条件熵:
H(X,Y) - H(X) : (X,Y)发生所包含的熵,减去X单独发生包含的熵,即在X发生的前提下,Y发生新带来的熵。
该式子定义为X发生前提下,Y的熵 H(Y|X)
推导:

即:

即:1 * H(Y|X) 所以 H(X,Y) - H(X) = H(Y|X)
信息增益:
当熵和条件熵中的概率是由数据估计(极大似然估计)得到的,则称对应的熵和条件熵为经验熵和经验条件熵 。
信息增益表示得知特征A的信息而使得类X的信息不确定性减少的程度
定义特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即g(D,A) = H(D) - H(D|A),显然这就是训练数据集D和特征A的互信息
Gini系数:

复习决策树:
决策树是以实例为基础的归纳学习
决策树学习采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处的熵值为0,此时每个叶节点都属于同一类别
决策树学习算法的最大优点就是,他可以自学习。在学习过程中,不需要使用者了解过多背景知识,只需要对训练数据进行良好的标注就可以进行学习。
因为有标注信息因此属于有监督学习
选择最佳特征的数学思想:
数据集D的经验熵为:H(D)
计算特征A对数据集D的经验条件熵:H(D|A)
计算特征A的信息增益:g(D,A) = H(D) - H(D|A)
选择信息增益最大的特征作为当前分裂的特征
损失函数:
当某个叶节点上的类别数目等于1,则称该叶节点为纯节点,纯节点的熵等于0
当某个叶节点的上类别数目等于总类别数目,则成该叶节点为均节点,均节点的熵等于LnK
对所有叶节点的熵求和,该值越小说明对样本的分类越精确。
由于各个叶节点包含的样本数目不同,可使用样本数目加权求熵和
评价函数:
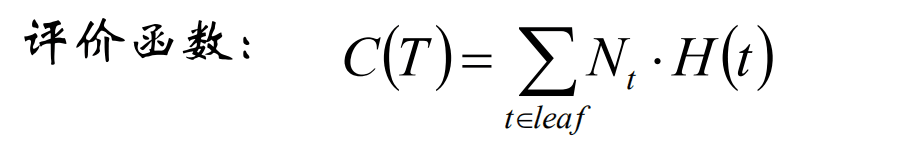
过拟合:
决策数对训练有很好的分类能力,但对未知的测试数据未必有好的分类能力,泛化能力弱,即可能发生过拟合的现象
可以通过剪枝来避免
Bagging的策略:
从样本集中重采样(有重复的)选出n个样本,在所有属性上,对这n个样本建立分类器(ID3,ID4.5, CART,SVM)等等
重复建立m个分类器,将数据放在这m个分类器上,最后根据这m个分类器的选择,决定数据属于哪一分类。
随机森林:
随机森林在bagging的基础上做了修改。步骤为:
1.从样本集中用Bootstrap采样选出n个样本
2.从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立cart决策数
3.重复以上步骤m次,即建立了m棵cart决策树
4.这m个cart树形成了随机森林,通过投票表决结果,决定数据属于哪一类。
当然可以使用决策树作为基本分类器,也可以使用SVM,logistic回归等其他分类器作为基本分类器,习惯上这些分类器所组成的总分类器,仍然叫做随机森林。
样本不均衡的常用处理方法:
假定样本数目A类比B类多,且严重不均衡,可以采用:
1.A类欠采样
随机欠采样
A类分成若干子类,分别与B类进行训练
基于聚类对A进行分类后,与B进行训练
2.B类过采样
随机插值得到新样本
SMOTE
3.代价敏感学习
降低A类的权值,提高B类的权值
使用随机森林建立样本间相似度的计算:
原理:若两样本同时出现在相同的叶节点的次数越多,则二者越相似
算法过程:记样本数目为N,初始化一个N x N的零矩阵S,S[i,j]表示样本i与样本j的相似程度,对于有m棵决策树的随机森 林,遍历所有决策树的所有叶节点,若样本i和j同时出现在该叶节点上,则样本i和j同时出现在同一叶节点的数目加1,S[i,j] += 1。遍历结束后,S即为样本间相似度矩阵。
项目代码:https://github.com/HanGaaaaa/MLAPractice/tree/master/RandomForest