论文地址:https://www.ijcai.org/Proceedings/11/Papers/392.pdf
简介
当训练集中带标签数据很少,无法训练出一个较好的分类模型时,我们就会希望通过迁移学习能够从其他的辅助域中迁移出有利于目标任务的知识来辅助建立目标分类器,现有的大多数迁移学习方法都是手动的选择一个或者多个辅助域来进行迁移,那如果有一种迁移学习方法能够自动选择出这些辅助域是一件多棒的事情!有了这个能力,就可以将网络这一片数据海洋的资源利用起来了,想想,网络自动选择使用那些数据,并且数据来源可以来自于网络,这是不是可以越来越接近黑客帝国中的智能中心了,无尽的数据,通过自动迁移筛选,可以完成各种任务,cool!这就是Source-Selection-Free Transfer Learning(SSFTL)想要完成的目标,尽管SSFTL不能做到我们想象的那一步,但是确实是迈出了一小步。
在该方法中,应用场景是文本识别,其中并不需要用户给出特定的源域数据集用来进行目标分类任务,因为辅助域数据可以从网络上获取。作者假设网络上的信息源和目标任务拥有相同的特征空间(使用的字典相同),但是标签域可能不同( ),甚至是互斥的。然后为了帮助在 和 之间进行桥接,这里假设有一个社交媒体集合,这些社交媒体通过标记 打上标签,以至于 与 是重叠的,同时, 又是 的一个子集。SSFTL的目标就是在 和 进行桥接,然后从源域中选出一个子集用来作为迁移数据,将知识迁移到目标任务。
为了在 和 建立一作有效的桥,作者使用图形表示将所有标签嵌入到潜在的欧几里德空间中,然后标签之间的关系就可以使用这个潜在空间中对应的标签原型(被映射后的标签)之间的距离进行表示。将每个源分类器的标签预测结果也映射到潜在空间中,这样也可以通过这之间的距离可以抉择出那些源域数据是与目标标签(目标任务)是有利的。最后,再通过一个正则化框架来学习一个有效的分类器来对目标文本进行分类。这稍微有点绕,我们看下面的详细内容吧。
Source-Selection-Free Transfer Learning
像上面所说,假设我们有少量的带标签目标数据 以及丰富的无标签数据 。在辅助域中,有k个精光预训练的分类器{ }。辅助域和源域有着相同的特征空间(使用相同的字典)。另外,假设有一些社交媒体集合,例如Delicious,它包含了很多标记 , 覆盖了所有目标域和源域中的标签( and ),SSFTL的目标是通过利用这些辅助分类器以及社交媒体数据来训练一个目标分类器。
SSFTL需要解决两个问题:
- 在辅助域和目标域的标签之间进行桥接
- 使用经过预训练的源域分类器学习到的源域与目标域之间的关系训练一个目标分类器
第一步,利用社交标记数据,构建一个标签图,然后通过图形嵌入来学习标签的潜在低维空间。第二步,通过一个正则化框架传递源分类器中编码的知识。
构建标签嵌入图
为了利用社交媒体数据中的潜在图框架,作者在图上应用了图谱技术[Chung,1997]将图中的每个点映射到了一个低维潜在空间。通过这样,每个标签将在这个潜在空间上有一个坐标,称这个坐标为该类的"原型(Prototype)"。因为这样一个潜在空间的维度比起原特征空间来说可能太低了,由标签稀疏性导致的误匹配问题可能会减轻。然后各类别之间的关系,比如相似或者不相似,可以通过在潜在空间中他们对应的原型之间的距离进行表示。
那么就是需要获得一个潜在特征空间表示矩阵,这个潜在特征空间表示矩阵怎么获取呢?作者使用了Laplacian Eigenmap[Belkin and Niyogi,2003]来构建这个矩阵V。给出标签图 以及它的权重或者邻接矩阵M,Laplacian Eigenmap 旨在通过解决以下的优化问题来学习V,然后这个V就是我们的标签嵌入图:
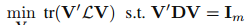
其中D是一个对角矩阵,然后 是拉普拉斯矩阵[Belkin and Niyogi,2003]。 则是一个m维的单位阵。注意到如果两个标签原型之间的距离越小,那么也就表示这两个标签在语义上也是相似的。因此,基于潜在空间中标签原型的距离,我们就可以在域间进行知识迁移。
知识迁移(用于自动选择源域的正则化框架)
在目标分类任务中,目标是学习一个分类器 ,在文中g(x)是一个线性模型,可以被写为 。

因为目标域中有标签的数据较少,因此我们需要通过所有辅助域分类器的结合来帮助目标分类器在无标签数据上做预测:
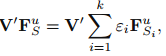
其中 是辅助域分类器在目标域无标签数据 上的预测结果,然后 表示为这些辅助域分类器的权重。
在潜在空间中,目标域标签原型也许会被辅助域标签原型包围或者分离,这意味着辅助域分类器也许会对目标分类器g(x)有帮助。因此,通过结合经过映射后的辅助域分类器,可以用于正则化在无标签数据上的目标分类器,如下:

其中 为无标签数据矩阵。
最后获得以下优化问题:
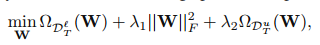
其中:
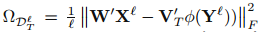
这是一个在有标签矩阵上的损失函数,然后 就是对应的标签矩阵。然后 是一个正则化项用于避免过拟合。然后从辅助域中迁移的知识被编码在 里面,源域和目标域标签之间的关系则被编码在V里面。
好了,通过以上的优化,就可以训练处目标分类器g(x)对目标数据进行分类了。
总结

SSFTL对源域中每个类预训练一个分类器—>通过网上的社交媒体标记数据 构建一个标签图—>将源域和目标标签映射到该图空间中—>计算标签之间的距离代表标签之间的关系—>通过这些关系(使用 衡量)将源域分类器结合来帮助优化目标分类器g(x)。
SSFTL实现了通过网络数据来辅助目标分类器对目标任务进行分类,其源域为网络数据,同时使用了一个覆盖了源域和目标域所有标签的线上社交媒体数据Delicious来构建嵌入图以衡量标签之间的关系,这样就可以选出与目标域标签类似的源域标签,进而可以选出那些与目标域数据相似的源域数据,通过这样优化以训练目标分类器。但是该方法也许具有一定的局限性,比如特征空间相同、 覆盖了所有域的标签等。但也算是打开了迁移学习使用网络数据进行迁移应用的一扇大门。
参考
Xiang E W, Pan S J, Pan W, et al. Source-selection-free transfer learning[C]// International Joint Conference on Artificial Intelligence. AAAI Press, 2011:2355-2360.