【算法笔记】第二章: C/C++ 快速入门
标签(空格分隔):【算法笔记】
第二章:C/C++ 快速入门
2.0 引言
scanf 和 printf 比 cin 和 cout 要快得多。
C 语言的文件扩展名为 .c,但是考虑到 C++有很好的特性,因此一般直接使用 C++的扩展名 .cpp 。
头文件和主函数
- 头文件,例如
#include<stdio.h>,其中 stdio.h 是标准输入输出库,在程序中如果由输入输出,就必须加上这个头文件。stdio 的全称为 standard input output ,h 为 head 的缩写,.h 就是头文件的文件格式。
当然,还有一些其他的库,例如,math.h 负责一些数学函数,string.h 负责字符串函数。在使用过程中,将它们的头文件包含到这个程序中来即可。
此外,在 C++ 中,stdio.h 可以写成它的等价写法 cstdio,也就是去掉 .h 并它前面加上 c 即可。所以#include<stdio.h>和#include<cstdio>是等价的。类似的有,#include<math.h>和#include<cmath>是等价的,#include<string.h>和#include<cstring>是等价的。 - 主函数:
- 头文件,例如
int main(){
...
return 0;
}上面的代码就是主函数。主函数就是一个程序的入口位置,整个程序从主函数开始运行,一个程序最多只能有一个主函数。
2.1 基本数据类型
2.1.1 变量的定义
变量是在程序运行过程中其值可以改变的量,需要在定义后才可以使用,其定义格式如下:
变量类型 变量名;
当然,在变量定义时可以为它赋予初值:
变量类型 变量名 = 初值;变量的命名需要满足以下几个条件:
- 不能是 C 语言的标识符(例如 for,if,or 等,因为它们本身在 C 语言中有含义)。建议选择具有一定实际意义的变量名,例如 Max,Sum 等,以提高程序可读性。
- 变量名的第一个字符必须是字母或下划线,除了第一个字符之外的其他字符必须是字母、数字或下划线。例如,abc,_hvsym12 是合法的变量名,而 6abc 是非法的变量名。
- 区分大小写,Max 和 max 可以作为两个不同的变量名。
2.1.2 变量类型
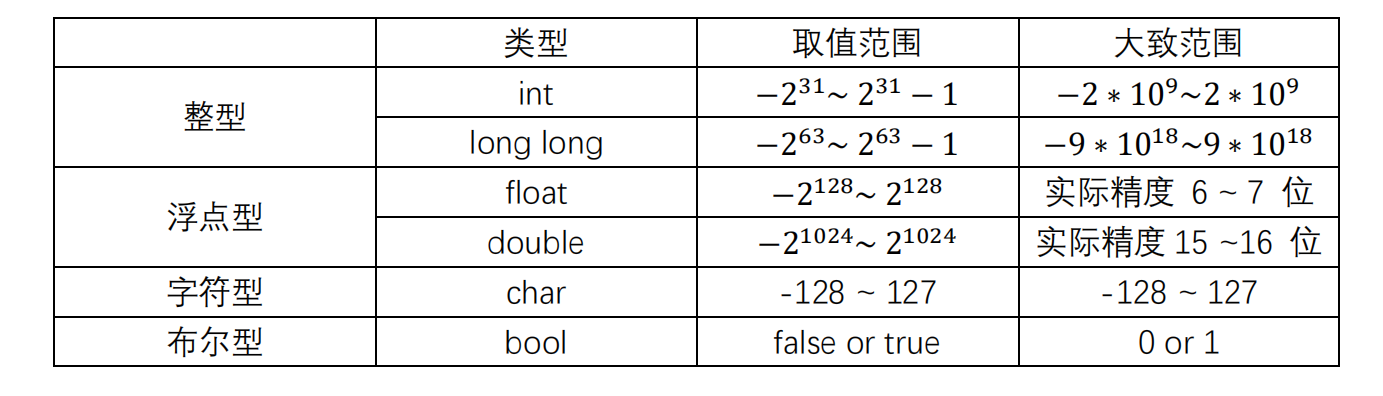
四种基本类型:
整型 :整型一般可以分为 short 、int、long long .
- int,一个int 占用 32 位,即 4 Byte,取值范围从
~ ,绝对值在 之内的正数都可以使用 int 类型。 - long long,一个 long long 占用 64 位,即 8Byte,取值范围从
~
,如果题目要求的整数范围大于 2147483647(或者
),就需要使用 long long 来存储。
注意:对于long long 类型的变量赋予初值,需要在初值后面加上LL,否则会出现编译错误。
long long BigNum = 123456789012345LL; - 另外,对于整型数据,都可以在前面加上一个 unsigned,以表示无符号整型,例如 unsigned int 和unsigned long long。占用的位数和之前相投,但是去掉了负数部分,因此,unsigned int 表示范围
~
和 unsigned long long 表示
~
。
一般而言,很少会使用 unsigned int 和unsigned long long 的情况。
- int,一个int 占用 32 位,即 4 Byte,取值范围从
浮点型:通俗而言,浮点型就是小数,分为单精度(float)和双精度(double)。
- float,一个单精度类型的浮点数占用 32bit,其中 1bit作为符号位, 8bit作为指数位, 23bit作为尾数位,可以存放的数值范围是 ~ , 但是有效精度只有 6 ~ 7 位,这对一些对于精度要求比较高的运算是不合适的。
- double,一个双精度类型的浮点数占用 64bit,其中1bit作为符号位,11bit作为指数位,52bit作为尾数位,可以存放的数据的范围 是 ~ ,其有效精度为 15 ~ 16 位,比 float 优秀的多。
例如一下代码:
#include<stdio.h> int main(){ double a = 3.14, b = 0.12; double c = a + b; printf("%d", c); return 0; }记住以下一点,在程序设计题目中,对于浮点型而言,用 double 存储即可。
字符型
字符变量和字符常量
定义顺便赋予初值代码如下:char c = 'e'。
如何理解字符常量?在上述代码中,c 便是一个字符变量,它可以被赋值。但对于字符本身,例如 ‘e’,它是一个不能被改变,不能被赋值,故它是字符常量。字符常量可以赋值给字符变量,就好像整型常量可以被赋值给整型变量一样。另外,字符常量必须是单个字符,同时它必须使用单引号标注。
在 C 语言中,字符常量用 ASCII码 统一编码。标准的ASCII码的范围是 0 ~ 127,其中包含了控制字符和通信专用字符(不可显示) 和常用的可显示字符。在键盘上,通过敲击可以在屏幕上显示的字符就是可显示字符,例如:

尤其需要注意的是,小写字母比大写字母的ASCII码的值大 32。
在计算机中,字符按照ASCII码存储。例如:
char c = 117; printf("%c",c)
其显示输出结果为u.转义字符
在上文中我们提到,ASCII 码有一部分是控制字符,是不可显示的。例如:删除,换行,Tab等都是控制字符。如何在程序中表示一个控制字符?在C语言中,可以通过用一个右斜线加一些特定的字母来实现。例如,换行用’\n’表示,Tab键用’\t’ 表示。在这种情况下,斜线后面的字符失去了本身的含义,因此称为“转义字符”。\\经常用到的转义字符只有下面两个: \n 换行 \0 代表空字符NULL,其ASCII码为 0,注意\0不是空格字符串常量
字符串是由若干个字符组成的串,在C语言中没有单独一种基本数据类型可以存储字符串,而在 C++ 中有string 类型,在C语言中只可以使用字符数组的方式。在这里,我们现介绍字符串常量。
在上文中我们提到,字符常量就是由一个单引号标记的字符,那么此处的字符串常量则是由双引号标记的字符集,例如”Ilovecomputer”,这就是一个字符串常量。
字符串常量可以作为初值付给字符数组,并用 %s 的格式输出。#include<stdio.h> int main(){ char str1[25] = "I love compueter scince"; char str2[25] = "I want to learn code"; printf("%s %s", str1, str2); return 0; }在上面的例子中,str1[25] 和 str2[25] 均代表由 25 个char 字符组成的字符集合,可以称之为字符数组。
注意,不可以将字符串常量赋值给字符变量char c = "1afdas";是非法的。- 布尔型
布尔型在 C++中可以直接使用,但是在C语言中必须添加 stdbool.h 的头文件才可以使用。布尔型变量又称为 bool类型变量。他的取值只能是 true 和 false ,分别代表 非零 和 零。在赋值时,可以直接使用 true 或者 false 赋值,也可以使用整数常量进行赋值。对于任何的非零整数,都会转换为 true.
2.1.3 强制类型转换
有时候需要把浮点数的小数部分切掉而只是用整数部分,或者把整数转化为浮点数来进行除法操作。这些情况下就需要使用强制类型转换,即把一种数据类型转换为另外一种类型。
(新类型名)类型名需要注意的是,如果将一个类型的变量赋值给另外一个类型的变量,却没有写强制类型转换操作,那么编译器将自动进行转换。但是这并不是说任何时候都不用使用强制类型转换。如果在计算的过程中需要转换类型,那么就不可以等待它算完之后再赋值时转换。
2.1.4 符号常量和 const 常量
通俗来讲,符号常量就是“替换”,即用一个标识符来替代常量,又称为“宏定义”,或者“宏替换”。
1.第一种格式
#define 标识符 常量
例如:#defien PI 3.1415926- 另外一种格式
const 数据类型 变量名 = 常量;
例如:const int PI = 3.1415926;
- 另外一种格式
这两种写法都叫常量,它们的值一旦确定后不可更改,例如
PI = PI + 1;操作不可进行,推荐使用 const 写法。另外,define 除了可以定义常量之外,还可以定义任何语句与片段。
格式如下:
#define 标识符 任何语句与片段
例如:#define ADD(a,b) ( (a) + (b))
或许有人疑问,直接定义成#define ADD(a,b) a + b或者#define ADD(a,b) ( a + b)不可以吗?为什么需要那么多括号呢?然而,实际上,必须需要这么多括号。宏定义是直接将对应的部分进行替换,然后才进行编译和运行。
例如:
#include<stdio.h>
#difine CAL(x) ( x * 2 + 1)
int main(){
int a = 1;
printf("%d",CAL(a+1));
return 0;}上述代码的输出结果将会是 4,而不是预想的 5 ,因为在上述代码中,宏定义会将替换的部分原封不动的替换进去。CAL( a + 1 * 2 + 1),其结果为 4.
2.1.5 运算符
算数运算符
- 加法运算符 ‘+’;
- 减法运算符 ‘-‘;
- 乘法运算符 ‘*’;
- 除法运算符 ‘/’;
注意,当除数与被除数都是整数时,例如a = 3,b = 2; c = a/b;得到的 c 为 1.
另外,当除数是 0 时,会导致程序异常退出或者得到错误输出“1.#INF00”。 - 取模运算符 ‘%’;
取模运算符返回被除数与除数相除得到的余数,例如a = 5,b = 3; c = a%b;得到的 c 为 2.
与除法运算符一样,除数不允许为 0. - 自增运算符 ‘++’;
注意i++;++i;二者的区别,i++ 是先使用i再对 i 加一, ++i是先对 i 加一再使用i. - 自建运算符 ‘–’;
关系运算符

逻辑运算符
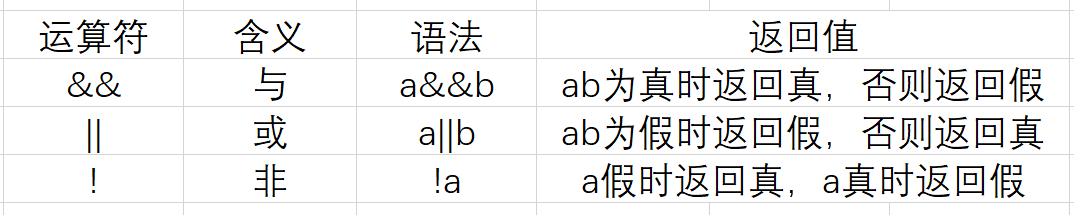
条件运算符
条件运算符( ? : ) 是 C语言中唯一的三目运算符,即需要三个参数的运算符。格式如下:A ? B : C
含义:若A为真,则返回B;若A为假,则返回C。- 位运算符

2.2 顺序结构
2.2.1 赋值表达式
- 使用 ‘=’等号来完成赋值操作。
例如:int test = 5;
或者:int n = 3 * 2 + 1;
再或者:int m = (1>6) && (2<8);
赋值运算符可以通过将其他运算放到前面来实现赋值操作的简化。例如:n += 2;它的意思是n = n + 2;
2.2.2 使用scanf 和 printf 进行输入/输出
C语言中stdio.h 库函数中提供了 scanf 和 printf ,分别对应输入输出。
scanf函数:
格式:scanf("格式控制",变量地址);
下图中,’&’称作取地址运算符。

- 说明:&n的意思是得到变量n的地址,在该地址出写入内容。而字符串中str并没有 &运算符,因为数组名称本身就代表了这个数组的第一个元素的地址。在整个C语言中,除了char数组在输入时候不需要添加 & 外,其余都需要加 &.
- 另外,很重要的一点:在scanf中,双引号内的内容其实就是整个输出,只不过把数组转换成它们对应的格式符并按照变量的地址按次序写在后面而已。例如,
scanf("%d::%d",&a,&b);,就必须输入类似于 “1::2”这般的格式。 - 如果要输入类似 “3 4” 这种用空格隔开的两个数字,在scanf中的两个 %d 之间可以不加空格,
scanf("%d%d",&a,&b);。
原因在于:除了 %c 之外,scanf对于其他格式符,(如 %d),的输入是以空白符(即空格、换行等)为结束判断标志的。因此除非使用%c把空格按字符读入,其他情况下都会自动跳过空格和换行。另外,字符数组使用%s读入时以空格和换行作为读入标志的结束。
例:以下代码中,若输入abcd efg则输出结果为abcd.
char a[20]; scanf("%s",a); printf("%s",a);
printf函数:
格式:printf("格式控制",变量地址);
在printf中,不需要给出变量地址,只需要给出变量名即可。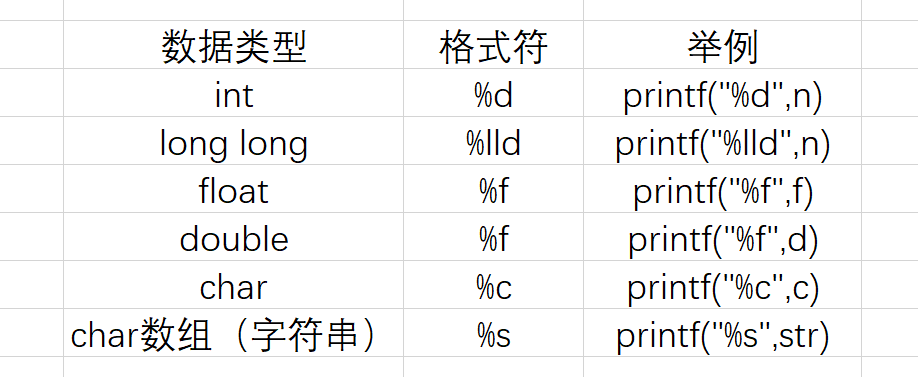
- 说明:对于double类型的变量,其输出格式变成了 %f,然而在scanf中是%lf.在某一些系统中,如果把输出格式写成 %lf 也没有错误,不过尽量还是按照要求写更标准。
- 另外,不要因为float类型的scanf和printf比较好记就用float,因为float精度低。
- 如果想要输出 ‘%’ 或者 ‘\’,其代码格式为
printf("%%");,printf("\\");.例如想要输出 “%%%”,代码为printf("%%%%%%"); - 三种实用的输出格式
①%md:可以使不满足 m 位的int型变量以 m 位进行右对齐输出,其中高位用空格补齐;若变量本身超过 m 位,则保持原样。例如:int a = 123; printf("%5d", a);输出结果为__123
②%0md:%0md只是在%md中间多加了0.和%md不同点在于,当变量不足m位时,将在高位补0而不是空格。例:int a = 123; printf("%5d", a);输出结果为00123.
③%.mf:可以让浮点数保留 m 位小数输出。其中“保留”适用的是精度的四舍六入五成双规则。(不是四舍五入,四舍五入用round函数)
2.2.3 使用getchar和putchar输入/输出字符
- getchar用于输入单个字符,putchar输出单个字符。在某些scanf函数使用不便的情况下可以使用getchar.
例如:
char c1,c2,c3,c4;
c1 = getchar();
getchar();
c2 = getchar();
c3 = getchar();
putchar(c1);putchar(c2);putchar(c3); 当输入abcd时,输出结果为acd;
当输入ab再按下 <Enter> 键 ,再输出c,再按下<Enter> 键.最终输出结果为
a
c这意味着getchar可以识别换行符,c2中存储的是’\n’,因此输出中会有换行符出现。
2.2.4 注释
- 使用 “/* */”进行若干连续行的注释。
- 使用 “//”进行一行之内的注释。
2.2.5 typedef
- typedef可以给复杂的数据类型起一个别名,这样再使用过程中就可以用别名来代替原先的写法。例如,当数据类型是 long long 时,可以进行替换,以节约输入时间。
typedef long long LL;
LL a = 12345678901234567LL;
printf("%lld",a);效果与 long long 是一样的。
2.2.6 常用的math函数
- C语言中,如果需要使用数学函数,需要再头文件中加上 “math.h” .以下时几个常用的数学函数。
- fabs(double x)
用于对 double类型的变量取绝对值。 - floor(double x):对 double 类型向下取整。
ceil(double x):对 double 类型向上取整。 - pow(double r, double p):返回r的p次方。
- sqrt(double x):返回 x 的算术平方根。
- log(double x):返回 x 以自然对数为底的对数。
另外,在 C语言中,没有对任意底数求对数的函数,因此必须使用换底公式将不是以自然对数为底的对数转换为以 e 为底的对数。 . - sin(double x),cos(double x),tan(double x):三角函数,其中要求参数必须是弧度制。例如:
sin( pi * 45 / 180); - asin(double x),acos(double x),atan(double x):反三角函数。
- round(double x):对double 类型的变量四舍五入。
- fabs(double x)
2.3 选择结构
2.3.1 if语句
if语句格式:
if(条件A){ }当条件A为真时,执行括号内内容。
if-else 语句,格式:
if(条件A){ } else{ }当条件A为真时,执行括号内内容。否则执行else的括号内内容。
if-else if-else 语句,格式:
if(条件A){ } else if(条件B){ } else{ }先判断条件A是否成立,若成立则执行if中括号内容,不成立则判断条件B是否成立,若成立则执行else-if内语句,若不成立,则执行else内语句。
注意:
- 如果括号内只有一个语句,则可以去掉大括号。已达到美观的目的。
- 在条件判断中,如果表达式是 “!=0”或者”==0”则可以分别进行省略,和添加非运算符的手段进行简化。即
if( a !=0)和if(a)等价。if( a ==0)和if(!a)等价。
2.3.2 if语句的嵌套
if语句的嵌套指在 if或者 else的执行内容中使用 if语句,格式如下:
if(条件A){ if(条件B){ } else{ } } else{ }当条件A成立,执行大括号内语句,执行期间如果条件B成立,则执行另一个if内的语句。
2.3.3 switch语句
switch在分支条件较多时会显得精炼,格式如下:
switch(表达式){ case 常量表达式1: ... break; case 常量表达式2: ... break; default: ... }注意,
- 两个case之间的语句并没有使用大括号括起来,因为case本身默认吧两个case之间的内容全部作为上一个case的内容,因此不用加大括号。
- 代码中break语句作用在于结果当前switch语句,如果删除break,那么程序会从第一个匹配的case语句一直执行完下面所有语句才会推出switch.
2.4 循环语句
2.4.1 while语句
格式:
while(条件A){ }当满足条件A时反复执行括号内语句。
另外,while条件判断的是真假,同样有while( a !=0)和while(a)等价。while( a ==0)和while(!a)等价。
2.4.2 do-while语句
do-while 和while语句类似。但是它们的格式是上下颠倒的。
do{ }while(条件A)do-while语句首先执行省略号中内容一次,然后再判断条件A是否成立。如果条件A成立,则继续反复执行省略号的内容,直到条件A不成立。
do-while语句和while语句的区别:do-while会首先执行一次循环体,然后再判断循环条件是否为真。这使得do-while语句实用性远不如while语句。
2.4.3 for语句
格式:
for(表达式A;表达式B;表达式C){ }先执行表达式A,随后判断是否满足表达式B,若满足,执行括号内内容,反之则退出循环;括号内内容执行完毕之后,执行表达式C,重新判断是否满足表达式B.
2.4.4 break和continue语句
- break直接退出循环。
- continue结束循环的当前回合,直接进入下一回合。
2.5 数组
2.5.1 一维数组
- 格式:
数据类型 数组名[数组大小];
其中数组大小必须是整数常量,不可以是变量。
访问格式:数组名[下标]
注意,在定义了数组大小为size的一维数组之后,只能访问下标为 0 ~ size - 1的元素。
2.5.2 冒泡排序
排序:将一个无序序列按照某个规则进行有序排列。
冒泡排序
排序算法中最基础的一种。它的本质在于交换,算法思想:每次通过交换的方式把当前剩余得的最大元素移动到另一端。
例如:现在有一个数组a其中有五个元素。分别为a[0] = 3、a[1] = 4、 a[2] = 1、 a[3] = 5、 a[4] = 2.要求从小到大排序。步骤如下:
实现代码如下:
void BubblingSort( int *A,int N){
for(int i = 0; i < N; i++)
for(int j = 0; j < N - i;j++)
if( A[j+1] < A[j])
swap( A[j+1],A[j]);
}2.5.3 二维数组
- 格式:
数据类型 数组名[第一维大小][第二维大小];
访问格式:数组名[下标1][下标2]
注意,对于定义为 int a[size1][size2];的二维数组,下标的取值范围只可以是 0 ~ size1 - 1, 0 ~ size2 - 1.
例如,对于二维数组:int a[5][9] = { {3,1,2}, {8,4}, {}, {1,2,3,4,5} };那么a[1][10]的值为 4 . - 重要的一点,如果数组大小比较大(大概 级别),那么需要将其定义在主函数外面,否则会使程序异常退出,原因在于函数内部申请的局部变量来自系统栈,允许申请的空间比较小;而函数外部申请的全局变量来自于静态存储区,允许申请的空间较大。
2.5.4 多维数组
- 多维数组仅仅比二维数组的维度有所差别,使用方法无异。
2.5.5 memset——对数组每一个元素赋予同样的值
- 一般而言,给数组中每一个元素赋予相同的值有两种方法:memset函数和fill函数。
- memset函数
- 首先,使用memset函数 需要在程序开头添加 string.h 头文件。
- 格式:
memset(数组名, 值, sizeof(数组名) ); - 对于初学者而言,建议使用memset赋 0 或 -1.因为memset使用的是按字节赋值,即对于每个字节赋予同样的值,这样组成 int型的 4 个字节就会被赋予相同的值,而由于 0 的二进制补码全为 0,-1 的二进制补码全为 1,不易弄错。如果需要对数组赋予其他值(例如 1),那么请使用fill函数(虽然fill函数比memset慢一些)。
- memset函数
2.5.6 字符数组
- 字符数组的初始化:和普通数组一样,例如:
char str[10] = {'h','e','l','l','o'};
另外,字符数组也可以通过直接赋值字符串来初始化(仅限于初始化,程序其他位置不允许这样直接赋值整个字符串)。例如:char str = "hello"; - 字符串数组的输入输出:
- scanf输入、printf输出:
#include<stdio.h>
int main(){
char str[10];
scanf("%s",str);
printf("%s",str);
return 0;}2.getchar输入、putchar输出:
getchar和putchar 分别用来输入和输出单个字符,也可以通过循环的方式来输入输出字符串。
#include<stdio.h>
int main(){
char str[3][11];
for(int i = 0;i<3;i++){
for(int j = 0;j<3;j++)
str[i][j] = getchar();
getchar();//吸收换行符
}
for(int i = 0;i<3;i++){
for(int j = 0;j<3;j++)
putchar(str[i][j]);
putchar('\n');
}
return 0;}3.gets输入、puts输出:
gets用来输入一行字符串(注意:gets识别 \n 换行符作为输入结束,因此scanf完一个整数后,如果使用gets,就需要先用getchar接受整数后的换行符),并将其存放于一维数组(或者二维数组中的一维)中;
puts用来输出一行字符串,即将数组在界面上输出并紧接着一个换行。
- 字符数组的存放方式
由于字符数组是由若干个char类型的元素组成,因此字符数组的每一位都是一个char字符,除此之外,在一维字数数组(或者二维字符数组的第二维)的末尾都一个空字符\0,以表示存放的字符串的结尾。
空字符\0 在使用gets或者scanf输出字符串时会自动添加在输入的字符串后面,并占用一个字符位,而puts与printf函数就是通过识别\0来作为字符串的结尾来输出的的。
注意:
- 结束符\0 的ACSII码为 0,即空字符NULL,占用一个字符位,因此开字符数组的时候一定要记得字符数组的长度比实际存储的字符串长度至少多1.
- \0和空格不是一个字符,空格的ASCII码为 32.
- int型数组的末尾不需要添加\0,只有char型数组需要。
- 当使用getchar等非scanf和gets输入时,一定要在输入的字符串后面添加结束符,否则printf和puts无法识别末尾,进而导致输出多余的乱码。
2.5.6 string.h头文件
string.h头文件包含了许多用于字符数组的函数。
strlen():得到字符串数组中第一个\0前的字符的个数。格式:
strlen(字符数组);
例如:str = "lovecode"; printf("%d",strlen(str));输出结果为 8.strcmp():返回两个字符串大小比较的结果,其比较原则是按照字典序.格式:
strcmp(字符数组1, 字符数组2);
规则:对于两个字符数组 str1 和 str2 ,如果满足 str1[0…k-1] == str2[0…k-1], str1[k]
2.5.7 sscanf与sprintf
- sscanf 和 sprintf 均在stdio.h 头文件下,它们是处理字符串问题的利器.
- 格式:假设str为一个char数组。
sscanf(str,"%d",&n);
sprintf(str,"%d",n);- 用法:
- sscanf 表示把字符数组str中内的内容以 %d 的格式写到 n 中,例:
#include<stdio.h>
int main(){
int n;
char str[100] = "1234";
sscanf(str,"%d",&n);
printf("%d\n",n);
return 0;}
输出结果为 1234.
2. sprintf 表示把 n 以 %d 的格式书写到 str 字符数组中,例:
#include<stdio.h>
int main(){
int n = 12345;
char str[100];
sprintf(str,"%d",n);
printf("%d\n",n);
return 0;}
输出结果为 12345.
3. 以上两个只是简单应用。稍微复杂点的应用如下:
对于 sscanf:
#include<stdio.h>
int main(){
int n;
double db;
char str2[100];
char str[100] = "1234:3.123,hello";
sscanf(str,"%d:%lf,%s", &n, &db, str2);
printf("n = %d, db = %lf, str2 = %s ", n,db,str2);
return 0;}输出结果n = 1234, db = 3.123000, str2 = hello
对于sprintf:
#include<stdio.h>
int main(){
int n = 1234;
double db = 2.71828;
char str2[100]= "e is a natural number";
char str[100];
sprintf(str,"%d,%lf,%s",n,db,str2);
printf("str = %s ", str);
return 0;}输出结果str = 1234,2.718280,e is a natural number
- 另外,sscanf还支持正则表达式。
2.6 函数
2.6.1 函数的定义
格式:
返回类型 函数名称(参数类型 参数){ 函数主体 }- 无参函数:不需要提供参数就可以执行的函数。
- 有参函数:例如fabs(x)等需要提供参数的函数。
全局变量和局部变量
- 全局变量,指的是在定义之后的所有程序段都有效的变量。
- 局部变量,定义在函数内部,只在函数内部生效,函数结束时局部变量销毁。
例如
void change(int x){ x++;} int main(){ int x = 10; cout<<x; }
上述代码的输出结果是
10,因为通过函数change传过去的x只是一个副本,这种传递参数的方式叫做值传递,函数小括号内定义的参数位形式参数(形参),而实际调用时小括号内的参数位实际参数(实参).
2.6.2 再谈main函数
- 主程序函数对于程序来说只能有一个,无论主函数位于那个位置,程序都是从主函数的第一个语句开始执行,在需要调用函数的地方才去调用。
int main()括号内无参数意味着main函数为无参函数。
return 0;意味着返回一个int类型,值为 0.意味着main函数返回0 告知计算机程序正常中止。
2.6.3 以数组作为函数参数
- 数组也可以作为函数参数,且参数中数组的第一维不需要填写长度(如果时二维数组,则第二维需要填写长度),积实际调用时写只需要填写数组名。
重要的是,数组作为参数时,在函数中对数组元素的修改等同于对原数组元素的修改。这与普通的局部变量不同。例如排序算法对数组的调用。
另外,数组可以作为参数传递,但是不可以作为返回类型出现。
2.6.4 函数的嵌套
- 嵌套指的是在一个函数中调用另外一个函数。
2.6.5 函数的递归调用
- 递归指的是自己调用自己的过程。
2.7 指针
2.7.1 什么是指针
变量在内存中如何存放:在计算机中,每个字节都会有一个地址,计算机通过地址找到某个变量。
例如int类型占用 4 个字节,则有
如何获取变量地址?通过取地址运算符 ‘&’.在变量前面加上取地址运算符,就可以表示变量的地址。
- 指针实际上是一个无符号类型的整数。
2.7.2 指针变量
- 指针变量是用来存放指针(或者说是地址)的变量。
定义格式举例:int *p; double *dp; char *cp;,在某种数据类型后面添加型号* 来表示这是一个指针变量。
注意,型号的位置在数据类型之后或者变量名之前都是可以的,编译器不会进行区分。
举例2:int* p1,p2;其中p1为int*型变量,而p2是int型变量。
举例3int* p1, *p2;其中p1为int*型变量,而p2是int*型变量。 指针变量的使用:
取地址:例如,int *是指针变量类型,pa与pb为变量名,&a,&b分别赋值给pa,pb
int a; int *pa = &a; //--------或者写成 int b; int *pb; pb = &b;地址对应的元素:例如
int a =233; int *pa = &a; printf("%d", *p)
输出结果为
233.
同时,也可以直接对*p进行赋值,这样一来 a中的元素值也发生了改变。指针变量的一些操作
- 指针变量可以进行加减法
例如对于int *p;而言 p + 1指的是p所指向的int类型变量的下一个int型变量的地址,跨越了一个int型(4 Byte).
两个指针变量的减法意味着两个地址偏移的距离,这个偏移距离指的是相差几个 ElementType。 - 指针变量支持自增和自减操作。
- 指针变量可以进行加减法
基类型:对于指针变量而言,把其存储的地址的类型称为基类型。基类型必须和指针变量存储的地址类型相同。
2.7.3 指针与数组
- 在之前对数组的讨论中提到过,数组是由地址上连续的若干个相同类型的数据组合而成的。对于int类型数组a而言,数据在地址上是连续的。这样我们可以通过地址运算符 ‘&’来获得他们的地址。
- 在 C语言中,数组名称也可以作为数组的首地址来使用, 故存在以下关系成立:
- a = &a[0].因此有 *a = a[0] 成立。
- a + i = &a[i].因此有 *(a+i) = a[i] 成立。
2.7.4 使用指针变量作为函数参数
指针类型可以作为函数参数的类型,此时视为把变量的地址传入参数。如果在函数中对这个地址中的元素进行改变,原先的数据就会确实地被改变。
例如:void change( int* p){ *p = 100; } int main(){ int a = 1; change(&a); cout<<a; return 0;}则最终输出结果为
100.
上述代码中,change函数把int型变量a的地址传入,p指向a的地址,修改了a本身。这种传递方式被称为地址传递。一个经典的例子:使用指针作为参数,交换两个数。
正确写法:void Swap( int* p,int* q){ int c ; c = *p; *p = *q; *q = c; } int main(){ int a = 1,b=2; Swap(&a ,&b); cout<<a<<' '<<b; return 0;}此时输出的值为
2 1.这里把a,b的地址作为参数传送,Swap直接把地址中存放的数据进行操作,这样交换操作会改变main函数中的a和b的值。
错误写法:void Swap( int p,int q){ int c ; c = p; p = q; q = c; } int main(){ int a = 1,b=2; Swap(a ,b); cout<<a<<' '<<b; return 0;}上述代码中,因此函数在接收参数的过程中,仅仅是单项一次性的值传递,在调用Swap函数时,相当于产生了一个副本,而这个副本的操作不会影响主函数中 a b的值。
错误写法2:void Swap( int* p,int* q){ int* c = p; p = q; q = c; } int main(){ int a = 1,b=2; Swap(&a ,&b); cout<<a<<' '<<b; return 0;}上述代码中,思想是:直接把两个地址交换。创作这个代码的人认为,直接交换两个地址后,元素值自然也就交换了。但是,由于在swap函数中,main传给它的地址其实也是一个无符号整型的数字,其自身跟普通变量一样也只是值传递。swap对 *p,*q的修改不会导致main函数中地址的改变,main像swap函数传递的只是两个变量地址的副本而已。
2.7.5 引用
引用:这是 C++的一个强力语法。 对引用变量的操作就是对原变量的操作。引用不产生副本,而是给原变量起了个别名。
使用方法:在函数的参数类型后面(或者变量名前面)加一个 &即可。
例:void change( int &x){ x = 100; } int main(){ int a = 1; change(a); cout<<a; return 0;}输出结果
100引用不是取地址,要把引用的&跟去地址运算符&区分开来。
指针的引用
在2.7.4节错误写法2中,代码试图交换地址来达到交换变量的效果,但是由于对指针变量本身的修改无法作用到原指针上而导致失败。此时,我们可以通过应用的方式实现交换效果。void Swap( int* &p,int* &q){ int* c = p; p = q; q = c; } int main(){ int a = 1,b=2; int *pa = &a,*pb = &b; Swap(pa ,pb); cout<<*pa<<' '<<*pb; return 0;}由于引用是产生变量的别名,因此常量不可以使用引用。
2.8 struct的使用、
2.8.2 struct的定义
格式:
struct Name{//空白部分填入自定义的数据类型 };例如:
struct studentInfo{ int Id; char Gender; char Name[20]; char Major; }Alice,*Bob,stu[1000]; studentInfo Lucy;- 结构体内部可以定义除了自己本身(这样会引起循环定义的问题)之外的任意数据类型。
不过,虽然不能定义本身,但是可以定义自身类型的指针变量。
例如:
sturct node{
//不可以定义 node n;
node* next;//可以定义node*型指针变量
2.8.2 访问结构体内的元素
- 两种方法:
- 使用 “.” 操作访问 Lucy 中变量,例如:
Lucy.Id;Lucy.Name; - 使用 “->” 操作访问指针变量 *Bob中元素,例如:
*Bod.Name;Bob->Id;
- 使用 “.” 操作访问 Lucy 中变量,例如:
- 结构体指针变量内部元素的访问对于使用 “.”和”->” 的写法是完全等价的。
2.8.3 结构体的初始化
定义结构体变量之后,对其元素进行逐一赋值。
例如Lucy.Id = 001;Lucy.Gender = 'M';或者在读入时进行赋值,例如scanf("%d %c",&Lucy.Id,&Lucy.Gender);另外一种比较简单的方法:构造函数,它就是用来初始化结构体的一种函数,直接定义在结构体中。它的一个特点是不需要写返回类型,并且函数名和结构体名相同。
一般而言,对于一个普通定义的结构体,在内部都会生成一个默认的构造函数(但是不可见),由于这个构造函数的存在,才可以直接定义结构体类型的变量而不进行初始化(因为它没有让用户提供任何初始化参数).
例如:struct studentInfo{ int Id; char Gender; //默认的构造函数 studentInfo(){} };可以如下进行赋值:
struct studentInfo{ int Id; char Gender; //默认的构造函数 studentInfo( int a, char b){ Id = a; Gender = b; } };或者将构造函数简化为一行:
struct studentInfo{ int Id; char Gender; //默认的构造函数 studentInfo( int a, char b):Id(a),Gender(b);{ } };注意,如果自己重新定义了构造函数,则不能不经初始化就定义结构体变量。
2.9 补充
2.9.1 cin与cout
- cin和cout 是C++中输入函数,需要添加头文件
#include<iostream>,它们的优点是使用方便。 cin:c和in的结合
例如:int a; double b; char str[10]; string str2; cin>>a>>b; cin.getline(str,10); geline(cin,str);cout:c和out的结合
例如:cout<<a<<b<<str<<str2<<'\n'<<endl;如果需要控制精度时,需要加上头文件
#include<iomanip>按照以下格式输出:
cout<<setiosflags(ios::fixed)<<setprecision(2)<<123.4567;此时输出结果为123.46.cin和cout在输出/输出大量数据时表现非常糟糕,建议使用scanf和print输出。在十分必要的时候才使用cin和cout.
2.9.2 浮点数的比较
- 由于计算机采用的是二进制形式的编码,因此浮点数在计算机中的存储并不是很精确。一些浮点数,例如3.14可能存储为3.1400000000001,也有可能存储为3.1399999999999,这种情况下对于比较操作会带来极大的困扰,需要引入一个极小数eps来对误差进行修正。经验表明,eps取
是一个合适的数字。故可定义为,
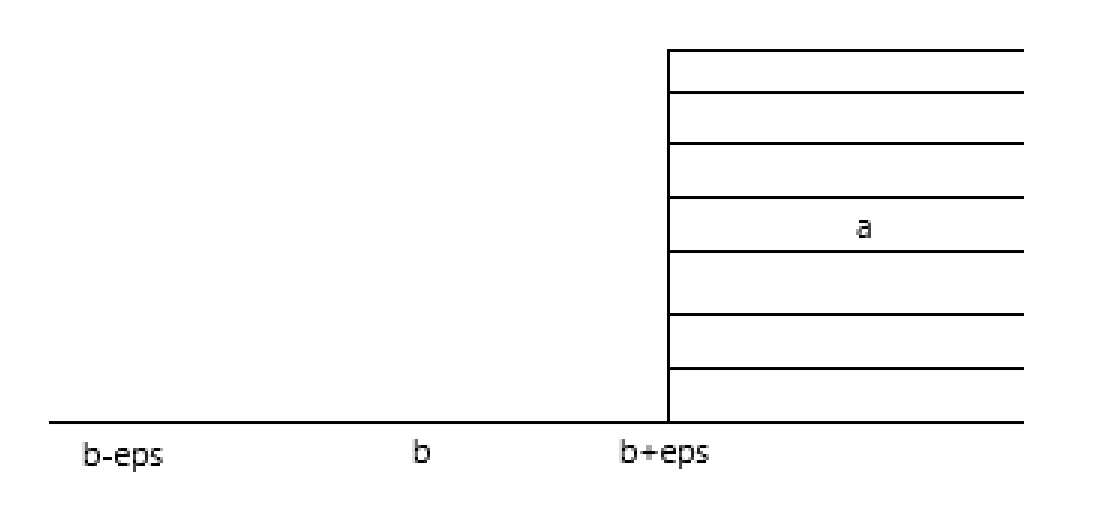
const int eps = 1e-8; 等于运算符 ==

上图表示了等于区间的示意图。如果一个数a落在了[b-eps,b+eps]的区间上,那么就应该判定为 a == b 成立。
上述比较操作可以写成宏定义的方式#define Equ(a,b) ( ( fabs( (a) - (b)) ) < (eps) )
如果 a - b 的绝对之差小于eps,则返回true。加如此多的括号是为了降低宏定义可能出现的错误。
注:- 如果想使用不等于,那么直接使用 (!Equ) 即可,如此一来便可以对浮点数进行比较了。
- 另外,如果进行比较简单的比较,例如 1.23 == 1.23 ,那么直接使用 “==”可以输出正确的结果,但是如果一个变量进行了一个误差比较大的运算之后,精度的损失就不可以忽视了,例如
#include<bits/stdc++.h> #define Equ(a,b) ((fabs((a)-(b)))<(eps)) using namespace std; double eps = 1e-8; int main(){ double a = 4 * asin(sqrt(2.0) /2); double b = 3 * asin(sqrt(3.0) /2); printf("%.20lf\n%.20lf\n",a,b); int c = a == b; cout<<c; c = Equ(a,b); cout<<endl<<c; return 0;}
输出结果为
3.14159265358979360000 3.14159265358979310000 0 1- 大于运算符 >
如下图:
宏定义为:#define Equ(a,b) ( ( (a) - (b) ) > (eps) ) - 小于运算符 <
如下图:
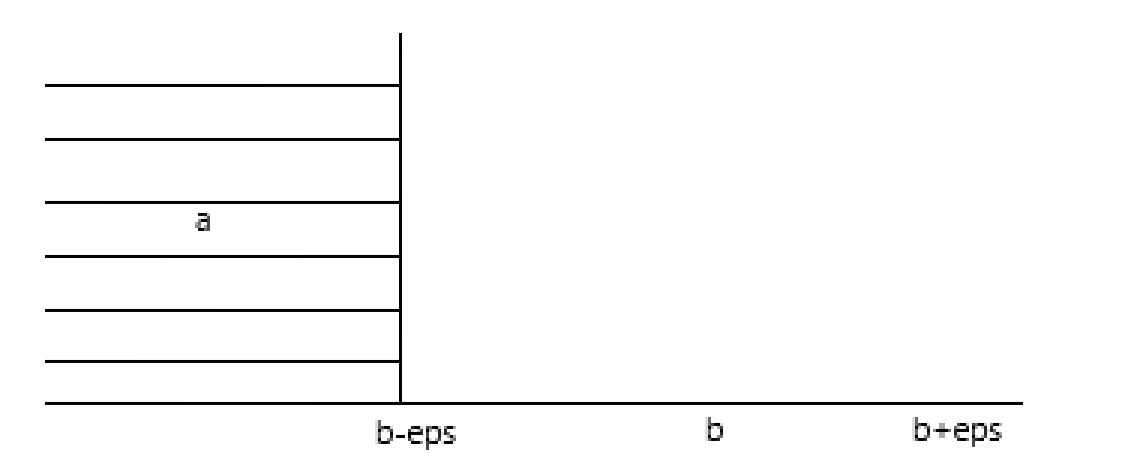
宏定义为:#define Equ(a,b) ( ( (a) - (b) ) < (-eps) ) - 大于等于运算符 >=
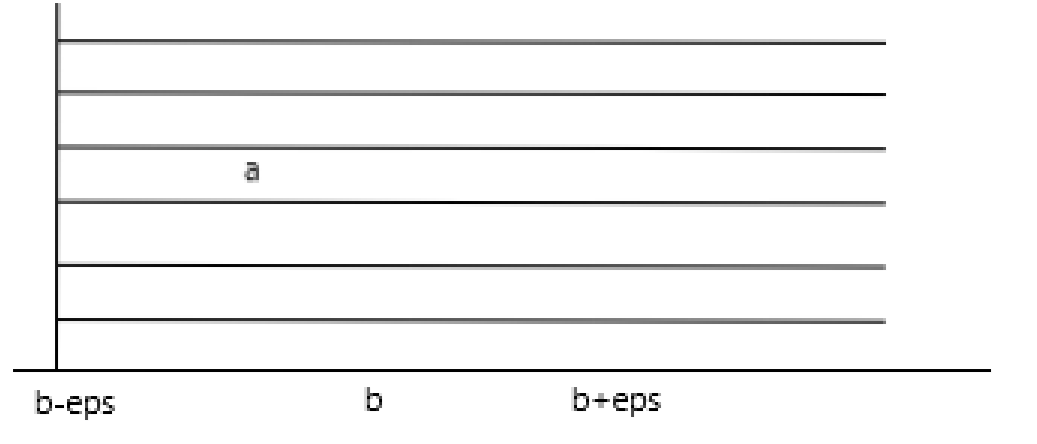
宏定义为:#define Equ(a,b) ( ( (a) - (b) ) > (-eps) ) - 小于等于运算符 <=
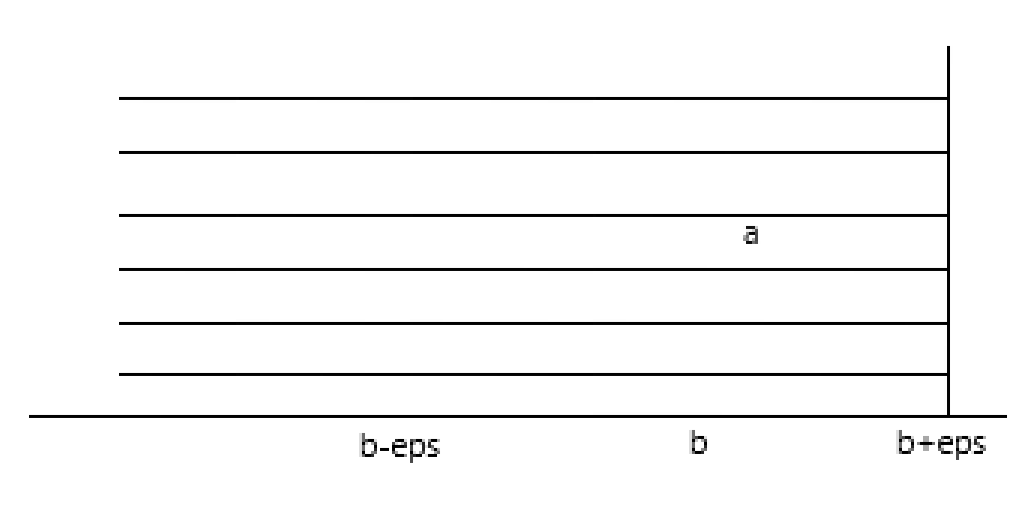
宏定义为:#define Equ(a,b) ( ( (a) - (b) ) < (-eps) ) 圆周率
无需死记,可以依据 推出 .一些需要主要注意的地方:
- 由于精度问题,在经过大量计算之后,可能在一个变量中存储的0是一个很小的负数,这时候对它开根号,可能会因为不在定义域内而出错。
同样的问题可能出现在asin(x) 当x = +1,或者acos(x)当x = -1时。这种情况需要使用eps保证变量在定义域内。 - 在某一些由编译环境产生的原因下,本应该为0.0的变量在输出时会变成-0.00,这个问题是编译环境本身的bug,只能把结果存放在字符串中,然后与-0.00比较,如果比对成功,则加上eps来修正为0.00.
- 由于精度问题,在经过大量计算之后,可能在一个变量中存储的0是一个很小的负数,这时候对它开根号,可能会因为不在定义域内而出错。
2.9.3 复杂度
时间复杂度:
时间复杂度是评价算法时间效率的有效标准。是算法需要执行基本运算次数所处的等级。
一些性质:- 系数不影响增长趋势,例如 与 是等价的。
- 高等级的幂次会覆盖低等级的幂次。例如 .
- 对数的时间复杂度可以省略底数。可以由换底公式证明。
-
时间复杂度的分析: - 对于一般的OJ系统而言,一秒钟能承受的运算次数约为 ,这就是说,如果是 的时间复杂度,测试数据最大为 1000 规模。当超过1000规模,需要考虑优化算法。
空间复杂度
表示算法需要消耗的最大空间数据。
例如,二维数组的空间复杂度为 , 空间复杂度指的是算法消耗的空间不随着数据的规模增大而增大。一般而言,空间都是足够用的(但是类似于 int A[1000][1000] 的定义就有点过分了)。编码复杂度
这是一个定性的概念,没有量化的标准。但是很明显,没有人愿意阅读冗长的算法。
2.10 黑盒测试
黑盒测试:系统后台会准备若干组测试数据,然后让提交的程序运行这些数据,如果输出结果与正确答案完全相同(字符串意义的比较),那么通过测试。否则会依据错误类型返回不同的结果。
依据是否对每组数据都单独测试或者一次性分为所有测试数据,分为单点测试和多点测试。单点测试
系统会判断魅族数据的输出结果是否正确。若输出正确,则对于改组数据而言便通过测试,并获得相应分值。
从代码编写而言,单点测试只需要按照正常逻辑执行一遍程序即可。多点测试
要求程序一次性运行完所有的数据,并要求结果全部正确。这种方式考验代码的严谨程度。由于一次性执行完所有数据,我们需要有办法反复执行代码的最核心部分,这便是循环。
三种输入方式:- while…EOF型
如果题目没有给定输入的结束条件,便需要默认读取到文件末尾。
scanf函数的返回值为其成功读入参数的个数。例如:scanf("%d",&n);读入成功时返回值为1,scanf("%d%d",&n,&m);读入成功时返回值为2.
当黑盒测试中输入数据的文件执行到末尾时候,scanf读入完毕,返回值为-1(要知道,正常控制台中的输入一般是不会失败的),在C语言中使用EOF(end of file)代表-1.
代码格式:
while( scanf("$d,&n) != EOF){ ... }
在控制台输入数据时,如果想要手动触发EOF 需要按xi <Ctrl + Z>组合键这时候会显示 ^Z 再按下<Enter>便可以结束while.
另外一点,如果读入字符串,则有
scanf("%s",str);和gets(str);两种方式,对应的写法如下:while( scanf("$s,str) != EOF){ ... } while( gets(str) != NULL){ ... }2.while…break类型
是 while…EOF的延申,题目要求输入数据满足某个条件时候停止输入使用。
3.while(T–) 类型三种输出方式:
- 正常输出
每两组输出数据之间没有额外的空行。即输出数据是连续的空行。 - 每组数据输出之后额外加一个空行
- 两组数据输出之间有一个空行(空格),最后一组数据之间没有空行(空格)。
这种情况一般处于while(T–)的输入方式下,可以使用if(T!=0) cout<<endl;解决。
- while…EOF型
注意:在多点测试中,每一次循环都需要重置一下变量和数据,否则下一组测试数据来临时变量和数组的状态便不是初始状态。重置数据一般使用memset函数或者fill函数。
