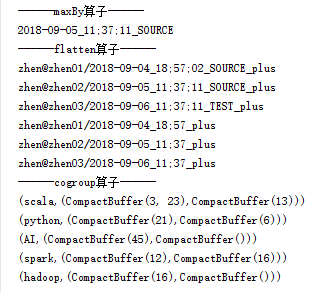
1 package com.dingxin.datainit 2 3 import org.apache.log4j.{Level, Logger} 4 import org.apache.spark.sql.SparkSession 5 6 /** 7 * Created by zhen on 2018/12/18. 8 */ 9 object RDDTransform { 10 def main(args: Array[String]) { 11 Logger.getLogger("org.apache.spark").setLevel(Level.WARN) // 设置日志级别 12 val spark = SparkSession.builder().appName("算子").master("local[2]").getOrCreate() 13 // 算子:maxBy 14 val sourceDate = Array("zhen@zhen01/2018-09-04_18;57;02_SOURCE","zhen@zhen02/2018-09-05_11;37;11_SOURCE", 15 "zhen@zhen03/2018-09-06_11;37;11_TEST") 16 17 val max_by_key = sourceDate 18 .map(_.split("/").last) 19 .filter(x => x.split("_").last.equals("SOURCE")) 20 .maxBy(x => x.split("_").take(2).mkString(""))// 根据输入的条件选择最大值minBy与之相似 21 println("------maxBy算子------") 22 max_by_key.foreach(print) 23 println("\n------flatten算子------") 24 // 算子:flatten 展开多层集合为一个List 25 val resultDate = Array("zhen@zhen01/2018-09-04_18;57","zhen@zhen02/2018-09-05_11;37","zhen@zhen03/2018-09-06_11;37") 26 val seq = Seq(sourceDate, resultDate) 27 seq.flatten.map(r => r + "_plus").foreach(println) 28 // 算子:cogroup 对两个内部数据结构为元组(仅有两个元素的元组)的数据进行匹配,把匹配上的value值保存到一个元组中 29 println("------cogroup算子------") 30 val sc = spark.sparkContext 31 val key = sc.parallelize(Seq("spark", "scala", "hadoop","scala", "python", "AI")) 32 val key_plus = sc.parallelize(Seq("spark", "scala", "python")) 33 val value = sc.parallelize(Seq(12, 3, 16,23, 21, 45)) 34 val value_plus = sc.parallelize(Seq(16, 13, 6)) 35 val tuple_data = key.zip(value) 36 val tuple_plus_data = key_plus.zip(value_plus) 37 tuple_data.cogroup(tuple_plus_data).collect().foreach(println) 38 39 } 40 }
结果: