.修改linux ip
可以命令修改:vim /etc/sysconfig/network-scripts/ifcfg-eth0 最后这参数是不确定的
然后如下 将ONBOOT 改为yes 然后重启 reboot
![]()
修改主机名
hostname # 查看
vi /etc/sysconfig/network # 编辑network文件修改hostname行(重启生效)
cat /etc/sysconfig/network # 检查修改
NETWORKING=yes
HOSTNAME=centos66.magedu.com
7: hostnamectl set-hostname wozuishuai # 使用这个命令会立即生效且重启也生效修改主机名与 ip 对应关系
vi /etc/hosts
配置如下
![]()
以上操作如有问题,请自行百度

查看防护墙状态
service iptables status
关闭
service iptables stop
查看防火墙开机启动状态
chkconfig iptables --list
关闭开机启动
chkconfig iptables off
我的是Centos7,以下关闭方法是7的
查看防火墙状态
firewall-cmd --state停止firewall
systemctl stop firewalld.service禁止firewall开机启动
systemctl disable firewalld.service 下载地址: https://hadoop.apache.org/releases.html

下载完成,传到linux上
解压
tar -zxvf hadoop-2.8.5.tar.gz 直接解压到当前
tar -zxvf hadoop-2.8.5.tar.gz -c /usr/src/java -c 后面接位置 是表示解压到指定位置解压完,删除压缩包
![]()
若嫌文件夹名字太长,可执行
![]()
修改好之后进入:
![]()
删除里面的doc文档,也可以不删除
进入到下图目录,修改配置
![]()
第一个给下图文件写入JAVA_HOME
![]()
编辑此文件
![]()
找到下图位置
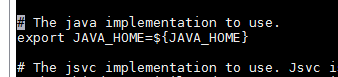
修改成本地路径
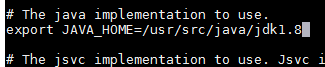
第二个修改
![]()
编辑文件
![]()
找到此位置

添加内容如下
<!-- 用来指定hdfs的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://wozuisuai:9000/</value>
</property>
<!-- 用来指定Hadoop运行时产生文件的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/src/java/hadoop/tmp</value>
</property>hdfs:// 应该是规定 wozuisuai 这个是主机名 ![]() 9000 貌似是默认的直接写上就行 这里我也不是很清楚
9000 貌似是默认的直接写上就行 这里我也不是很清楚
![]() 这一块的路径自己决定
这一块的路径自己决定
主机名问题的话可以百度,能够修改
第三个修改
![]()
编辑文件
![]()
在此位置

添加如下内容
<!-- 指定HDFS保存数据副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
value 那块最好是3 我的就一个虚拟机 所以写的 1
第四个修改
将下图改名
![]()
运行指令,并改名为 mapred-site.xml 因为template文件hadoop不读
![]()
改好之后进入文件
![]()
在此位置
添加内容
<!-- 告诉hadoop以后mapr在那个资源调度集群上去跑 --> ps: 我也不知道这是啥玩意
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>第五个修改
![]()
进入文件
![]()
此位置

添加内容
<!-- 指定YARN的老大(resourcemanager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>wozuishuai</value> //此位置是主机名
</property>
<!-- NodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>修改完成
将hadoop配置到环境变量
进入环境变量编辑
vi /etc/profile
配置环境变量
export HADOOP_HOME=/itcast/hadoop-2.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin //hadoop_home直接加在path的后面保存好以后:刷新配置
source /etc/profile
初始化HDFS
#hadoop namenode -format(过时)
hdfs namenode -format

看到这货就成功了
进行启动
进入到hadoop下的sbin文件内
先启动 ![]()
执行 :start-dfs.sh
启动成功 通过指令jps查看进程
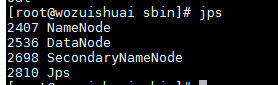
在启动 ![]()
执行 start-yarn.sh
启动成功 通过指令jps查看进程

可以在windows平台下,使用浏览器进行查看,是否搭建成功
http://192.168.184.128:50070 ( hdfs管理界面) 端口号默认50070

http://192.168.8.88:8088 (yarn管理界面)

测试hdfs(主要存储数据,存储海量数据)
上传文件指令 我放在根目录下 /
![]()
下载文件
![]()
测试MapReduce 进入到hadoop文件下的mapreduce下
![]()
我运行的是
![]()
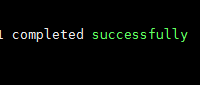
运行指令 测试圆周率
![]()
结果有它就行了
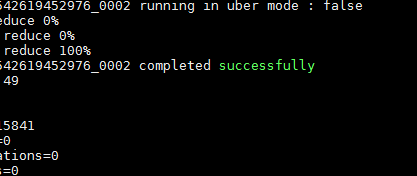
在这里,测试一下单词统计(输入与输出,都存放在hdfs,因为可能文件很大)
新建一个test.txt文件
hello tom
hello jerry
hello kitty
hello world
hello tom

前两部创建文件夹,第三部放值 路径 / 为hdfs的根路径简写
运行此命令测试统计 最后两个路径为文件所在 与结果存放 结果存放可以自动生成
![]()
结果
查看结果可以去
然后找你所设置的文件下载就能看了 也可以输入指令 不过我没试,想试的话可以去百度
在这个文件中添加linux主机名和IP的映射关系
c:\Windows\System32\drivers\etc
在末尾,添加
192.168.184.128 wozuishuai
访问的话就可以吧ip换成主机名,我没换没什么影响
配置SSH免密码登录
(一台机器)
ssh-keygen -t rsa
执行完这个命令后,直接回车就行,生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
执行 cd ~ 在执行 cd .ssh 进入.ssh文件 ll -a 查看隐藏文件 可以看到两个秘钥
主机的.ssh文件下执行 touch authorized_keys 新建文件
修改authorized_keys的权限(权限这块我不懂,不能做过多解释)
chmod 600 authorized_keys
![]()
之后进行文件追加,执行
cat id_rsa.pub >> authorized_keys
执行cat authorized_keys

成功
测试 cd ~ 然后执行 ssh 主机名或ip
不用密码即为成功
(多台机器)
#SSH协议(让linux不同机器,启动起来。使用SSH进行控制)
ssh-keygen -t rsa
执行完这个命令后,直接回车就行,生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
执行 cd ~ 在执行 cd .ssh 进入.ssh文件 ll -a 查看隐藏文件 可以看到两个秘钥
拷贝到需要的机器上
scp id_rsa.pub 第二台主机名或ip:保存路径
然后输入要拷贝到主机的密码
然后进入到第二台主机的.ssh文件下 可以看到拷贝过去的文件
在第二台主机的.ssh文件下执行 touch authorized_keys 新建文件
修改authorized_keys的权限(权限这块我不懂,不能做过多解释)
chmod 600 authorized_keys
![]()
之后进行文件追加,执行
cat 加你传过来的id_rsa.pub文件 >> ./authorized_keys
执行cat authorized_keys 成功效果同上
测试 cd ~ 然后执行 ssh 主机名或ip
不用密码即为成功