2017.3.7
第四章《朴素贝叶斯分类器》
思维导图

1:简单概念描述
概念比较简单,这里我摘抄自百度百科,很容易理解。
朴素贝叶斯模型(NaiveBayesian classification)):
Vmap=arg max P( Vj | a1,a2...an)
Vj属于V集合
其中Vmap是给定一个example,得到的最可能的目标值.
其中a1...an是这个example里面的属性.
这里面,Vmap目标值,就是后面计算得出的概率最大的一个.所以用max来表示
贝叶斯公式应用到 P(Vj | a1,a2…an)中.
可得到Vmap= arg max P(a1,a2…an | Vj ) P( Vj ) / P (a1,a2…an)
又因为朴素贝叶斯分类器默认a1…an他们互相独立的.
所以P(a1,a2…an)对于结果没有用处. [因为所有的概率都要除同一个东西之后再比较大小,最后结果也似乎影响不大]
可得到Vmap=arg max P(a1,a2…an | Vj ) P( Vj )
然后
"朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。换言之。该假定说明给定实例的目标值情况下。观察到联合的a1,a2…an的概率正好是对每个单独属性的概率乘积: P(a1,a2…an | Vj ) =Πi P( ai| Vj )
…
朴素贝叶斯分类器:Vnb=arg max P( Vj ) Π i P ( ai | Vj )
其中a1,a2…an为特征值,Vj为分类的结果。这也体现了贝叶斯决策理论的核心思想,即选择具有最高概率的决策。它是文档分类的常用算法。
2:Python代码的实现—过滤网站恶意留言
情景描述:

(1) 词表到词向量的转换函数
from numpy import *
1. #过滤网站的恶意留言
2. # 创建一个实验样本
3. def loadDataSet():
4. postingList = [['my','dog','has','flea','problems','help','please'],
5. ['maybe','not','take','him','to','dog','park','stupid'],
6. ['my','dalmation','is','so','cute','I','love','him'],
7. ['stop','posting','stupid','worthless','garbage'],
8. ['mr','licks','ate','my','steak','how','to','stop','him'],
9. ['quit','buying','worthless','dog','food','stupid']]
10. classVec = [0,1,0,1,0,1]
11. return postingList, classVec
12.
13. # 创建一个包含在所有文档中出现的不重复词的列表
14. def createVocabList(dataSet):
15. vocabSet = set([]) #创建一个空集
16. for document in dataSet:
17. vocabSet = vocabSet | set(document) #创建两个集合的并集
18. return list(vocabSet)
19.
20. #将文档词条转换成词向量
21. def setOfWords2Vec(vocabList, inputSet):
22. returnVec = [0]*len(vocabList) #创建一个其中所含元素都为0的向量
23. for word in inputSet:
24. if word in vocabList:
25. #returnVec[vocabList.index(word)] = 1 #index函数在字符串里找到字符第一次出现的位置 词集模型
26. returnVec[vocabList.index(word)] += 1 #文档的词袋模型 每个单词可以出现多次
27. else: print "the word: %s is not in my Vocabulary!" % word
28. return returnVec

(2) 从词向量计算概率
1. #朴素贝叶斯分类器训练函数 从词向量计算概率
2. def trainNB0(trainMatrix, trainCategory):
3. numTrainDocs = len(trainMatrix)
4. numWords = len(trainMatrix[0])
5. pAbusive = sum(trainCategory)/float(numTrainDocs)
6. # p0Num = zeros(numWords); p1Num = zeros(numWords)
7. #p0Denom = 0.0; p1Denom = 0.0
8. p0Num = ones(numWords); p1Num = ones(numWords) #避免一个概率值为0,最后的乘积也为0
9. p0Denom = 2.0; p1Denom = 2.0
10. for i in range(numTrainDocs):
11. if trainCategory[i] == 1:
12. p1Num += trainMatrix[i]
13. p1Denom += sum(trainMatrix[i])
14. else:
15. p0Num += trainMatrix[i]
16. p0Denom += sum(trainMatrix[i])
17. # p1Vect = p1Num / p1Denom
18. #p0Vect = p0Num / p0Denom
19. p1Vect = log(p1Num / p1Denom)
20. p0Vect = log(p0Num / p0Denom) #避免下溢出或者浮点数舍入导致的错误 下溢出是由太多很小的数相乘得到的
21. return p0Vect, p1Vect, pAbusive

(3) 根据现实情况修改分类器
1. #朴素贝叶斯分类器
2. def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
3. p1 = sum(vec2Classify*p1Vec) + log(pClass1)
4. p0 = sum(vec2Classify*p0Vec) + log(1.0-pClass1)
5. if p1 > p0:
6. return 1
7. else: return 0
8.
9. def testingNB():
10. listOPosts, listClasses = loadDataSet()
11. myVocabList = createVocabList(listOPosts)
12. trainMat = []
13. for postinDoc in listOPosts:
14. trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
15. p0V, p1V, pAb = trainNB0(array(trainMat), array(listClasses))
16. testEntry = ['love','my','dalmation']
17. thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
18. print testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb)
19. testEntry = ['stupid','garbage']
20. thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
21. print testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb)
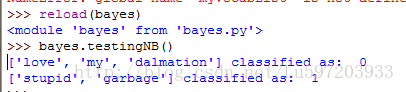
注意:主要从以下两点对分类器进行修改
<1>贝叶斯概率需要计算多个概率的乘积以获得文档属于某个类别的概率,即计算p(w0|1)p(w1|1)p(w2|1)。如果其中一个概率值为0,那么最后的乘积也为0
<2>第二个问题就是下溢出,这是由于太多过小的数相乘造成的。由于大部分因子都非常小,所以程序会下溢出或者得不到正确的答案。解决办法是对乘积取自然对数这样可以避免下溢出或者浮点数舍入导致的错误。
<3>每个单词的出现与否作为一个特征,被称为词集模型;在词袋模型中,每个单词可以出现多次。
3:案例—过滤垃圾电子邮件
1. #过滤垃圾邮件
2. def textParse(bigString): #正则表达式进行文本解析
3. import re
4. listOfTokens = re.split(r'\W*',bigString)
5. return [tok.lower() for tok in listOfTokens if len(tok) > 2]
6.
7. def spamTest():
8. docList = []; classList = []; fullText = []
9. for i in range(1,26): #导入并解析文本文件
10. wordList = textParse(open('email/spam/%d.txt' % i).read())
11. docList.append(wordList)
12. fullText.extend(wordList)
13. classList.append(1)
14. wordList = textParse(open('email/ham/%d.txt' % i).read())
15. docList.append(wordList)
16. fullText.extend(wordList)
17. classList.append(0)
18. vocabList = createVocabList(docList)
19. trainingSet = range(50);testSet = []
20. for i in range(10): #随机构建训练集
21. randIndex = int(random.uniform(0,len(trainingSet)))
22. testSet.append(trainingSet[randIndex])
23. del(trainingSet[randIndex])
24. trainMat = []; trainClasses = []
25. for docIndex in trainingSet:
26. trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
27. trainClasses.append(classList[docIndex])
28. p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses))
29. errorCount = 0
30. for docIndex in testSet: #对测试集进行分类
31. wordVector = setOfWords2Vec(vocabList, docList[docIndex])
32. if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
33. errorCount += 1
34. print 'the error rate is: ', float(errorCount)/len(testSet)
注意:这里训练测试的方法是从总的数据集中随机选择数字,将其添加到测试集中,同时将其从训练集中剔除。这种随机选择数据的一部分作为训练集,而剩余部分作为测试集的过程为留存交叉验证(hold-out cross validation)。有时为了更精确地估计分类器的错误率,就应该进行多次迭代后求出平均错误率。