import requests user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36' headers = {'User-Agent':user_agent} r = requests.get("http://www.gov.cn/zhengce/content/2017-11/23/content_5241727.htm",headers = headers) print(r.text)

print('\n\n\n') print('代码运行结果:') print('==============================\n') print('编码方式:',r.encoding) print('\n==============================') print('\n\n\n')
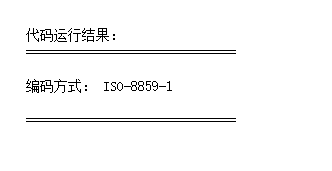
#修改encoding为utf-8 r.encoding = 'utf-8' #重新打印结果 print(r.text)

#指定保存html文件的路径、文件名和编码方式 with open ('E:\\requests.html','w',encoding = 'utf8') as f: #将文本写入 f.write(r.text)
import re pattern = re.compile(r'\d+') result1 = re.match(pattern, '你说什么都是对的23333') # print('\n\n\n') print('代码运行结果:') # print('==============================\n') if result1: print(result1.group()) else: print('匹配失败') result2 = re.match(pattern, '23333你说什么都是对的') if result2: print(result2.group()) else: print('匹配失败') # print('\n==============================') # print('\n\n\n')

#用.search()来进行搜索 result3 = re.search(pattern, '你说什么23333都是对的') print('代码运行结果:') print('==============================\n') #如果匹配成功,打印结果,否则打印“匹配失败” if result3: print(result3.group()) else: print('匹配失败')

print('代码运行结果:') # print('==============================\n') #使用.split()把数字之间的文本拆分出来 print (re.split(pattern, '你说双击666都是对的23333哈哈')) # print('\n==============================') # print('\n\n\n')

# print('\n\n\n') print('代码运行结果:') # print('==============================\n') #使用.findall找到全部数字 print (re.findall(pattern, '你说双击666都是对的23333哈哈')) # print('\n==============================') # print('\n\n\n')

matchiter = re.finditer(pattern, '你说双击666都是对的23333哈哈') for match in matchiter: print(match.group())

p = re.compile(r'(?P<word1>\w+) (?P<word2>\w+)') s = 'i say, hello world!' print (p.sub(r'\g<word2> \g<word1>',s))
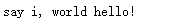
p = re.compile(r'(\w+) (\w+)') print(p.sub(r'\2 \1',s))

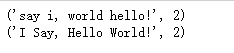
def func(m): return m.group(1).title() + ' ' + m.group(2).title() print(p.sub(func,s))

print(p.subn(r'\2 \1', s)) print(p.subn(func,s))
#导入BeautifulSoup from bs4 import BeautifulSoup #创建一个名为soup的实例 soup = BeautifulSoup(r.text, 'lxml', from_encoding='utf8') print(soup)

# print('\n\n\n') print('代码运行结果:') # print('==============================\n') #使用.'标签名'即可提取这部分内容 print(soup.title) # print('\n==============================') # print('\n\n\n')

# print('\n\n\n') print('代码运行结果:') # print('==============================\n') #使用.string即可提取这部分内容中的文本数据 print(soup.title.string) # print('\n==============================') # print('\n\n\n')

# print('\n\n\n') print('代码运行结果:') # print('==============================\n') #使用.get_text()也可提取这部分内容中的文本数据 print(soup.title.get_text()) # print('\n==============================') # print('\n\n\n')
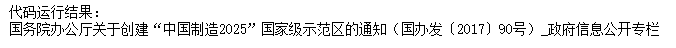
# print('\n\n\n') print('代码运行结果:') # print('==============================\n') #打印标签<p>中的内容 print(soup.p.string) # print('\n==============================') # print('\n\n\n')

#使用find_all找到所有的<p>标签中的内容 texts = soup.find_all('p') #使用for循环来打印所有的内容 for text in texts: print(text.string)

............................................

#找到倒数第一个<a>标签 link = soup.find_all('a')[-1] # print('\n\n\n') print('BeautifulSoup提取的链接:') # print('==============================\n') print(link.get('href')) # print('\n==============================') # print('\n\n\n')
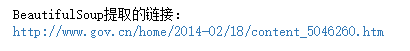
print(soup.title.name) print(soup.title.string) print(soup.attrs) print(soup.a.string) print(soup.p.string) print(type(soup.a.string))

print(soup.head.contents)

print(len(soup.head.contents)) # print(soup.head.contents[3].string)
50
for child in soup.head.children: print(child)

for child in soup.head.descendants: print(child)

print(soup.head.string) print(soup.title.string) print(soup.html.string)

for string in soup.strings: print(repr(string))

print(soup.title,'\n') print(soup.title.parent)

print(soup.a) for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name)

print(soup.p.next_sibling.next_sibling)

for sibling in soup.a.next_siblings: print(sibling)

for element in soup.a.next_elements: print(element.string)

print(soup.find_all('b'))
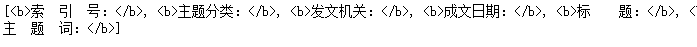
print(soup.find_all('p'))

..................................................................

for tag in soup.find_all(re.compile('^b')): print(tag.name) #print(soup.find_all(re.compile('^p')))
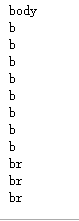
print(soup.find_all(['a','b']))

for tag in soup.find_all(True): print(tag.name)

....................................................
def hasclass_id(tag): return tag.has_attr('class') and tag.has_attr('id') print(soup.find_all(hasclass_id))

print(soup.find_all(style='text-indent: 2em; font-family: 宋体; font-size: 12pt;'))
print(soup.find_all(href=re.compile('gov.cn')),'\n')

print(soup.find_all(text=re.compile('通知')))

print(soup.find_all('p',limit=2))

policies = requests.get('http://www.gov.cn/zhengce/zuixin.htm',headers = headers) policies.encoding = 'utf-8' print(policies.text)

p = BeautifulSoup(policies.text,'lxml',from_encoding='utf8') print(p)

contents = p.find_all(href = re.compile('content'))