周志华的《机器学习》一书对决策树的讲解全面且细致,本文根据该书籍作出自己的理解,如有不恰当之处,还请指出,谢谢。
一、决策树概述
参照数据结构中树的定义,树由节点与边构成。决策树便是利用树的结构进行决策。
以二分类问题为例子,银行会通过一个人的个人信息(包括有职业,年龄,收入,学历)来决策是否贷款。决策的过程使用了如下图所示的决策树:

二、构建决策树算法
决策树算法使用了分治的思想,通过递归地选择最优特征,根据该特征对训练数据集进行划分,使得各子类有一个较好的分类过程。
设数据集
属性集
参照(1)图的实例,这里的数据集 中的一个实例,
表示第
个人的个人信息(是个向量,包含有职业,年龄,收入,学历),
表示是否贷款给这个人。以根节点为例,职业可以划分成自由职业,白领,工人,那么属性集 A={自由职业,白领,工人 } ,算法用伪代码型式给出:
TreeGenerate(D,A)
生成节点node
if D中的样本全属于同一类别 C
将node标记成这个类别C的叶子节点
return
end if
if 属性集无法区分 or D中的样本再A上取值相同
将node标记成叶子节点,类别标记成D中样本最多的类
return
end if
从A中选择最优划分属性a
for a' in a
为 node 建立一个分支,D'表示样本D中在a上取值为a'的样本子集
if D'为空
将分支节点标记为叶子节点,类别标记为D中样本最多的类
return;
else
TreeGenerate(D,A\{a'}) // 这里的A\{a'},表示集合A除去a'部分
end if
end for
三、划分选择
整个决策树算法中,最关键的部分是如何从A中选择最优的划分属性。
1.信息增益
信息熵是度量样本集合纯度最常用的一种指标,设当前集合 中第
类样本所占比例为
,则
的信息熵定义为:
其中 的值越小,
的纯度越高
设属性集为 ,使用a对样本集
进行划分,则会产生
个分支节点,这样
就被划分成了
个样本子集合,记作
。由(1)式,可以计算出
相对于
信息熵,这样对于
各类别,有:
定义信息增益为:
当信息增益越大的时候,表示使用属性 进行划分所获得的纯度提升越大。因此整个优化目的为:
2.增益率
上述的信息增益算法对取值数目较多的属性有所偏好,在著名的C4.5决策树使用增益率作为最优划分属性。增益率的定义为:
其中:
上述的增益率准则对可取值数目较少的属性有所偏好,因此C4.5决策树采用了先从划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
3.基尼指数
CART决策树使用基尼指数来划分属性。定义数据集 的基尼值:
基尼值反映从数据集 中随机抽取两个样本,其类别标记不一致的概率,所以
越小,数据集
纯度越高。属性
的基尼指数定义为:
四、剪枝处理
剪枝是决策树学习算法对付“过拟合”的主要手段。决策树剪枝的基本策略有预剪枝和后剪枝
这时将之前的数据集划分成训练集(双线上部)和验证集(双线下部)


1.预剪枝
预剪枝指再决策树生成过程中,对每个节点再划分前先进行评估,若当前的划分不能带来泛化性能的提升,则停止划分,并将当前节点标记为叶子节点
基于信息增益准则,如上图所示,未采用任何划分规则时,假设将此根节点标记为叶子节点,并标记成好,因此验证集的精度为 ,若采用脐带属性作为划分准则,则验证集的精度为
,因此用脐部进行划分得以确定。之后对上图中的节点2进行预剪枝,基于凹陷得到划分后验证集的精度小于划分前的精度,因此不允划分。对于节点3划分前精度等于划分后精度,未能提升验证集精度,因此也不允予划分。节点4的样本都为同一类别,因此不必进行划分。
预剪枝基于贪心算法的思想,然而这种剪枝效果有时带来的效果并不是很好,甚至可能会陷入欠拟合的情况中。但可以节省很多的计算资源。
2.后剪枝
后剪枝是指先从训练集生成一个完整的决策树,然后自底向上对非叶子节点进行考察,若该节点对应的子树替换成叶子节点,能带来泛化性能的提升,则将该子树替换为叶子节点
以图(1)的决策树为例,自底向上,先考虑第四层。如果将节点6替换成叶子节点,那么该叶节点包含编号{7,15}的训练样本。该节点的类别标记为好瓜,此时决策树的验证集精度提高到了57.1%,因此决定剪枝。
再考虑第三层,对于节点5,若将其子树替换成叶子节点,替换后的叶子节点包含编号为{6,7,15}的训练样本。叶节点类别标记为好瓜,此时验证机的精度提高到71.4%,因此决定剪枝
同理,对节点2验证后,决定剪枝,对节点3和1,不决定剪枝。最终决策树如下图所示:
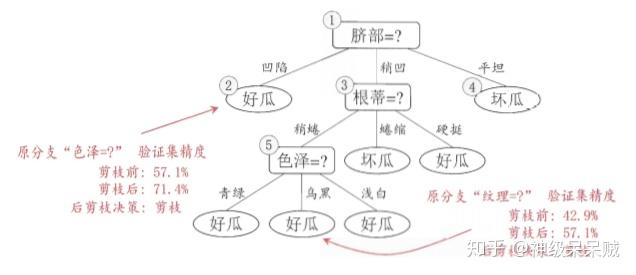
因此后剪枝决策树欠拟合风险很小,泛化性能优于预剪枝,但是后剪枝过程的时间开销较预剪枝较大。
五、连续与缺失值
1.连续值处理
上述决策树都是基于离散属性来生成决策树,现实学习任务会遇到连续属性。而处理连续属性是采用C4.5决策树算法中的二分法离散化连续值。
给定样本集和连续属性 ,设
在
上出现了n个不同的取值,就将这n个值从小到大排序,记为{
},设划分点为
,将集合
分成了子集
,如果属性
的值小于
,则划分到
中,否则划分到
中。
这里划分点 选择是根据最大信息增益的基础上选择。首先,由于
在
上有n个取值,在区间
中所取的任意值的划分结果相同,因此需要考察
个候选划分点集合。这
个候选划分集合:
由如下公式:
将候选划分集合带入上式,求解信息增益最大情况下的划分点
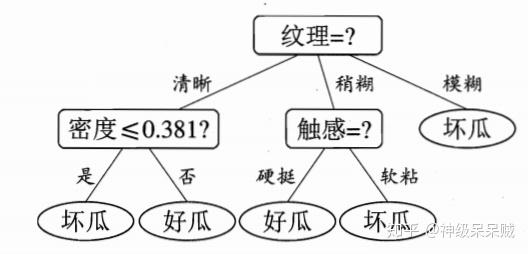
以下述训练集合为例

对密度属性来说,候选划分集合为
当划分点取0.381时,信息增益最大为0.262
同样地,对含糖率说,当划分点取0.126,此时信息增益最大为0.349
因此:
最终可以得到决策树:
2.缺失值处理

如上图数据集,某些样例的部分属性出现缺失。而处理缺失数据的过程要解决两个问题:
- 如何在属性值缺失的情况下进行划分属性选择
- 给定划分属性的情况下,若样本在该属性上的值缺失,如何对样本进行划分
对于问题一用如下的方式进行求解:
给定训练集 和属性
,令
表示
中在属性
没有缺失值的样本子集,
表示
中属于第
类的样本,定义:
无缺失值样本所占比例:
无缺失样本中第 类所占比例:
无缺失样本中第 类占无缺失样本比例:
因此可以重新定义信息增益:
这里有:
对于问题二:
如果样本在该属性上出现了缺省值,则将样本按权值划分到所有子节点上,权值计算通过:
参考文献:
周志华《机器学习》