线性回归属于有监督学习,此类问题,根据带标注的信息去训练一个推断模型。该模型覆盖一个数据集,并且对不存在的新样本进行预测。该模型确定以后,构成模型的运算也就固定。在各运算过程有一些参与运算的数值,在训练过程不断更新,使模型能够学习,并对其输出进行调整。
虽然推断不同模型在运算数量和组合方式有很大的不同,但是归纳起来,主要是如下的步骤:
1、初始化模型参数
2、输入训练数据
3、在训练数据上执行推断模型
4、计算损失函数
5、调整模型参数,返回第二步
现在我们同过线性回归,了解TensorFlow的训练过程
线性回归
线性回归是用来度量变量间关系的统计技术。有意思的是该算法的实现并不复杂,但可以适用于很多情形。正是因为这些原因,我非常乐意以线性回归作为开始学习TensorFlow的开始。
请记住,不管在两个变量(简单回归)或多个变量(多元回归)情形下,线性回归都是对一个依赖变量,多个独立变量xi,一个随机值b间的关系建模。
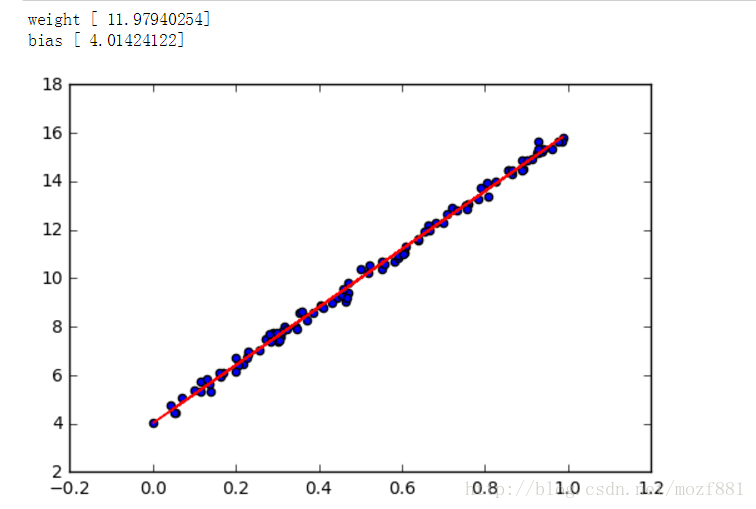
在本小节中,会创建一个简单的例子来说明TensorFlow如何假设我们的数据模型符合一个简单的线性回归y = W * x + b,为达到这个目的,首先通过简单的python代码在二维空间中生成一系列的点,然后通过TensorFlow寻找最佳拟合这些点的直线。
实现
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def createdate(datanum,sigma):
#创建datanum个随机点,数值为[0.1)之间
x_data=np.random.rand(datanum)
noise=np.random.normal(0,sigma,x_data.shape)
y_data=x_data*12+4 + noise
return x_data,y_data
def train(x_data,y_data,epoch=10000):
#构造一个线性模型
#随机生成权值和偏置
w=tf.Variable(tf.random_normal([1]))
b=tf.Variable(tf.random_normal([1]))
y=w*train_x+b
#二次代价函数
loss=tf.reduce_mean(tf.square(y_data-y))
#使用梯度下降法的优化器进行优化
optimzer=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for step in range(epoch):
sess.run(optimzer)
#if (step % 100 == 0):
# print(step,sess.run([w,b,loss]))
return sess.run(w),sess.run(b),sess.run(y)
if __name__ == "__main__":
#创建一对训练模型和一对测试模型
train_x,train_y = createdate(100,0.2)
#test_x,test_y = createdate(20,0.02)
w,b,y = train(train_x,train_y,10000)
print ("weight",w)
print ("bias",b)
#画图
plt.figure()
#散点图
plt.scatter(train_x,train_y)
#绘制线,颜色为红色,宽度为5
plt.plot(train_x,y,'r-',lw=1)
plt.show()