协同过滤推荐算法
协同过滤推荐算法(collaborative filtering recommendation CF)
CF是推荐系统中应用最为广泛和成功的算法。此算法的前提假设是用户a与用户b均对一系列相同的物品表示喜欢,那么a极有可能也喜欢b用户喜欢的其他物品。
思想:
用户首先为每个项目进行评分打分,通过计算不同的用户评分之间的相似程度(即评分结果相似的),可以找到最近邻居的评分,产生推荐
举例:一共4个用户,7本书,每个用户对每本书的评价矩阵如下(满分5分)
|
Book1 |
Book2 |
Book3 |
Book4 |
Book5 |
Book6 |
Book7 |
李 |
4 |
|
|
5 |
1 |
|
|
刘 |
5 |
5 |
4 |
4 |
2 |
|
|
张 |
2 |
|
|
1 |
5 |
4 |
|
赵 |
|
3 |
|
|
|
|
3 |
第一步:寻找与李品味最接近的用户
即打分接近的用户,如上表,李对Book1和Book4这两本书有极高的评价,单数不喜欢Book5,通过观察可以发现刘对Book1和Book4的评价可很高,对book 5的分数也很低,因此可知,李和刘的品味较为接近的,那么刘就是李的最邻近用户
当用户多起来的时候就不能简单找到李的邻居用户,所以建立以一个模型来找到李的邻居用户,如果把上面表格中的每一行看做是一个响亮,这个响亮就用了表示用户的喜好,那么就可以用多种方法来衡量两个用户喜好的相似度,如余弦相似度,皮尔逊相似度等
余弦相似度:

其中cos(u1,u2)就表示用户u1和用户u2的相似度;
R就是评价矩阵,Ru1,y表示用户u1对书本y的评分,Ru2,y表示用户u2对书本y的评分;
分子中的y表示用户u1与用户u2评价过的书本的交集
分母中的y表示用户u1与用户u2各自的评价集合
第二步:利用李的最近邻居用户预测李的评分值
我们可以遍历所有用户,李与每个人都计算出一个相似度,随后对相似度拍苏,选择前10个相似度最高的用户作为李的最邻近用户,然后用着10个邻用户的评分数据来给李进行推荐;
公式:
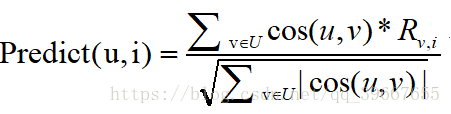
Predict(u,i)表示用户u对音乐i的打分预测值;
U就是用户u的最邻近用户集合(例前10个最邻近用户构成的集合);
R就是评价矩阵;Rv,i表示邻近用户v对书本i的评分
cos(u,v)就表示用户u对v的余弦相似度,
第三步:推荐
将一些李从未听过的书本(即没有评过分的书本)利用Predict(u,i)进行排序,选择前10个Predict分数最高的书本推荐给李即可
优点:
1)用能够过滤机器难以自动内容分析的信息,如音乐,艺术品
2)参考其他人的喜好,避免了任荣人习得不完全或不精确,能够载感性方面进行过滤
3)可以推荐出新的信息,发现潜在喜好
4)推荐个性化,自动化高,能有有效的利用其它相似用户的反馈信息加快个性化学习的速度
缺点:
1)新用户问题,系统在初期是推荐质量差
2)新项目问题,质量取决于历史数据集
3)稀疏性问题
4)系统延伸性问题
参考:http://www.cnblogs.com/exlsunshine/p/4065889.html