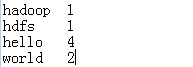版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qinshi965273101/article/details/83185306
环境:伪分布式搭建的hadoop环境
1、启动MapReduce
- 2.0版本,MR运行在yarn上,执行启动命令: sh start-yarn.sh
- 出现下图两个进程说明启动成功

2、MR初识
写MR代码,就是编写Map组件以及Reduce组件。Map组件先直接对DFS上的文件进行数据操作,得到的结果再汇总给Reduce组件进行操作,得到最终的结果。
| 例如:有以下数据,需要统计每个单词出现的次数
|
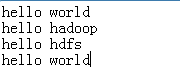
2.1、编写代码如下
package hadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//开发Mapper组件,让该类继承Mapper
/*四个泛型的含义:前面两个泛型类型是默认的,后面两个是根据需求来决定的
Mapper输入key类型(key是每行行首偏移量)
Mapper输入value类型(value是每行的内容)
Mapper输出key类型
Mapper输出value类型
*/
public class MapperDemo extends Mapper<LongWritable, Text, Text, IntWritable>{
/*
* Mapper组件通过map方法,将输入key和value传给开发者
* 利用context.write(key, value)可以输出key和value
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String strLine = value.toString();
String[] words = strLine.split(" ");
for(String word:words) {
context.write(new Text(word), new IntWritable(1));
}
}
}package hadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/*
* 四个泛型:前面两个对应了Mapper的输出key,value,后面两个根据需求决定
* Reducer输入key类型(值为Mapper输出key)
* Reducer输入value类型(值为Mapper输出value)
* Reducer输出key类型
* Reducer输出value类型
*/
public class ReducerDemo extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int times = 0;
for(IntWritable value:values) {
times = times + value.get();
}
context.write(key, new IntWritable(times));
}
}package hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Driver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//创建MR job对象
Job job = Job.getInstance(conf);
//设置job的运行主类(main)入口
job.setJarByClass(Driver.class);
//设置Mapper组件类
job.setMapperClass(MapperDemo.class);
//设置Mapper的输出key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Reducer组件类
job.setReducerClass(ReducerDemo.class);
//设置Reducer输出key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置待处理文件的HDFS路径(文件或文件夹)
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.80.100:9000/word"));
//设置输出结果的文件路径(该目录事先不能存在,否则报错)
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.80.100:9000/word/result"));
//提交job
job.waitForCompletion(true);
}
}2.2、执行过程
- 先执行Map组件,得到一个结果

- 对上面得到的结果,按照key聚合,得到一个个的map。其中的value类似于集合,封装了多个元素
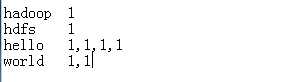
- 然后把这一对对的key和value传给reduce,生成最终结果
对value进行遍历,然后相加即可得到每个单词出现的次数,结果如下: