1、模型机制
tensor 代表数据,可以理解为多维数组
variable 代表变量,模型中表示定义的参数,是通过不断训练得到的值
placeholder 代表占位符,也可以理解为定义函数的参数
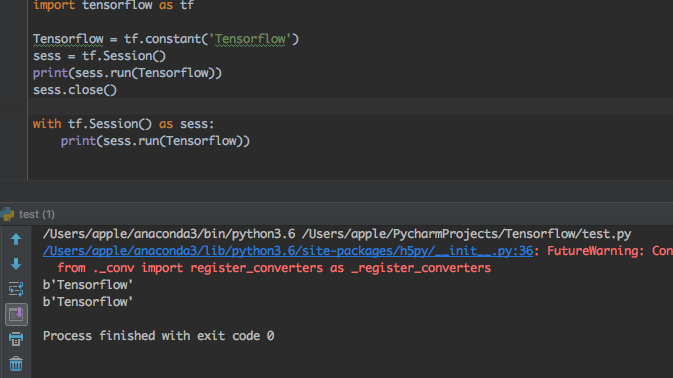
2、session 的两种使用方法(还有一种启动session的方式是sess = tf.InteractiveSession())
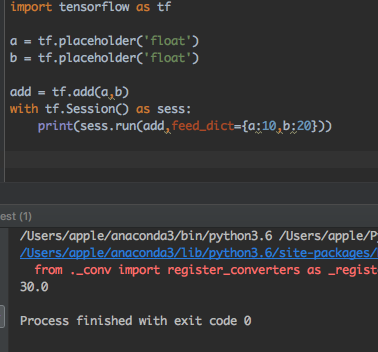
3、注入机制
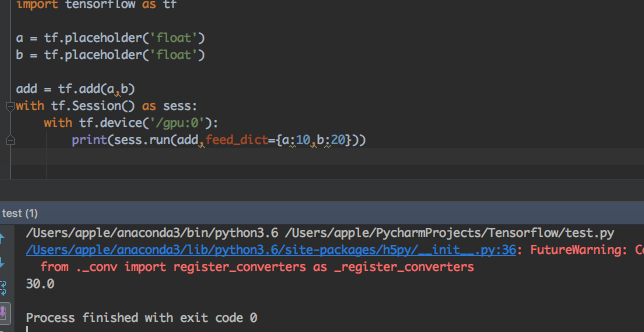
4、指定gpu运算
5、保存模型与载入模型

示例完整代码如下可直接运行:
- import tensorflow as tf
- import numpy as np
- plotdata = { "batchsize":[], "loss":[] }
- #生成模拟数据
- train_X = np.linspace(-1, 1, 100)
- train_Y = 2 * train_X + np.random.randn(*train_X.shape) * 0.3 # y=2x,但是加入了噪声
- tf.reset_default_graph() #注意需要添加一个重置图
- # 创建模型
- # 占位符
- X = tf.placeholder("float")
- Y = tf.placeholder("float")
- # 模型参数
- W = tf.Variable(tf.random_normal([1]), name="weight")
- b = tf.Variable(tf.zeros([1]), name="bias")
- # 前向结构
- z = tf.multiply(X, W)+ b
- #反向优化
- cost =tf.reduce_mean( tf.square(Y - z))
- learning_rate = 0.01
- optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #Gradient descent
- # 初始化变量
- init = tf.global_variables_initializer()
- # 训练参数
- training_epochs = 20
- display_step = 2
- saver = tf.train.Saver()
- savedir = './'
- # 启动session
- with tf.Session() as sess:
- sess.run(init)
- # Fit all training data
- for epoch in range(training_epochs):
- for (x, y) in zip(train_X, train_Y):
- sess.run(optimizer, feed_dict={X: x, Y: y})
- #显示训练中的详细信息
- if epoch % display_step == 0:
- loss = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
- print ("Epoch:", epoch+1, "cost=", loss,"W=", sess.run(W), "b=", sess.run(b))
- if not (loss == "NA" ):
- plotdata["batchsize"].append(epoch)
- plotdata["loss"].append(loss)
- print (" Finished!")
- saver.save(sess,savedir+'linemodel.cpkt') #模型保存
- print ("cost=", sess.run(cost, feed_dict={X: train_X, Y: train_Y}), "W=", sess.run(W), "b=", sess.run(b))
- #模型载入
- with tf.Session() as sess2:
- sess2.run(tf.global_variables_initializer())
- saver.restore(sess2,savedir+'linemodel.cpkt')
- print('x=0.1,z=',sess2.run(z,feed_dict={X:0.1}))
6、检查点,训练模型有时候会出现中断情况,可以将检查点保存起来
saver一个参数max_to_keep=1表明最多只保存一个检查点文件
载入时指定迭代次数load_epoch
完整代码如下:
- import tensorflow as tf
- import numpy as np
- plotdata = { "batchsize":[], "loss":[] }
- #生成模拟数据
- train_X = np.linspace(-1, 1, 100)
- train_Y = 2 * train_X + np.random.randn(*train_X.shape) * 0.3 # y=2x,但是加入了噪声
- tf.reset_default_graph() #注意需要添加一个重置图
- # 创建模型
- # 占位符
- X = tf.placeholder("float")
- Y = tf.placeholder("float")
- # 模型参数
- W = tf.Variable(tf.random_normal([1]), name="weight")
- b = tf.Variable(tf.zeros([1]), name="bias")
- # 前向结构
- z = tf.multiply(X, W)+ b
- #反向优化
- cost =tf.reduce_mean( tf.square(Y - z))
- learning_rate = 0.01
- optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #Gradient descent
- # 初始化变量
- init = tf.global_variables_initializer()
- # 训练参数
- training_epochs = 20
- display_step = 2
- saver = tf.train.Saver(max_to_keep=1) #表明最多只保存一个检查点文件
- savedir = './'
- # 启动session
- with tf.Session() as sess:
- sess.run(init)
- # Fit all training data
- for epoch in range(training_epochs):
- for (x, y) in zip(train_X, train_Y):
- sess.run(optimizer, feed_dict={X: x, Y: y})
- #显示训练中的详细信息
- if epoch % display_step == 0:
- loss = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
- print ("Epoch:", epoch+1, "cost=", loss,"W=", sess.run(W), "b=", sess.run(b))
- if not (loss == "NA" ):
- plotdata["batchsize"].append(epoch)
- plotdata["loss"].append(loss)
- saver.save(sess,savedir+'linemodel.cpkt',global_step=epoch)
- print (" Finished!")
- # saver.save(sess,savedir+'linemodel.cpkt') #模型保存
- print ("cost=", sess.run(cost, feed_dict={X: train_X, Y: train_Y}), "W=", sess.run(W), "b=", sess.run(b))
- #检查点载入
- with tf.Session() as sess2:
- load_epoch = 18
- sess2.run(tf.global_variables_initializer())
- saver.restore(sess2,savedir+'linemodel.cpkt-'+str(load_epoch))
- print('x=0.1,z=',sess2.run(z,feed_dict={X:0.1}))
模型操作常用函数
tf.train.Saver() #创建存储器Saver
tf.train.Saver.save(sess,save_path) #保存
tf.train.Saver.restore(sess,save_path) #恢复
7、可视化tensorboard
在代码中加入模型相关操作tf.summary.., 代码后面有注释,这个不理解可以当作模版,这几句代码,放在不同代码相应位置即可
代码如下:
- import tensorflow as tf
- import numpy as np
- plotdata = { "batchsize":[], "loss":[] }
- #生成模拟数据
- train_X = np.linspace(-1, 1, 100)
- train_Y = 2 * train_X + np.random.randn(*train_X.shape) * 0.3 # y=2x,但是加入了噪声
- tf.reset_default_graph() #注意需要添加一个重置图
- # 创建模型
- # 占位符
- X = tf.placeholder("float")
- Y = tf.placeholder("float")
- # 模型参数
- W = tf.Variable(tf.random_normal([1]), name="weight")
- b = tf.Variable(tf.zeros([1]), name="bias")
- # 前向结构
- z = tf.multiply(X, W)+ b
- tf.summary.histogram('z',z)#将预测值以直方图显示
- #反向优化
- cost =tf.reduce_mean( tf.square(Y - z))
- tf.summary.scalar('loss_function', cost)#将损失以标量显示
- learning_rate = 0.01
- optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #Gradient descent
- # 初始化变量
- init = tf.global_variables_initializer()
- # 训练参数
- training_epochs = 20
- display_step = 2
- # 启动session
- with tf.Session() as sess:
- sess.run(init)
- merged_summary_op = tf.summary.merge_all() # 合并所有summary
- # 创建summary_writer,用于写文件
- summary_writer = tf.summary.FileWriter('log/summaries', sess.graph)
- # Fit all training data
- for epoch in range(training_epochs):
- for (x, y) in zip(train_X, train_Y):
- sess.run(optimizer, feed_dict={X: x, Y: y})
- summary_str = sess.run(merged_summary_op, feed_dict={X: x, Y: y});
- summary_writer.add_summary(summary_str, epoch); # 将summary 写入文件
- #显示训练中的详细信息
- if epoch % display_step == 0:
- loss = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
- print ("Epoch:", epoch+1, "cost=", loss,"W=", sess.run(W), "b=", sess.run(b))
- if not (loss == "NA" ):
- plotdata["batchsize"].append(epoch)
- plotdata["loss"].append(loss)
- print (" Finished!")
- print ("cost=", sess.run(cost, feed_dict={X: train_X, Y: train_Y}), "W=", sess.run(W), "b=", sess.run(b))
之后查看tensorboard,进入summary 日志的上级路径中,输入相关命令如下图所示:
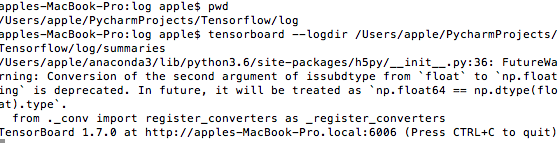
看见端口号为6006,在浏览器中输入http://127.0.0.1:6006,就会看到下面界面
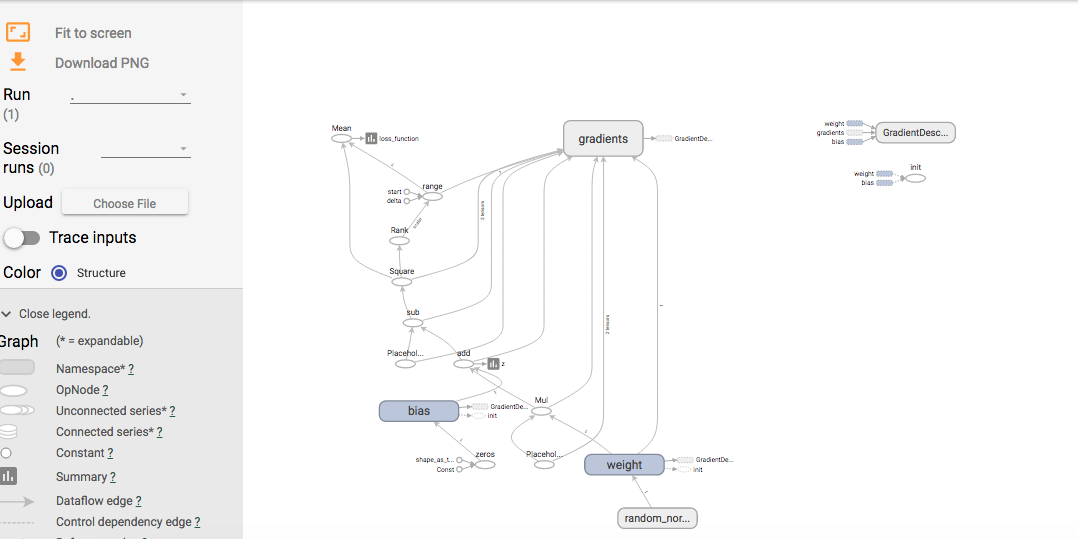
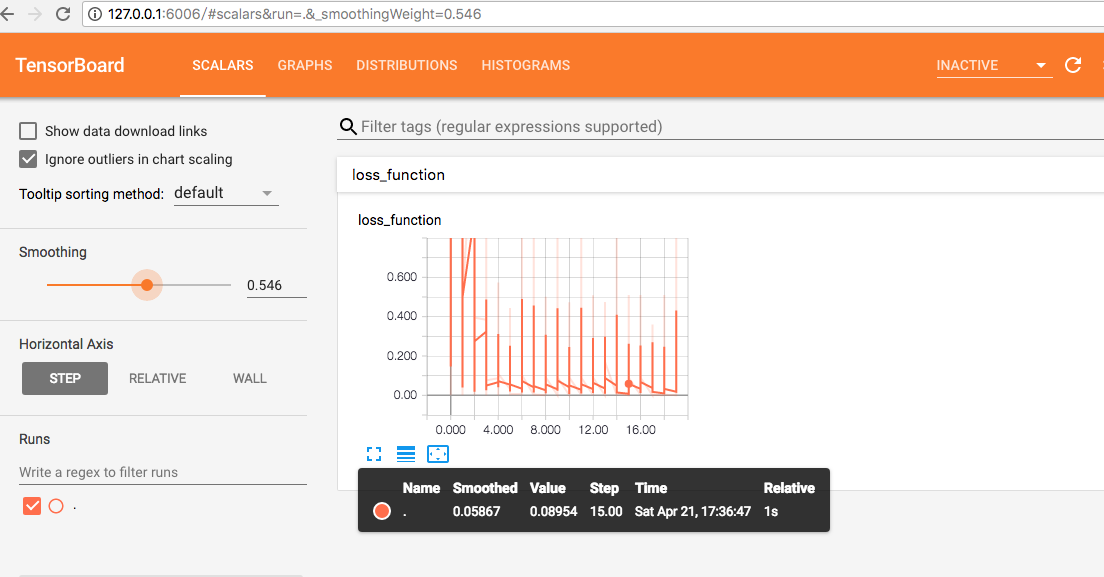
window系统下相关操作一样,进入日志文件目录,然后输入tensorboard相应的命令,在打开浏览器即可看到上图(tensorboard)