1.参考:https://www.cnblogs.com/CheeseZH/p/5265959.html
支持向量机实现多分类
(1)一对多:训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
(2)一对一:其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。
2.参考:https://blog.csdn.net/uui0408/article/details/75288991
LSSVM分类和回归
(1)如果说分类是用一个超平面将两组数据分开的话,回归就是用一个超平面对已知数据进行拟合。由于同样是求一个最优超平面,所以目标函数是一样的,但约束条件不同。
(2)代码:
https://blog.csdn.net/Luqiang_Shi/article/details/84204636#LSSVMpython_76
https://github.com/shiluqiang/LSSVM_python_code
3.参考:https://blog.csdn.net/garfielder007/article/details/51378296
numpy.hstack()函数,水平上合并数组
numpy.vstack()函数,垂直上合并数组
4.参考:https://blog.csdn.net/dengheCSDN/article/details/78109253?locationNum=2&fps=1
核函数值是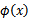
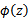
径向基函数是某种沿径向对称的标量函数。 通常定义为空间中任一点x到某一中心xc之间欧氏距离的单调函数 ,可记作 k(||x-xc||), 其作用往往是局部的 , 即当x远离xc时函数取值很小。