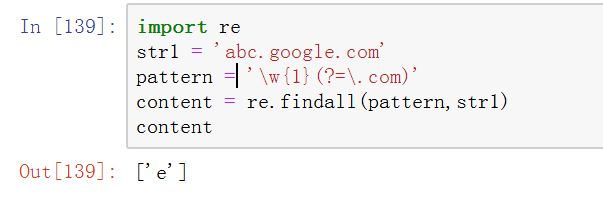
2、扩展表示法中(?=.)(正向前视断言)。匹配的是位置,并不是字符。然后以匹配到的位置进行前向断言。
下图所示中,正则表达式模式表示若某个字符串后面跟着.'.com' 则匹配前面的字符。结果很显然,匹配到.com位置处(图中黑线处)然后向前匹配。
tips:需要注意的是,匹配是从位置处向前按顺序匹配的。
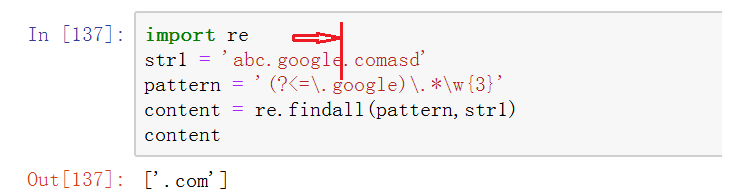
2、 扩展表示法中(?<=.)(正向后视断言)
图中正则表达式模式表示:如果一个字符串前面跟着字符串.google 那么则进行匹配之后的字符。
正向前视和正向后视断言:前视与后视字面意思就是向前看与向后看。在条件满足时在位置处向前看与向后看。


3、字符集[ ]的使用
正则表达式能够匹配字符集中包含的任何字符。
'x[abc]' #该正则表达式模式表示:匹配两个字符的字符串,第一个字母为x,后面跟着a或b或c。('xa','xb','xc'是所有可能匹配到的情况) '[ab][cd]' ##该正则表达式模式表示:匹配两个字符的字符串.第一个字符串为a或者b,第二个字符为c或者d。4、贪婪匹配:
+? ?? *? 这三种模式可以避免贪婪匹配。5、闭包操作符
星号或者星号操作符(*)将匹配其左边的正则表达式出现零次或者多次的情况(在计算机编程语言和编译原理中,该操作称为 Kleene 闭包)。加号(+)操作符将匹配一次或者多次出现的正则表达式(也叫做正闭包操作符)