(1)以年龄降序为索引排列数据
import pandas as pd
import numpy as np
titanic_survival = pd.read_csv(r".......文件位置......")
new_titanic_survival = titanic_survival.sort_values(“Age”, ascending=False) #按照年龄降序排列数据
结果如下图:

(2)生成新的索引
titanic_reindexed = new_titanic_survival.reset_index(drop=Ture) #(True)删除旧的索引生成新的的索引,(False)新旧索引都存在
print(titanic_reindexed.loc[0:5]) #查看前六行
结果如下(可以与上图进行对比):

(3)自定义函数
把第100行数据返回:
def hundredth_row(column):
hundredth_item = column.loc[99]
return hundredth_item
hundredth_row = titanic_survival.apply(hundredth_row)
print(hundredth)
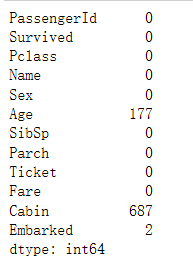
计算每一列的空行个数
def not_null_count(column):
column_null = pd.isnull(column)
null = column[column_null]
return len(null)
column_null_count = titanic_survival.apply(not_null_count)
print(column_null_count)
结果如下:
替换1,2,3为First Class,Second Class, Third Class
def which_class(row):
pclass = row['Pclass']
if pd.isnull(pclass):
return "Unknown"
elif pclass == "1":
return "First Class"
elif pclass == "2":
return "Second Class"
elif pclass == "3":
return "Third Class"
classes = titanic_survival.apply(which_class)
print(classes)
结果为:

把年龄小于18的值返回True,否则返回False
def is_minor(row):
if row["Age"] < 18:
return True
else:
return False
minors = titanic_survival.apply(is_minor, axis =1)
print(minors)
判断年龄,不存在返回“Unkonw”,小于18返回mnior,大雨18返回adult
def generate_age_lable(row):
age = row["Age"]
if pd.isnull(age):
return "Unknow"
elif age < 18:
return "minor"
else:
return "adult"
age_lables = titanic_survival.apply(generate_age_lable, axis = 1)
print(age_lables)
结果如下:

查看不同年龄段的获救比率:
titanic_survival["age_lables"] = age_lables
age_group_survival = titanic_survival.pivot_table(index = "age_lables", values = "survived")
print("age_group_survival")
结果如下:

可以看出,未成年获救的概率很高