一、频率限制
1、频率限制是做什么的
开放平台的API接口调用需要限制其频率,以节约服务器资源和避免恶意的频繁调用。
2、频率组件原理
DRF中的频率控制基本原理是基于访问次数和时间的,当然我们可以通过自己定义的方法来实现。
当我们请求进来,走到我们频率组件的时候,DRF内部会有一个字典来记录访问者的IP,
以这个访问者的IP为key,value为一个列表,存放访问者每次访问的时间,
{
IP1: [第三次访问时间,第二次访问时间,第一次访问时间],
IP2: [第三次访问时间,第二次访问时间,第一次访问时间],
}
把每次访问最新时间放入列表的最前面,记录成这样的一个数据结构
如果我们设置的是10秒内只能访问5次,
-- 1,判断访问者的IP是否在这个请求IP的字典里
-- 2,保证这个列表里都是最近10秒内的访问的时间
判断当前请求时间和列表里最早的(也就是最后的)请求时间的差值
如果差大于10秒,说明请求以及不是最近10秒内的,删除(最早的)最后一个时间,
继续判断倒数第二个,直到差值小于10秒
-- 3,判断列表的长度(即访问次数),是否大于我们设置的5次,
如果大于就限流,否则放行,并把时间放入列表的最前面。
3、自定义频率组件的使用
ps:源码自己看吧,相信你看得懂的,跟认证、权限流程差不多的
1. 自定义频率限制类 from rest_framework import throttling import time # 10秒内不能超过5次访问 class MyThrottle(throttling.BaseThrottle): VISIT_RECORD = {} def __init__(self): self.history = None def allow_request(self, request, view): # 频率限制 # 获取用户ip ip = request.META.get('REMOTE_ADDR') now = time.time() # 判断用户是否第一次访问 if ip not in self.VISIT_RECORD: self.VISIT_RECORD[ip] = [now] return True # 拿到用户的访问记录列表 history = self.VISIT_RECORD[ip] # 用于返回还有多久才能再次访问 self.history = history # 把访问的时间插入访问记录列表 history.insert(0, now) # 如果当前访问时间和最早的时间间隔超过10秒,删除最早的时间 while history and now - history[-1] > 10: history.pop() # 如果访问列表长度大于5,限制访问 if len(history) > 5: return False else: return True def wait(self): # 还有等多久才能访问 now = time.time() return self.history[-1] + 10 - now 2. 视图 class TestView(APIView): throttle_classes = [MyThrottle, ] def get(self, request): return Response("频率测试接口")
4、DRF的频率限制模块
1. DRF的频率限制模块有5个类(即5种限制方式) 2. SimpleRateThrottle # 从源码中可以指定频率限制类必须要有allow_request和wait方法 # 注意在SimpleRateThrottle类里面已经有allow_request和wait方法 # 但是allow_request方法,还需要你重写一些额外的方法和属性 from rest_framework import throttling # 1分钟内不能超过5次 class MyVisit(throttling.SimpleRateThrottle): scope = "MV" def get_cache_key(self, request, view): # 这个方法的返回值应该是ip地址 return request.META.get('REMOTE_ADDR') 还必须要配置一些设置settings REST_FRAMEWORK = { # 频率限制的配置 "DEFAULT_THROTTLE_RATES": { 'MV': '5/m', # 速率配置每分钟不能超过5次访问,MV是scope定义的值, } } 3. 其他 限制匿名用户 AnonRateThrottle VISIT_RECORD那个大字典的键:登录用户用主键,没有登录的用户用IP地址 UserRateThrottle 自己看。。 ScopedRateThrottle
二、DRF之分页
1、介绍
DRF的自带的分页器几乎能满足我们对分页的要求了,所以这里分页我们就直接使用DRF的分页,
用自定义的类继承DRF的分页类,然后重写一些我们需要的参数就好了。
2、PageNumberPagination分页类
0. 简介 看第n页,每页显示默认设置的数据数量 --> http://127.0.0.1:8000/book/?page=1 看第n页,每页显示n条数据 --> http://127.0.0.1:8000/book/?page=2&size=4 1. 分页类 class MyPagination(pagination.PageNumberPagination): # 每页显示的数量 page_size = 2 # 每页显示的最大数量 max_page_size = 5 # 搜索的参数关键字,即 ? page_query_param = 'page' # 控制每页显示数量的关键字 page_size_query_param = 'size' 2. 在自定义视图中使用分页 class BookView(APIView): def get(self, request): queryset = Book.objects.all() # 1.实例化分页器对象 paginator = MyPagination() # 2.调用这个分页器类的分页方法,拿到分页后的数据 page_queryset = paginator.paginate_queryset(queryset, request) # 3.把分页好的数据拿去序列化 ser_obj = BookSerializer(page_queryset, many=True) # 这样返回数据,可以在浏览器输入size参数设置每页显示的数据 # return Response(ser_obj.data) # 调用分页器的get_paginated_response方法 返回带上一页下一页的数据 # 使用这个方法后不能在浏览器输入size参数设置每页显示的数据了 return paginator.get_paginated_response(ser_obj.data) 3. 在DRF的提供的视图中使用分页 class BookView(generics.GenericAPIView, mixins.ListModelMixin): queryset = Book.objects.all() serializer_class = BookSerializer # 配置分页器类 pagination_class = MyPagination def get(self, request): return self.list(request)
3、LimitOffsetPagination分页类
0. 简介 从0开始取两条数据(1、2) --> http://127.0.0.1:8000/api/pagination/book/?limit=2 从第二条数据开始取两条数据(3、4) --> http://127.0.0.1:8000/api/pagination/book/?limit=2&offset=2 1. 分页类 class MyPagination(pagination.LimitOffsetPagination): # 从哪里开始拿数据 offset_query_param = 'offset' # 拿多少条数据 limit_query_param = 'limit' # 默认拿多少条数据 default_limit = 2 # 最多拿多少条 max_limit = 5 2. 在自定义视图或者DRF提供的视图中使用分页 跟上面使用方法一致。
4、CursorPagination分页类
0. 简介 按xx的顺序(倒序)显示xx条数据 --> http://127.0.0.1:8000/api/pagination/book/ 上一页下一页是的值是随机字符串,每页显示3条数据 --> http://127.0.0.1:8000/api/pagination/book/?cursor=cD01&size=3 1. 分页类 class MyPagination(pagination.CursorPagination): cursor_query_param = 'cursor' # 每页显示的数量的搜索关键字 page_size_query_param = 'size' # 每页显示的数据数量 page_size = 3 # 每页最大显示的数据数量 max_page_size = 5 # 按id的倒序显示 ordering = '-id' 2. 在自定义视图或者DRF提供的视图中使用分页 跟上面使用方法一致。
三、解析器
1、介绍
解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己想要的数据类型的过程。
本质就是对请求体中的数据进行解析。
请求头中的Content-Type告诉我们传过来的是什么类型的数据,我们就找自己的解析器,看有没有对应的解析器。
2、Django的解析器
请求进来的时候,请求体中的数据在request.body中,说明,解析器会把解析好的数据放入request.body,
我们在视图中可以打印request的类型,就能够发现request是WSGIRequest这个类。
那我们是怎么拿到request.POST数据的?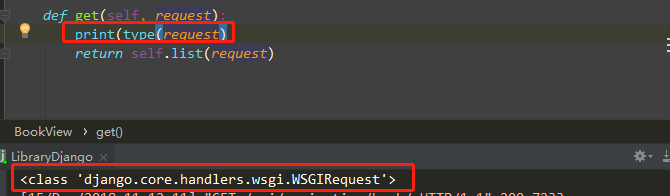

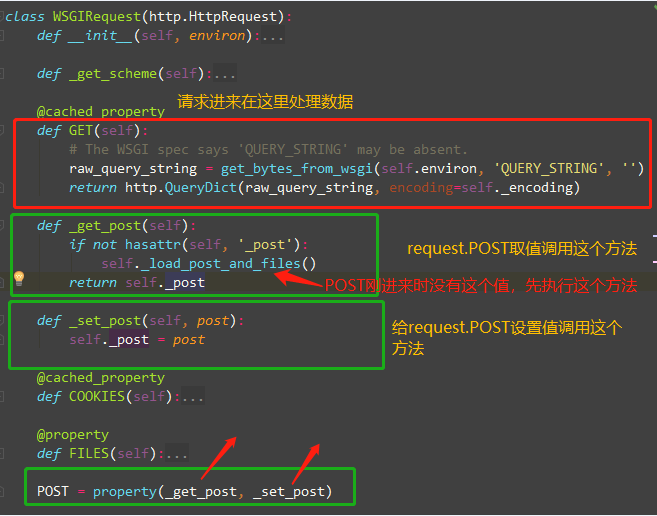

application/x-www-form-urlencoded只能上传文本格式的文件,
multipart/form-data是将文件以二进制的形式上传,这样可以实现多种类型的文件上传
一个解析到request.POST,一个解析到request.FILES中。
也就是说我们之前能在request中能到的各种数据是因为用了不同格式的数据解析器
3、DRF的解析器
在DRF框架中,解析器在request.data拿数据的时候会被调用,
也就是说DRF框架,请求数据都在request.data中,那我们看下这个Request类里的data
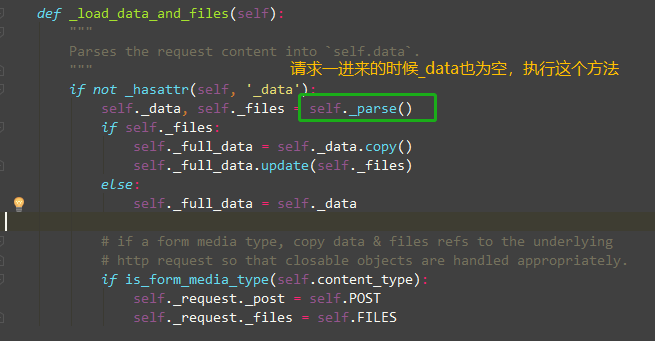
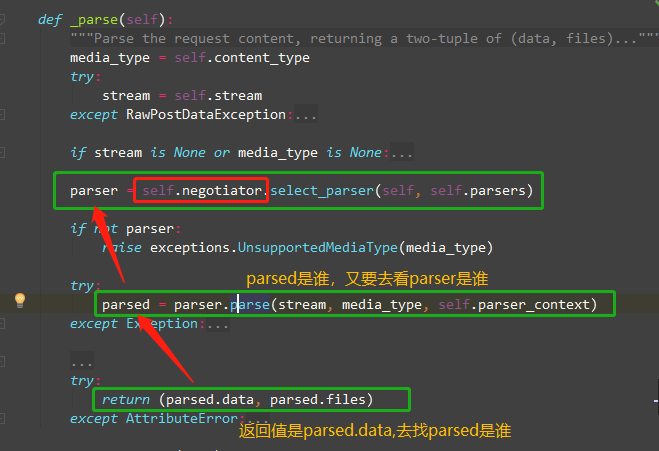

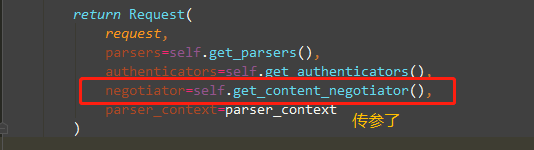
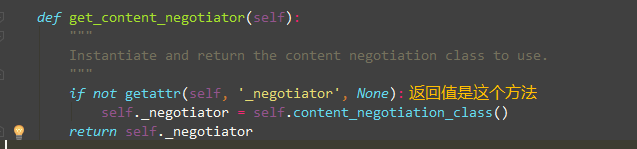
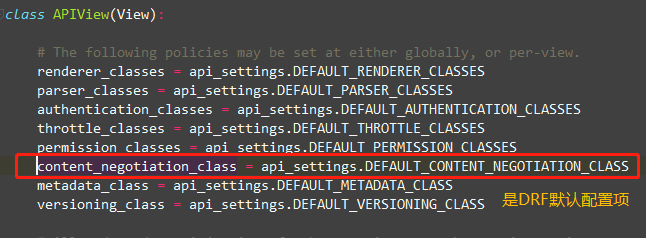
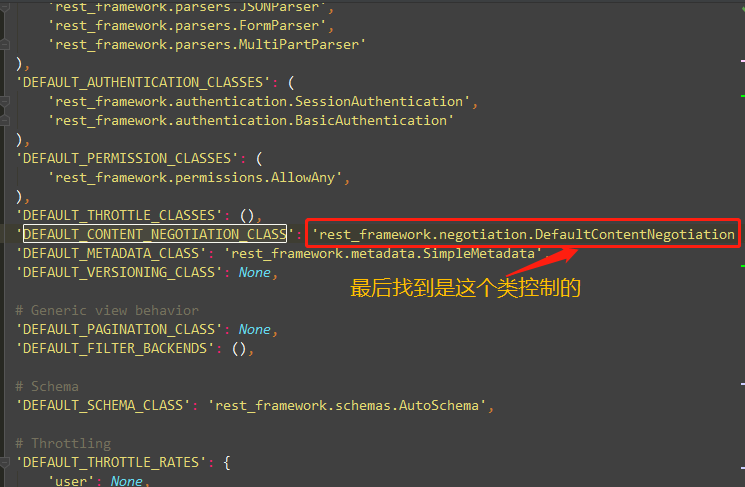




小结:
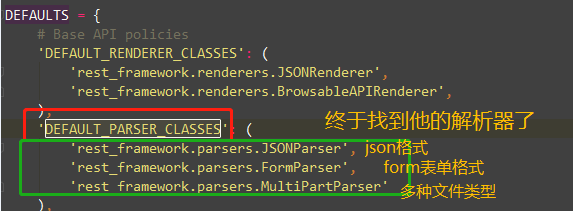
DRF解析器
'DEFAULT_PARSER_CLASSES': (
'rest_framework.parsers.JSONParser',
'rest_framework.parsers.FormParser',
'rest_framework.parsers.MultiPartParser'
)
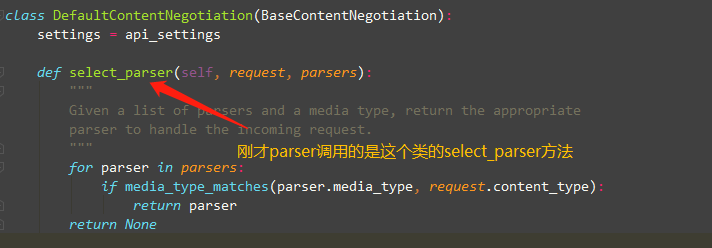
-- 原理:
拿到我们配置的所有的解析器类的实例化对象
通过ContentType跟解析器的media_type进行匹配
匹配成功把解析器类实例化对象返回
调用解析器类的parse方法去解析数据
把解析好的数据返回
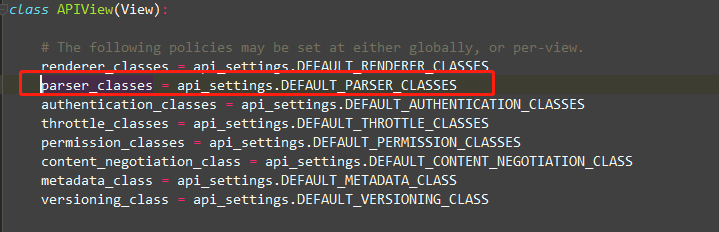
可以在我们的视图中配置视图级别的解析器
from rest_framework.parsers import JSONParser from rest_framework.parsers import FormParser from rest_framework.parsers import MultiPartParser class TestView(generics.GenericAPIView, mixins.ListModelMixin): # 如果我只配置了两个解析器,那么这个视图就只能解析这两种格式 # 不在视图配置,就默认使用全局的三种解析器 parser_classes = [JSONParser, FormParser,] def get(self, request): return self.list(request)
四、渲染器
渲染器就是把数据有格式的、友好地展示出来
DRF给我们提供的渲染器有
'DEFAULT_RENDERER_CLASSES': (
'rest_framework.renderers.JSONRenderer',
'rest_framework.renderers.BrowsableAPIRenderer',
),
我们在浏览器中展示的DRF测试的页面,就是通过浏览器的渲染器来做的
当然我们可以展示Json数据类型,渲染器比较简单