摄取节点 - Ingest Node
使用Elasticsearch进行输出时,可以将Filebeat配置为使用 摄取节点在Elasticsearch中进行实际索引之前预处理文档。当您想对数据进行一些额外处理时,摄取节点是一个方便的处理选项,但您不需要Logstash的全部功能。例如,您可以在Elasticsearch中创建一个摄取节点管道,该管道由一个处理器组成,该处理器删除文档中的字段,然后是另一个重命名字段的处理器。
使用elasticsearch自带的节点筛选日志,默认ingest node是启动着的。
可使用 http请求添加ingest的pipeline 规则,例如:
添加一个Spring-logs名为pipeline 的管道规则:
构造 PUT 请求,注意是PUT ,向ES添加pipeline。 如,添加一个Spring-logs的管道:http://127.0.0.1:9200/_ingest/pipeline/Spring-logs
put _inget/pipeline/Spring-logs
{
"description" : "test pipeline",
"processors" : [
{
"grok": {
"field": "message",
"patterns": ["\\[(?<date>.*)\\]\\[(?<level>[A-Z]{4,5})\\]\\[(?<thread>[A-Za-z0-9/-]{4,70})\\]\\[(?<class>[A-Za-z0-9/.]{4,40})\\]\\[(?<msg>[\\s\\S]*)"]
},"remove": {
"field": "message"
}
}
]
}
注意patterns中如果使用到正则匹配,需要注意转义问题,最好查看添加成功后的管道规则和最初的是否一样,此处经常出错导致无法筛选日志。
备注:
#grok 里边有定义好的现场的模板你可以用,但是更多的是自定义模板,规则是这样的,小括号里边包含所有一个key和value,例子:(?<key>value),比如以下的信息,第一个我定义的key是data,表示方法为:?<key> 前边一个问号,然后用<>把key包含在里边去。value就是纯正则了,这个我就不举例子了。这个有个在线的调试库,可以供大家参考,
http://grokdebug.herokuapp.com/
查看是否添加成功:
curl http://127.0.0.1:9200/_ingest/pipeline
如果上述执行失败,请检查Ingest node是否启动,可手动在elasticsearch.yml中设置:
node.ingest: true
在Elasticsearch中定义管道之后,只需配置Filebeat即可使用管道。要配置Filebeat,请在文件中的parameters选项下指定管道ID。
让它输出到自定义的pipeline:
filebeat:
prospectors:
- type: log
//开启监视,不开不采集
enable: true
paths: # 采集日志的路径这里是容器内的path
- /var/log/elkTest/error/*.log
# 日志多行合并采集
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
# 为每个项目标识,或者分组,可区分不同格式的日志
tags: ["java-logs"]
# 这个文件记录日志读取的位置,如果容器重启,可以从记录的位置开始取日志
registry_file: /usr/share/filebeat/data/registry
output:
elasticsearch: # 我这里是输出到elasticsearch,也可以输出到logstash
hosts: ["127.0.0.1:9200"] # elasticsearch地址
pipelines:
- pipeline: "Spring-logs"
注:6.0以上该filebeat.yml需要挂载到/usr/share/filebeat/filebeat.yml,另外还需要挂载/usr/share/filebeat/data/registry 文件,避免filebeat容器挂了后,新起的重复收集日志。
一起配置完后,可触发下错误日志的生成,在Kibana中,便可看到有Ingest node处理过的日志内容。
效果展示
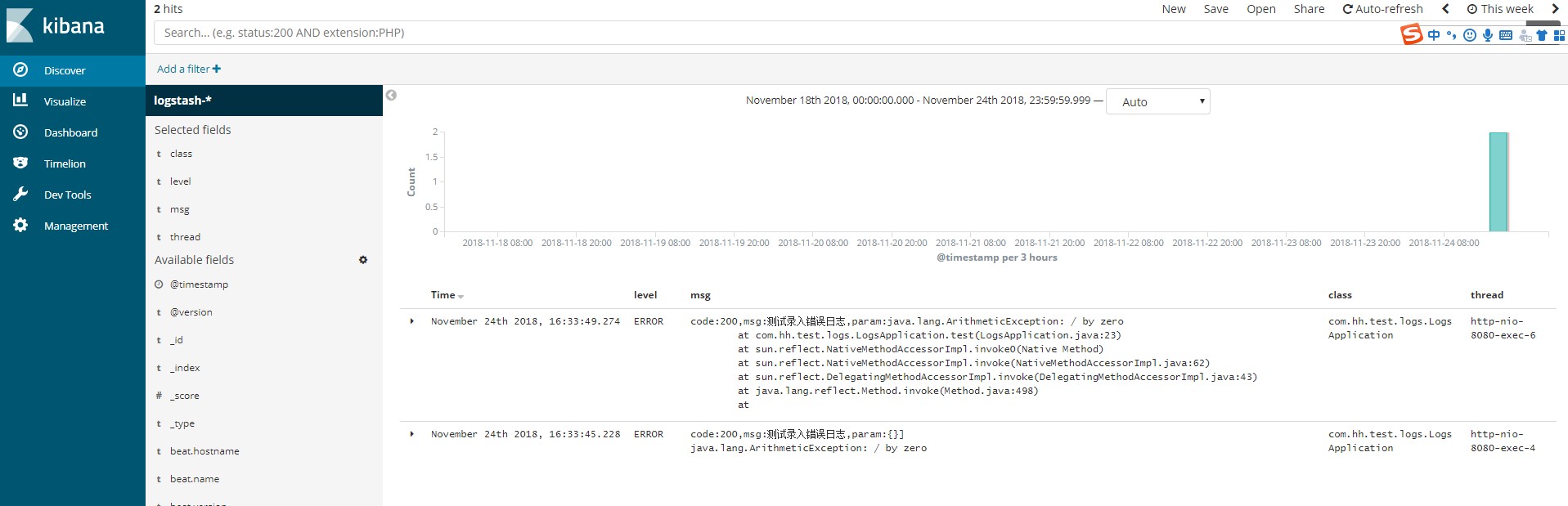
测试项目和Ingest Node 配置以及结合Logstash的测试例子以上传到github
地址: https://github.com/liaozihong/ELK-CollectionLogs
参考:
Grok Debugger
Filebeat官方文档
Filebeat-Ingest Node
Ingest Node