
第一志愿:找到30部门所有雇员的薪金

第二步:以上返回的是多行单列的数据,此时可以三种判断符判断:IN、ANY、ALL。
现找到所有员工,使用“>ALL"

第三步:要找到部门的信息,自然在FROM子句之后引入dept表。而后要消除笛卡尔积,用内连接

第四步:需要统计出部门人数的信息

于是此时出现了一个矛盾,因为SELECT子句中有其它字段,所以不可能使用GROUP BY。所以考虑利用子查询分组,即:在FROM 子句之后使用子查询先进行分组统计,而后将临时表采用多表查询操作。


第一步:没有scott用户,就无法知道哪个雇员满足条件,需要找到scott的工作
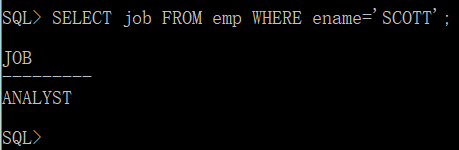
第二步:以上的查询返回的是单行单列,所以只能在WHERE或者是HAVING中使用,根据现在的需求,肯定在WHERE中使用,对所有的雇员进行筛选。

第三步:如果不需要重复信息,那么可以删除SCOTT
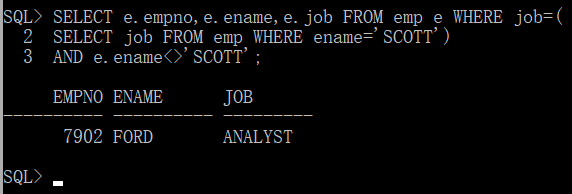
第四步:部门名称只需要加入dept表即可

第五步:此时的查询不可能使用GROUP BY进行分组,所以需要使用子查询实现分组

第六步:找到对应的领导信息,直接使用自身关联

3、列车薪资比”SMITH"或“ALLEN"多的所有员工的编号、姓名、部门名称、其领导姓名,最高及最低工资

第一步:知道SMITH"或“ALLEN",这个查询返回多行单列(WHERE中使用)
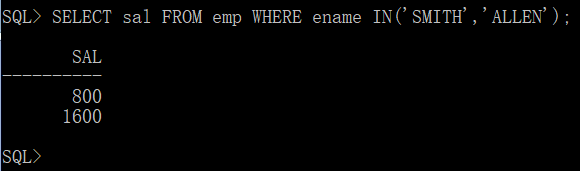
第二步:现在应该比里面任意一个多即可,但是要去掉两个雇员。由于是多行单列的子查询,所以使用>ANY完成

第三步:找到部门名称

第四步:找到领导信息

第无步:部门人数、平均工资、最高及最低工资。整个查询里面不能使用GROUP BY。所以现在应该利用子查询实现统计函数。


第一步:emp表进行自身关联,而后除了消除笛卡尔积的条件之外,还要判断受雇日期

第二步:找到部门信息

第三步:统计部门人数


第一步:找到所有办事员信息
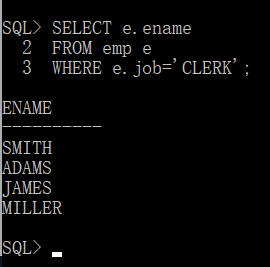
第二步:找到部门名称

第三步:统计部门的人数

第四步:找到公司等级

总结:
所谓复杂查询的复杂也只是将多表查询,统计查询,子查询融合一起使用,这里面关键主要的是:
|--笛卡尔积的消除
|--GROUP BY 的使用限制