1. model copy and deep copy
2. how to handle large memory demand when training
3. kubernetes
4. 分类问题中,数据倾斜怎么办
5. 如何确定模型精度不够是模型问题,参数问题,还是训练方法的问题???
6. 信息熵是用来确定不确定性的大小,
7.梯度消失和梯度爆炸的原因
梯度消失是指梯度在后向传播中越来越小,导致无法收敛。
梯度消失可能是使用了一些不当的激活函数,如tanh,sigmoid,会导致求梯度值很小,如果是这种情况,可以考虑换成Relu,梯度只有0和1,不会出现求不出来的情况
梯度爆炸是指梯度值很大,可以使用gradient clip的方式将梯度较大的值剔除掉
8. 为什么梯度相反的方向是梯度下降最快的方向?
9. 为什么神经网络的损失函数是非凸的?
10. resnet inception attention网络模型?
11. 什么时候选用深度学习,什么时候选用机器学习?
什么样的数据不适合深度学习:
(1)数据量较小
(2)数据集不具有局部相关性。目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并不会影响相关的结果。
12. 深度学习中为什么要引入非线性的激活函数?目前RELU, Tanh, Sigmoid 有什么缺点和不足?比较而言,哪一种更好?
如果都是线性变换,那么只是对输入做了线性变换,无法刻画一些非线性的关系。而引入非线性之后,非线性函数可以用来逼近任何函数
sigmoid中有指数运算,耗时会比较长,而且对于整体x都较大时,求导后容易出现接近0的梯度值,对数据的变化扰动不敏感,出现梯度消失,造成信息丢失,无法完成深层网络训练
relu计算量要小一些,而且会导致网络中一部分的输出为0,产生稀疏性,减少参数间的依懒性,减少过拟合。但是也有一部分的梯度会是0,无法完全解决梯度弥散问题,但是也有一些改进的方法。
具体比较见下图:
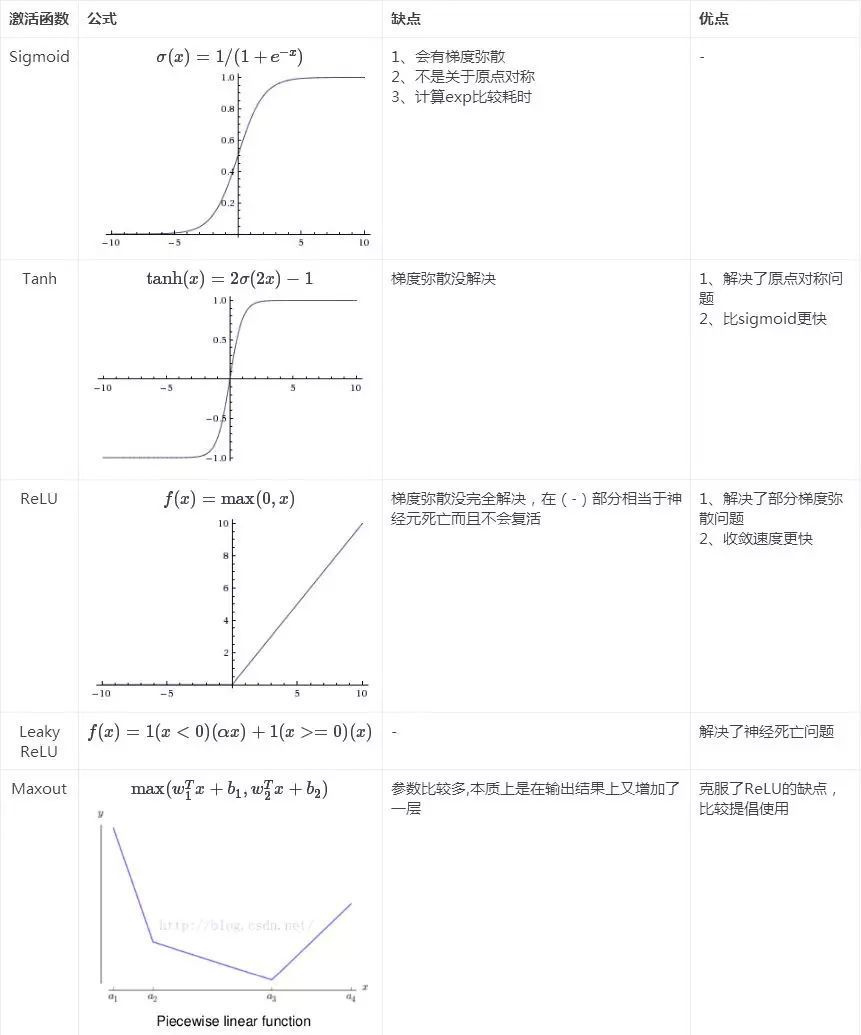
13. 为什么simpleRnn的效果不如LSTM?LSTM为什么更能防止梯度弥散,梯度爆炸问题?
14. 如果训练的时候出现NAN,可能是什么原因造成的?
15. CNN最开始是在ImageClassification中应用的,后来又用在了NLP中,甚至AlphaGo里面也用到了,这其中的关联是什么?
16.