SiamFC:基于全卷积孪生网络的目标跟踪算法
其他
2018-12-13 09:10:56
阅读次数: 0
本论文提出一种新的全卷积孪生网络作为基本的跟踪算法,这个网络在ILSVRC15的目标跟踪视频数据集上进行端到端的训练。我们的跟踪器在帧率上超过了实时性要求,尽管它非常简单,但在多个benchmark上达到最优的性能。
最近很多研究通过使用预训练模型来解决上述问题。这些方法中,要么使用网络内部某一层作为特征的shallow方法(如相关滤波);要么是使用SGD方法来对多层网络进行微调。然而shallow的方法没有充分利用端到端学习的益处,而使用SGD微调虽然能到达时最优结果,但却难以达到实时性的要求。
我们提出另一种替代性的方法。这个方法在初始离线阶段把深度卷积网络看成一个更通用的相似性学习问题,然后在跟踪时对这个问题进行在线的简单估计。这篇论文的关键贡献就在于证明这个方法在benchmark上可以达到非常有竞争性的性能,并且运行时的帧率远超实时性的要求。具体点讲,我们训练了一个孪生网络在一个较大的搜索区域搜索样本图片。本文另一个贡献在于,新的孪生网络结构是一个关于搜索区域的全卷积网络:密集高效的滑动窗口估计可通过计算两个输入的互相关性并插值得到。
跟踪任意目标的学习可看成是相似性问题的学习。我们提出学习一个函数
f
(
x
,
z
)
f(x,z)
f ( x , z )
z
z
z
x
x
x
我们用深度神经网络来模拟函数
f
f
f
z
z
z
x
x
x
φ
\varphi
φ
g
g
g
(1)
f
(
z
,
x
)
=
g
(
φ
(
z
)
,
φ
(
x
)
)
f(z,x)=g(\varphi(z),\varphi(x)) \tag{1}
f ( z , x ) = g ( φ ( z ) , φ ( x ) ) ( 1 )
g
g
g
φ
\varphi
φ
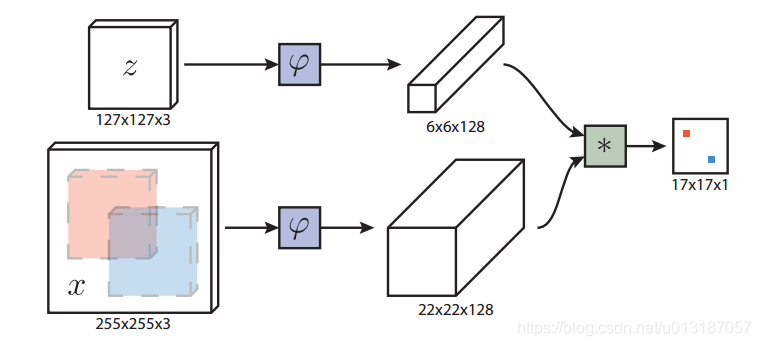
网络结构如下图所示
z
z
z
x
x
x
全卷积网络的优点是待搜索图像不需要与样本图像具有相同尺寸,可以为网络提供更大的搜索图像作为输入,然后在密集网格上计算所有平移窗口的相似度。本文的相似度函数使用互相关,公式如下
(2)
f
(
z
,
x
)
=
φ
(
z
)
∗
φ
(
x
)
+
b
1
f(z,x)=\varphi(z) * \varphi(x) + b\mathcal 1 \tag{2}
f ( z , x ) = φ ( z ) ∗ φ ( x ) + b 1 ( 2 )
b
1
b\mathcal 1
b 1
φ
(
z
)
\varphi(z)
φ ( z )
φ
(
x
)
\varphi(x)
φ ( x )
跟踪时以上一帧目标位置为中心的搜索图像来计算响应得分图,将得分最大的位置乘以步长即可得到当前目标的位置。
我们用判别方法来对正、负样本对进行训练,其逻辑损失定义如下:
(3)
l
(
y
,
v
)
=
l
o
g
(
1
+
e
x
p
(
−
y
v
)
)
\mathcal l(y,v)=log(1+exp(-yv))\tag{3}
l ( y , v ) = l o g ( 1 + e x p ( − y v ) ) ( 3 )
y
∈
(
+
1
,
−
1
)
y\in(+1,-1)
y ∈ ( + 1 , − 1 )
v
v
v
1
1
+
e
−
v
\frac{1}{1+e^{-v}}
1 + e − v 1
1
−
1
1
+
e
−
v
1-\frac{1}{1+e^{-v}}
1 − 1 + e − v 1
(
3
)
(3)
( 3 )
训练时采用所有候选位置的平均loss来表示,公式如下:
(4)
L
(
y
,
v
)
=
1
D
∑
u
∈
D
l
(
y
[
u
]
,
v
[
u
]
)
L(y,v)=\frac{1}{\mathcal D}\sum_{u\in \mathcal D}\mathcal l(y[u],v[u])\tag{4}
L ( y , v ) = D 1 u ∈ D ∑ l ( y [ u ] , v [ u ] ) ( 4 )
D
\mathcal D
D
u
u
u
训练的卷积参数
θ
\theta
θ
(5)
a
r
g
m
i
n
θ
=
E
(
z
,
x
,
y
)
L
(
y
,
f
(
z
,
x
;
θ
)
)
arg\ \underset {\theta}{min}=\underset {(z,x,y)}{E}\ L(y,f(z,x;\theta))\tag{5}
a r g θ m i n = ( z , x , y ) E L ( y , f ( z , x ; θ ) ) ( 5 )
训练样本对
(
z
,
x
)
(z,x)
( z , x )
x
x
x
z
z
z
网络输出正负样本的确定:在输入搜索图像上(如
255
∗
255
255*255
2 5 5 ∗ 2 5 5
(6)
y
[
u
]
=
{
+
1
i
f
k
∣
∣
u
−
c
∣
∣
≤
R
−
1
o
t
h
e
r
w
i
s
e
.
y[u]=\left\{\begin{matrix} & +1\quad if\ k||u-c||\leq R\\ &-1\qquad otherwise\quad . \end{matrix}\right.\tag{6}
y [ u ] = { + 1 i f k ∣ ∣ u − c ∣ ∣ ≤ R − 1 o t h e r w i s e . ( 6 )
k
k
k
c
c
c
u
u
u
R
R
R
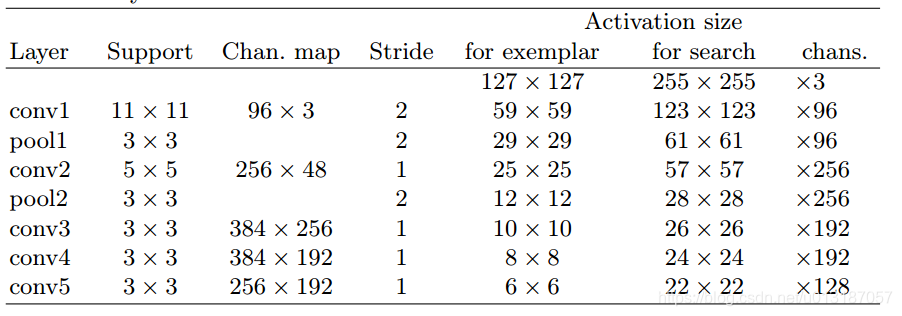
Dataset curation
127
×
127
127\times 127
1 2 7 × 1 2 7
255
×
255
255\times255
2 5 5 × 2 5 5
s
(
w
+
2
p
)
×
s
(
h
+
2
p
)
=
A
s(w+2p)\times s(h+2p)=A
s ( w + 2 p ) × s ( h + 2 p ) = A Network architecture
Training
1
0
−
2
10^{-2}
1 0 − 2
1
0
−
8
10^{-8}
1 0 − 8
Tracking
φ
(
z
)
\varphi(z)
φ ( z )
17
×
17
17 \times 17
1 7 × 1 7
272
×
272
272 \times 272
2 7 2 × 2 7 2
1.02
5
{
−
2
,
−
1
,
0
,
1
,
2
}
1.025^{\left\{-2,-1,0,1,2\right\}}
1 . 0 2 5 { − 2 , − 1 , 0 , 1 , 2 }
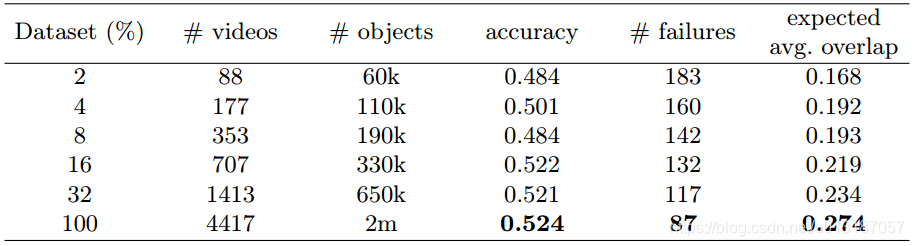
Dataset size
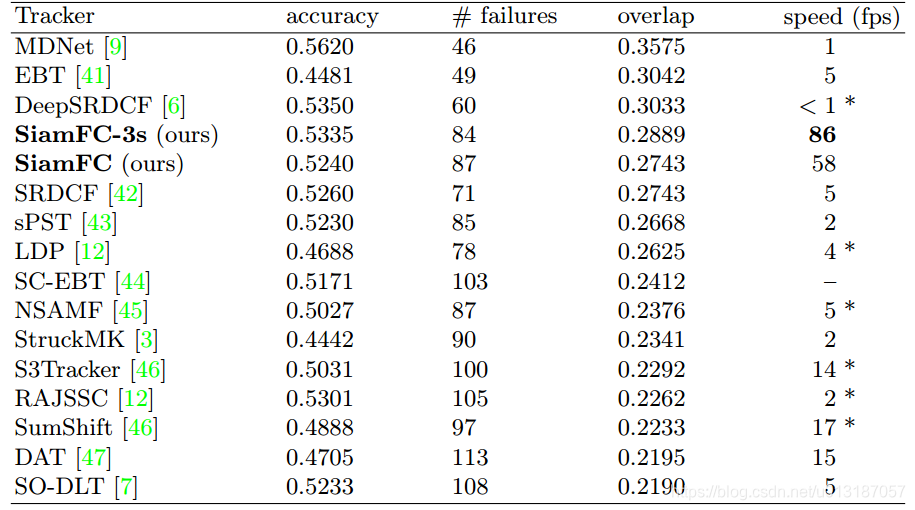
VOT 2015
转载自 blog.csdn.net/u013187057/article/details/84893307