1.测试数据准备
首先导入本地准备的spam文件
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.optimizers import RMSprop
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.utils import to_categorical
from keras.callbacks import EarlyStopping
%matplotlib inline
df = pd.read_csv('spam.csv', delimiter=',', encoding='latin-1')
df.head()
打印结果如下
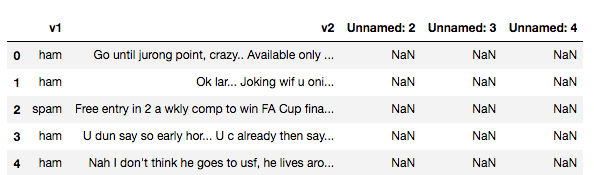
能观察到Unnamed:2~4几列,有空多空数据,所以我们需要将这几列删除
df.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1, inplace=True)
再次打印

我们可以用seaborn观察一下数据集label的分布
sns.countplot(df.v1)
plt.xlabel('Label')
plt.title('Number of ham and spam messages')

然后我们将v2值存入X,将v1存入Y,因为v1值都是ham和spam,所以我们用LabelEncoder将其全部转为0或1的整数数组
X = df.v2
Y = df.v1
le = LabelEncoder()
Y = le.fit_transform(Y)
Y = Y.reshape(-1,1)
将测试数据集分成训练数据和测试数据
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.15)
2.搭建测试模型
首先我们先确定词库的最大长度(1000),以及每条短信的最大长度(150),然后使用Tokenizer将短信拆成单词
max_words = 1000
max_len = 150
tok = Tokenizer(num_words=max_words)
tok.fit_on_texts(X_train)
sequences = tok.texts_to_sequences(X_train)
sequences_matrix = sequence.pad_sequences(sequences, maxlen=max_len)
定义网络模型
def RNN():
inputs = Input(shape=[max_len])
layer = Embedding(max_words, 50, input_length=max_len)(inputs)
layer = LSTM(64)(layer)
layer = Dense(256)(layer)
layer = Activation('relu')(layer)
layer = Dropout(0.5)(layer)
layer = Dense(1)(layer)
layer = Activation('sigmoid')(layer)
model = Model(inputs=inputs, outputs=layer)
return model
生成网络
model = RNN()
model.summary()
我们可以观察一下网络结构

3.模型训练
model.compile(loss='binary_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])
model.fit(sequences_matrix, Y_train, batch_size=128, epochs=10, validation_split=0.2, callbacks=[EarlyStopping(monitor='val_loss', min_delta=0.0001)])
可以看到,由于我们设置了EarlyStopping,模型在循环2次后,val_loss就开始增大,所以模型停止了训练。

我们可以在测试数据集上看一下模型的准确率
test_sequences = tok.texts_to_sequences(X_test)
test_sequences = sequence.pad_sequences(test_sequences, maxlen=max_len)
accr = model.evaluate(test_sequences, Y_test)
print('Test set\n Loss: {:0.3f}\n Accuracy: {:0.3f}'.format(accr[0], accr[1]))
可以看到在测试数据上loss为0.043,准确率已经达到了99.0%

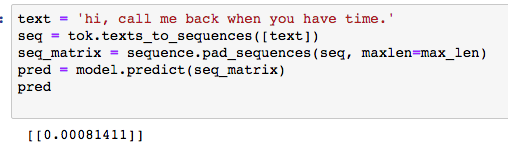
最后我们可以自己写一条短信进行测试:hi, call me back when you have time.
text = 'hi, call me back when you have time.'
seq = tok.texts_to_sequences([text])
seq_matrix = sequence.pad_sequences(seq, maxlen=max_len)
pred = model.predict(seq_matrix)
可以看到,这条短信是垃圾短信的概率只有0.08%
到这里,垃圾短信识别的功能就全部实现了。
所有代码及测试数据已上传至git,点击这里可直接查看,有疑问的同学请在博客下方留言或提Issuees,谢谢!