3-1课程目录
实战环境搭建
Spark 源码编译 Spark环境搭建 Spark 简单使用
3-2 -Spark源码编译
1、下载到官网(源码编译版本)(http://spark.apache.org/downloads.html)
wget https://archive.apache.org/dist/spark/spark-2.1.0/spark-2.1.0.tgz
2、编译步骤
http://spark.apache.org/docs/latest/building-spark.html
前置要求
1)The Maven-based build is the build of reference for Apache Spark. Building Spark using Maven requires Maven 3.3.9 or newer and Java 8+. Note that support for Java 7 was removed as of Spark 2.2.0.
2) export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
mvn编译命令
./build/mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.3 -DskipTests clean package
前提:需要对maven有一定了解
./build/mvn -Pyarn -Phive -Phive-thriftserver -DskipTests clean package
spark源码编译
mvn编译 make-distribution.sh
3-3 补录:Spark源码编译中的坑
1、
./dev/make-distribution.sh --name custom-spark --pip --r --tgz -Psparkr -Phadoop-2.7 -Phive -Phive-thriftserver -Pmesos -Pyarn -Pkubernetes
建议:阿里云的机器,可能内存不足,建议使用虚拟机2-4G
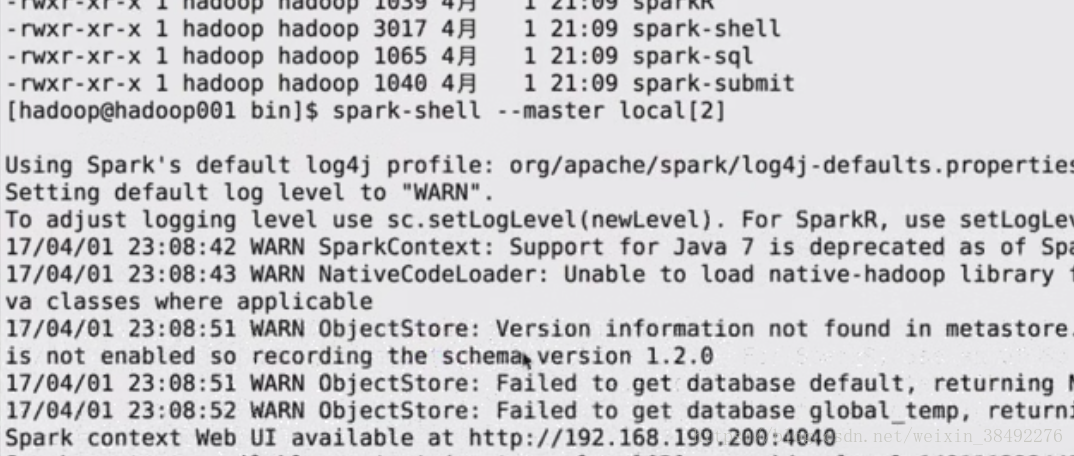
3-4 Spark Local模式环境搭建
Spark环境搭建
Local模式

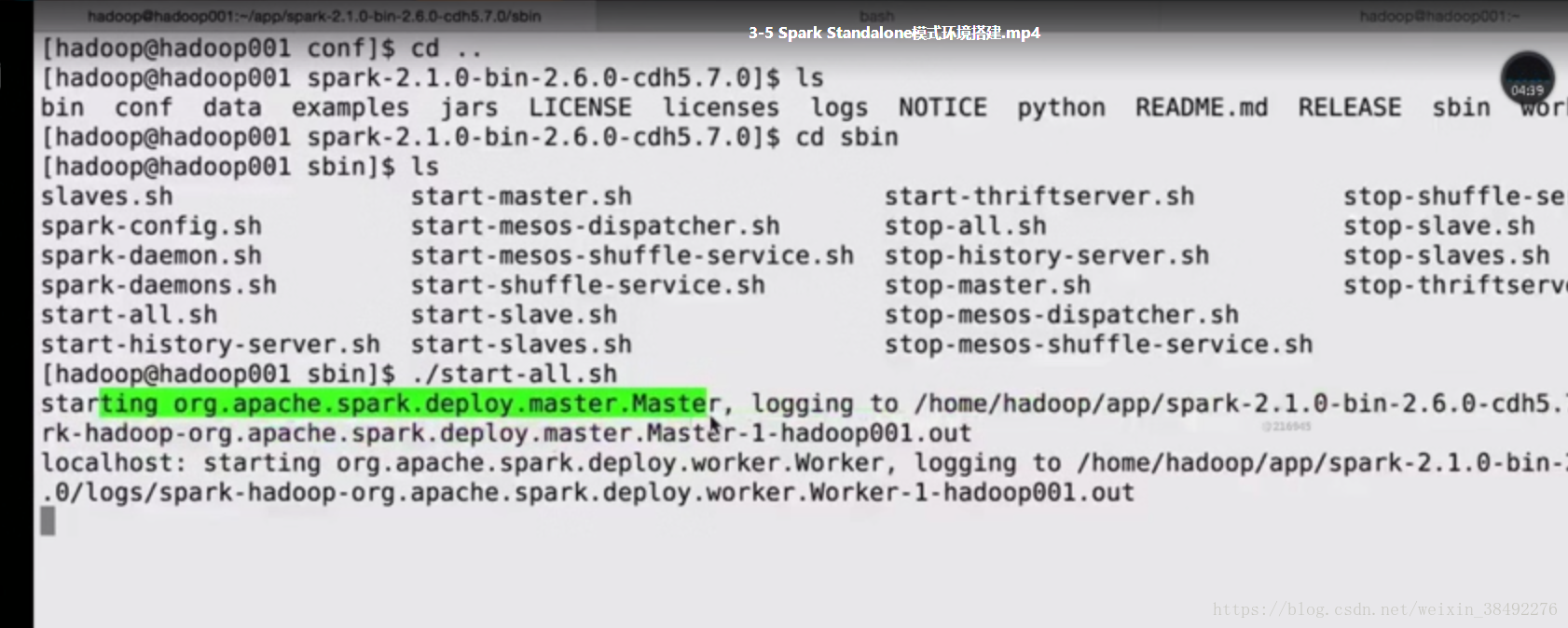
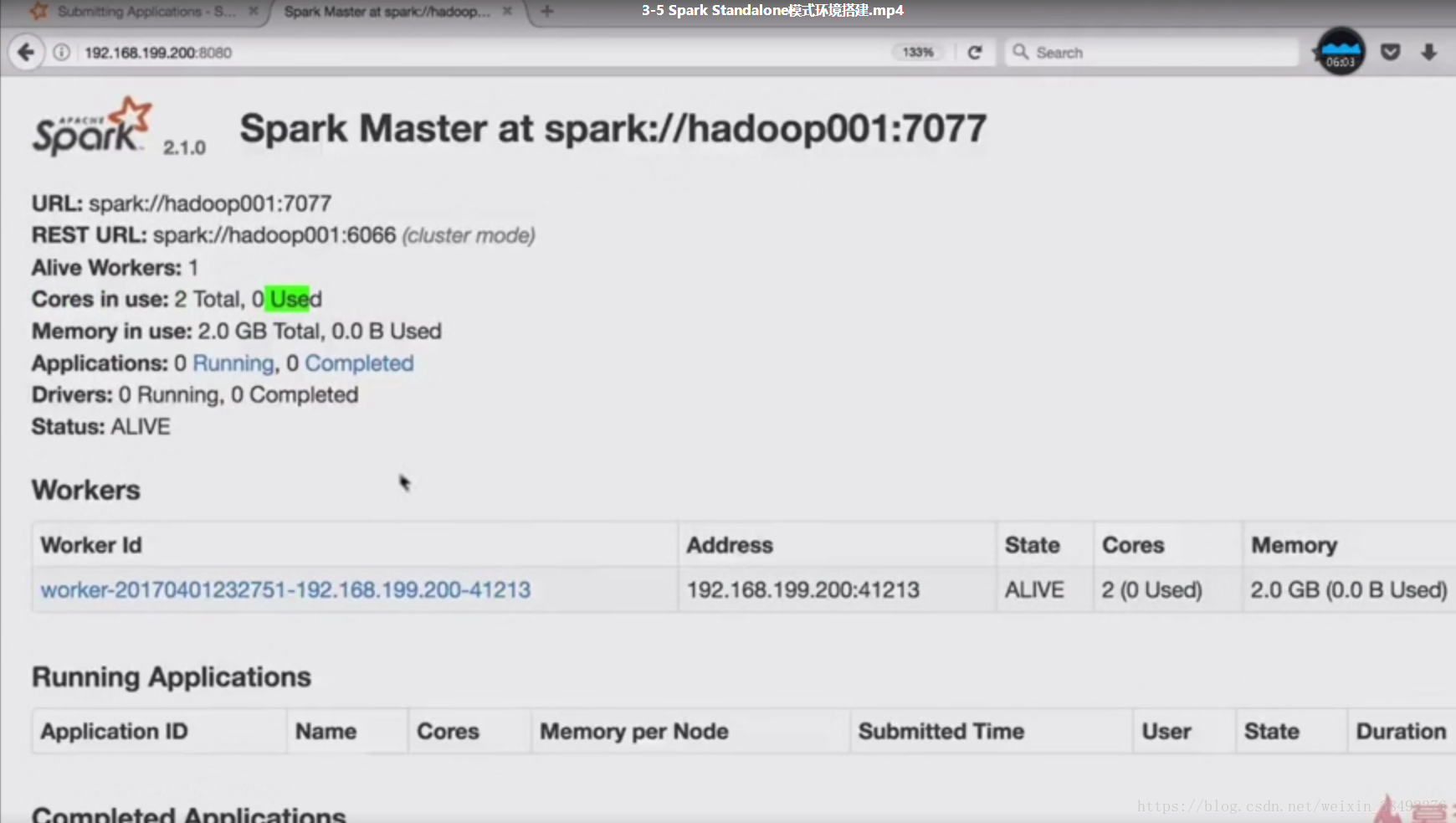
3-5 Spark Standalone模式环境搭建
Spark Standalone模式架构和hadoop 、HDFS/ YARN 和类似的
1 master+n worker
spark-env.sh

hadoop1:master
hadoop2:worker
hadoop3:worker
hadoop4:worker

3-6 Spark简单使用
Spark简单使用
使用Spark完成wordcount统计

参考文档 :
http://spark.apache.org/examples.html
Word Count
In this example, we use a few transformations to build a dataset of (String, Int) pairs called counts and then save it to a file.
val textFile = sc.textFile("hdfs://...") val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...")
代码:
val textFile = sc.textFile("file:///home/hadoop/data/wc.txt") val counts = textFile.flatMap(line => line.split(",")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.collect
在开发阶段直接用Local模式