之前项目中使用过protocolbuffer进行序列化,当时就只是使用了protocalbuffer的工具生成了一个类的序列化工具。今天研究公司的序列化项目,发现应该是借用protocalbuffer的序列化思想来实现的,特意研究一下protocalbuffer的序列化实现原理。
主要思想
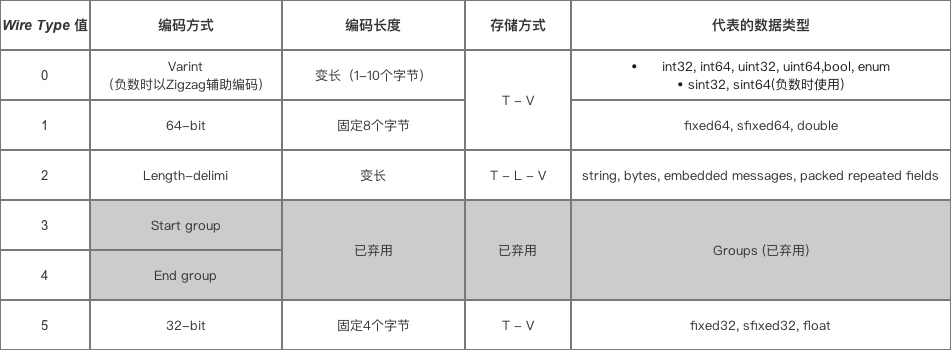
将对象的字段的类型和字段名序列化为tag表示,值序列化为value。
存储时按照t-l-v的顺序,先序列化tag类型标签,在记录length长度,在记录value值。 固定长度是不需要length。
tag
记录字段的标识号(fieldnumber)和 数据类型(wiretype),即Tag = 字段数据类型(wiretype) + 标识号(fieldnumber) 占用 一个字节 的长度(如果标识号超过了16,则占用多一个字节的位置)
具体实现
// Tag 的具体表达式如下
Tag = (fieldnumber << 3) | wiretype
// 参数说明:
// fieldnumber:对应于 .proto文件中消息字段的标识号,表示这是消息里的第几个字段
// fieldnumber << 3:表示 fieldnumber = 将 Tag的二进制表示 右移三位 后的值
// fieldnum左移3位不会导致数据丢失,因为表示范围还是足够大地去表示消息里的字段数目
// wiretype:表示 字段 的数据类型
// wiretype = Tag的二进制表示 的最低三位值
// wiretype的取值 enum WireType { WIRETYPEVARINT = 0, WIRETYPEFIXED64 = 1, WIRETYPELENGTHDELIMITED = 2, WIRETYPESTARTGROUP = 3, WIRETYPEENDGROUP = 4, WIRETYPEFIXED32 = 5 };
// 从上面可以看出,wire_type最多占用 3位 的内存空间(因为 3位 足以表示 0-5 的二进制)先介绍一下最主要的两种编码方式,在对字段名和类型的标识中会用到这两种编码方式。
writetype=0时的序列化
主要用到了varint类型的编码和zigzag编码
varint编码
一种变长的编码方式
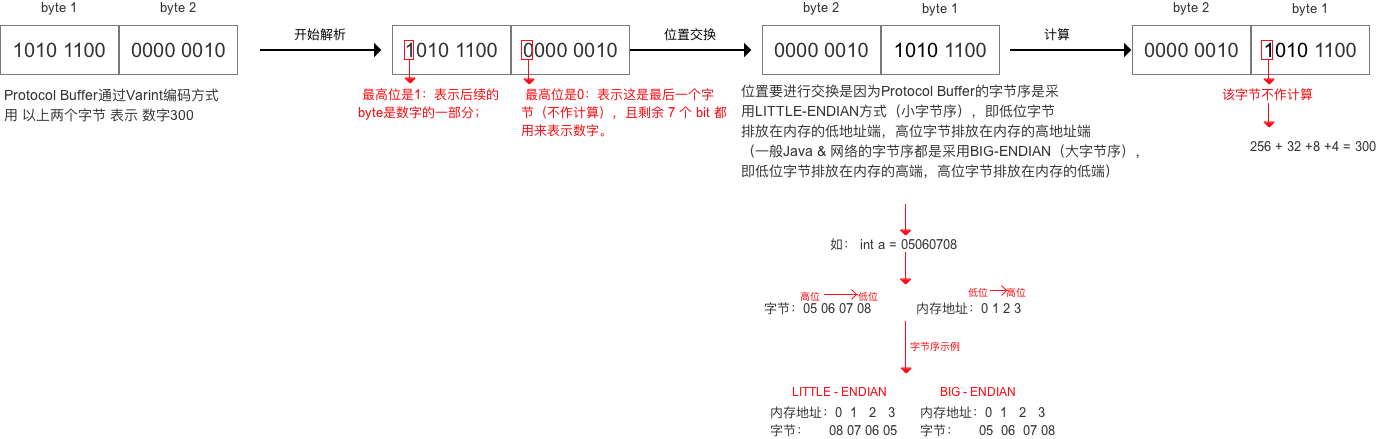
主要思想就是:每个字节的第一位标识后面本字节是否是当前value的最后一个字节,剩下七位表示value的值,所以如果值很小的时候可以用一个字节就能表示。

不足之处
因为通常序列化的value值都比较小,所以通常用vartint编码都可以减少字节长度,但是如果值比较大就会占用到5个字节。负数因为首位的符号位是1,所以如果用varint标识负数都会使用5个字节。
zigzag编码
一种变长的编码方式
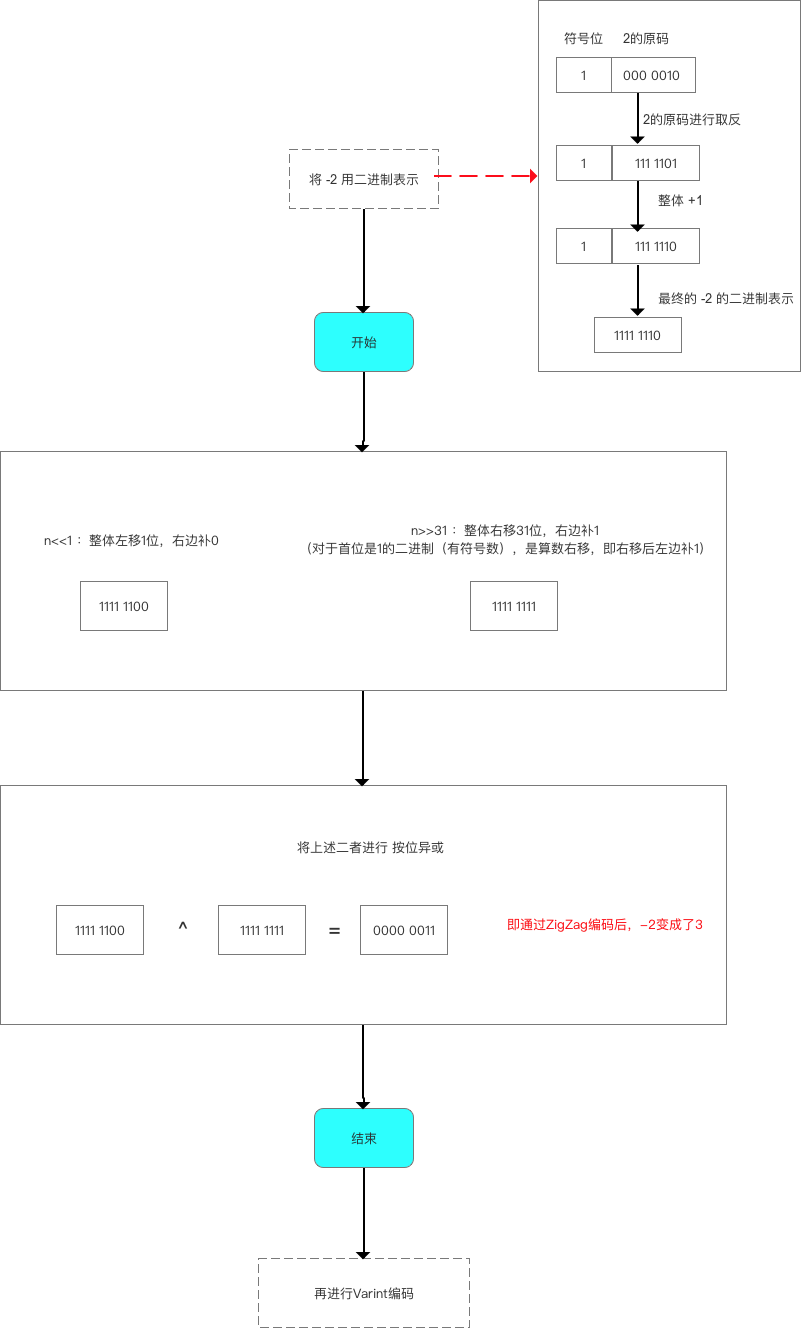
主要思想就是:先使用ZigZig编码将负数映射成正数,然后再使用Varint编码。
实际数字的表示如下图所示:
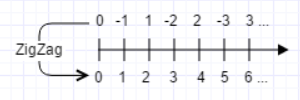
Wire Type = 1& 5时的序列化
编码后的数据具备固定大小 = 64位(8字节) / 32位(4字节),都是高位在后,低位在前,采用t-v方式存储。
Wire Type = 2时的序列化
对length使用varint方式编码,对于value值为string类型的使用utf-8方式编码。对于value值为message类型的再根据message的类型进行选择。
message为嵌套类型时,根据嵌套的类型应该用上述的类型序列化都可以解决。
message为repeat类型时不带packed=true,会导致Tag的冗余,即相同的Tag存储多次。
使用建议
根据上面的序列化原理分析,我总结出以下Protocol Buffer的使用建议
-
建议1:多用
optional或repeated修饰符
因为若optional或repeated字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不需要进行编码相应的字段在解码时才会被设置为默认值
-
建议2:字段标识号(
Field_Number)尽量只使用 1-15,且不要跳动使用
因为Tag里的Field_Number是需要占字节空间的。如果Field_Number>16时,Field_Number的编码就会占用2个字节,那么Tag在编码时也就会占用更多的字节;如果将字段标识号定义为连续递增的数值,将获得更好的编码和解码性能 -
建议3:若需要使用的字段值出现负数,请使用
sint32 / sint64,不要使用int32 / int64
因为采用sint32 / sint64数据类型表示负数时,会先采用Zigzag编码再采用Varint编码,从而更加有效压缩数据 -
建议4:对于
repeated字段,尽量增加packed=true修饰
因为加了packed=true修饰repeated字段采用连续数据存储方式,即T - L - V - V -V方式
序列化 & 反序列化过程
序列化过程如下:
1. 判断每个字段是否有设置值,有值才进行编码
2. 根据 字段标识号&数据类型 将 字段值 通过不同的编码方式进行编码
反序列化过程如下:
1. 调用 消息类的 parseFrom(input) 解析从输入流读入的二进制字节数据流
2. 将解析出来的数据 按照指定的格式读取到 Java、C++、Phyton 对应的结构类型中
由于:
a. 编解码方式简单(只需要简单的数学运算 = 位移等等)
b. 采用 Protocol Buffer 自身的框架代码 和 编译器 共同完成
所以Protocol Buffer的序列化和反序列化速度非常快。