在这篇文章中,主要介绍如何将一个机器学习的模型嵌入到web系统中,这篇文章的主要内容包括:
1、利用flask构建一个简单的web
2、将机器学习模型嵌入到web系统中
3、根据用户的反馈来更新模型
主要包括三个页面,评论提交页面、分类结果页面、感谢页面。当用户提交评论后跳转到结果页面,后台根据已有的模型来预测用户评论是属于正面评论还是负面评论,返回属于哪一种评论并且返回属于该种类的概率为多少。提供两个用户反馈结果按钮,如果用户点击正确按钮,则说明预测正确,否则预测错误,并将结果保存到SQLlite数据库中,然后再跳转到感谢页面。
一、项目结构
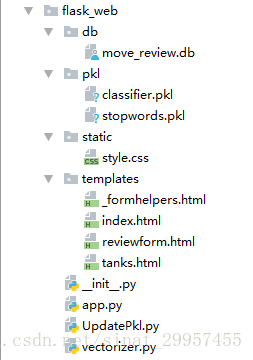
db:目录中存放SQLite数据库文件。
pkl:存放模型文件,stopwords.pk为停用词文件,classifer.pkl为模型文件。
static:为静态文件目录,主要存放js和css文件。
templates:为模板文件目录,用来存放html文件。
app.py:主要文件,包含界面跳转和模型预测等功能。
updatePkl.py:为模型更新文件。
vectorizer.py:将评论转换成为特征向量便于预测。
二、界面说明
界面做的比较简单,没有过多的去调整的样式,主要是实现功能。
1、用户提交评论界面
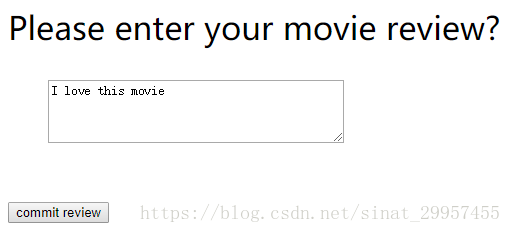
用户在这个界面可以输入自己的评论,并提交。
2、分类结果页面

用户可以通过这个页面查看自己评论的分类结果,并可以进行相应的反馈。如果,用户没有确认是否正确,SQLite数据库中将不会保存这条评论所属的类别。
3、感谢页面
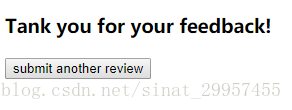
通过这个界面可以跳转到,提交评论界面。利用SQLiteStudio可以查看数据库保存评论

三、功能的实现
1、将评论转成特征向量
import re
import pickle
from sklearn.feature_extraction.text import HashingVectorizer
from nltk.stem.porter import PorterStemmer
import warnings
warnings.filterwarnings("ignore")
#加载停用词
stop = pickle.load(open("pkl/stopwords.pkl","rb"))
#删除HTML标记和标点符号,去除停用词
def tokenizer(text):
#去除HTML标记
text = re.sub("<[^>]*>","",text)
#获取所有的表情符
emoticons = re.findall('(?::|;|=)(?:-)?(?:\)|\(|D|P)', text.lower())
#删除标点符号
text = re.sub("[\W]+"," ",text.lower())+" ".join(emoticons).replace("-","")
#删除停用词
tokenized = [word for word in text.split() if word not in stop]
#提取词干
porter = PorterStemmer()
#返回去除停用词之后的单词列表
return [porter.stem(word) for word in tokenized]
#通过HashingVectorizer获取到评论的特征向量
vect = HashingVectorizer(decode_error="ignore",n_features=2**21,preprocessor=None,tokenizer=tokenizer)
2、主要功能
import pickle
import sqlite3
import numpy as np
from flask import Flask,render_template,request
from wtforms import Form,TextAreaField,validators
from flask_web.vectorizer import vect
#创建一个falsk对象
app = Flask(__name__)
#加载分类模型
clf = pickle.load(open("pkl/classifier.pkl","rb"))
#创建一个评论数据库,在app.py运行之前先运行这个方法
def create_review_db():
conn = sqlite3.connect("db/move_review.db")
c = conn.cursor()
#move_review主要包括四个字段,review_id(评论ID,主键自增)、review(评论内容)、sentiment(评论类别)、review_date(评论日期)
c.execute("CREATE TABLE move_review (review_id INTEGER PRIMARY KEY AUTOINCREMENT,review TEXT"
",sentiment INTEGER,review_date TEXT)")
conn.commit()
conn.close()
#将评论保存到数据库中
def save_review(review,label):
conn = sqlite3.connect("db/move_review.db")
c = conn.cursor()
#向数据库中插入评论
c.execute("INSERT INTO move_review (review,sentiment,review_date) VALUES "
"(?,?,DATETIME('now'))",(review,label))
conn.commit()
conn.close()
#获取评论的分类结果
def classify_review(review):
label = {0:"negative",1:"positive"}
#将评论转换成为特征向量
X = vect.transform(review)
#获取评论整数类标
Y = clf.predict(X)[0]
#获取评论的字符串类标
label_Y = label[Y]
#获取评论所属类别的概率
proba = np.max(clf.predict_proba(X))
return Y,label_Y,proba
#跳转到用户提交评论界面
@app.route("/")
def index():
#验证用户输入的文本是否有效
form = ReviewForm(request.form)
return render_template("index.html",form=form)
#跳转到评论分类结果界面
@app.route("/main",methods=["POST"])
def main():
form = ReviewForm(request.form)
if request.method == "POST" and form.validate():
#获取表单提交的评论
review_text = request.form["review"]
#获取评论的分类结果,类标、概率
Y,lable_Y,proba = classify_review([review_text])
#将概率保存2为小数并转换成为百分比的形式
proba = float("%.4f"%proba) * 100
#将分类结果返回给界面进行显示
return render_template("reviewform.html",review=review_text,Y=Y,label=lable_Y,probability=proba)
return render_template("index.html",form=form)
#用户感谢界面
@app.route("/tanks",methods=["POST"])
def tanks():
#判断用户点击的是分类正确按钮还是错误按钮
btn_value = request.form["feedback_btn"]
#获取评论
review = request.form["review"]
#获取评论所属类标
label_temp = int(request.form["Y"])
#如果正确,则类标不变
if btn_value == "Correct":
label = label_temp
else:
#如果错误,则类标相反
label = 1 - label_temp
save_review(review,label)
return render_template("tanks.html")
class ReviewForm(Form):
review = TextAreaField("",[validators.DataRequired()])
if __name__ == "__main__":
#启动服务
app.run()
3、模型更新
import pickle
import sqlite3
import numpy as np
from flask_web.vectorizer import vect
#更新模型方法,每次更新10000条评论
def update_pkl(db_path,clf,batch_size=10000):
conn = sqlite3.connect(db_path)
c = conn.cursor()
c.execute("SELECT * from review")
#获取到所有的评论
results = c.fetchmany(batch_size)
while results:
data = np.array(results)
#获取评论
X = data[:,1]
#获取
Y = int(data[:,2])
classes = np.array([0,1])
#将评论转成特征向量
x_train = vect.transform(X)
#更新模型
clf.partial_fit(x_train,Y,classes=classes)
results = c.fetchmany(batch_size)
conn.close()
return None
if __name__ == "__main__":
#加载模型
clf = pickle.load(open("pkl/classifier.pkl", "rb"))
#更新模型
update_pkl("db/move_review.db",clf)
#保存模型
pickle.dump(clf,open("pkl/classifier.pkl","wb"),protocol=4)
为什么要将更新模型用另一个文件运行,而不是在用户提交反馈之后就直接更新模型?
如果在同一时间评论的用户多的话,直接在用户提交反馈之后就更新模型,可能会造成在更新模型文件的时候会损坏模型文件。建议,在本地更新模型文件之后,再上传到服务器。