hadoop完全分布式模式:hadoop的守护线程在不同的服务器上(具体定义请自行查询)
本机部署:实在前一篇文章伪分布式部署下进行操作的:
伪分布部署链接:https://blog.csdn.net/weixin_39435629/article/details/84841252
前期准备:
本机使用虚拟机测试:故需要继续构建几台服务器,通过克隆的形式,(jdk无需配置,hadoop的基本环境已构建)
复制三台服务器:
准备一:设置ip和hostname
| ip |
hostname |
| 192.168.44.102 | h102 |
| 192.168.44.103 | h103 |
| 192.168.44.104 | h104 |
备注:关于固定服务器的ip和hostname 建议查看博客。
链接:https://blog.csdn.net/weixin_39435629/article/details/84861344
准备二;使h101可以免登录进入h102,h103,h104
博客链接:https://blog.csdn.net/weixin_39435629/article/details/84847685
准备三: 建立hostname与ip的链接 (注意四台服务器均得修改)

前期准备测试:
ip结果:




SSH结果:

再进行正式部署之前,为了方便可以在h101上直接查看剩余三台服务器的状态,同时为了分发文件时候的方便,书写两个脚本,
也可省略,但后续的相关操作,请自行分发或依次在服务上执行查看状态
脚本编写链接:https://blog.csdn.net/weixin_39435629/article/details/84871851
服务器配置hadoop守护进程介绍:
h101 主服务器 namenode(名称节点) secondaryname (辅助名称节点) resourcemanager(资源管理器)
h102 副服务器 datanode(数据节点)nodemanager(数据节点管理器)
h103 副服务器 datanode(数据节点)nodemanager(数据节点管理器)
h104 副服务器 datanode(数据节点)nodemanager(数据节点管理器)
1、复制伪分布配置(pseudo)为full文件

2、配置详情(在h101上操作)
1) core-site.xml 修改(fs.defaultFS)属性
原来:
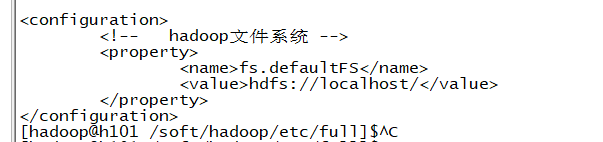
之后:使用hostname代替

2)hdfs-site.xml 修改(dfs.replication)属性(副本数) 为3
原来:

之后:

3)查看yarn-site.xml 中 yarn.resourcemanager.hostname 属性,是否为本机(h101)主机名
原来:

4)设置当前目录的slaves文件

原来:

之后:添加数据节点的hostname

3、重新建立hadoop与full的链接
之前:

之后: 命令:$>ln -snf /soft/hadoop/etc/full hadoop (强制替换原来的链接)

4、通过xsync.sh 将编写的full文件分发到剩余服务器(若是没有,请手动一个个复制到其余服务器中)
切记注意full后的斜杠要去掉(加“/”复制文件里的内容 不加“/”复制该文件)

结果:



5、执行xcall.sh(批量执行脚本) 将full与hadoop建立软连接



6、将日志文件(/soft/hadoop/logs)内和以前的数据文件(/tmp)文件内 全部删除 注意(四台服务器上均执行)


7、格式化数据节点(h101上操作)

8、在h101上执行命令:$>start-all.sh (启动四台服务器上的hadoop的几大守护进程)

9、页面验证:

查看数据节点个数:



备注:一般按此hadoop版本(2.9.1)的配置基本没问题,如果有报错,请大家验证hostname与ip的配置是否正确,
一次检查每个配置文件。然后记得验证步骤(1、停掉所有的hadoop的守护进程(或kill掉)2、删除日志文件(logs)和数据文件(/tmp)3、格式化名称节点 4、然后重启hadoop验证 )
一般自己联系时设置三个数据节点(h102,h103,h104),但实际使用的时候建议配置至少四个数据节点(防止有挂掉的)
配置文件汇总:(/etc/full文件下)






命令汇总:(一般常在主服务器上执行 h101)
$>hadoop-daemon.sh start namenode (单独启动名称节点)
$>hadoop-daemons.sh start datanode (启动多个名称节点)
$>hdfs namenode -format (格式化名称节点)
$>jps (查看hadoop的守护进程 xcall.sh jps (将多台服务器的hadoop的守护进程集中显示))
$>hdfs (查看hdfs 命令的帮助 )
$>hdfs dfs (查看 hdfs dfs 命令的帮助)
备注:也可将辅助名称节点(secondarynamenode) 部署到另外的服务器上 (后续HA高可用会进一步介绍 )。