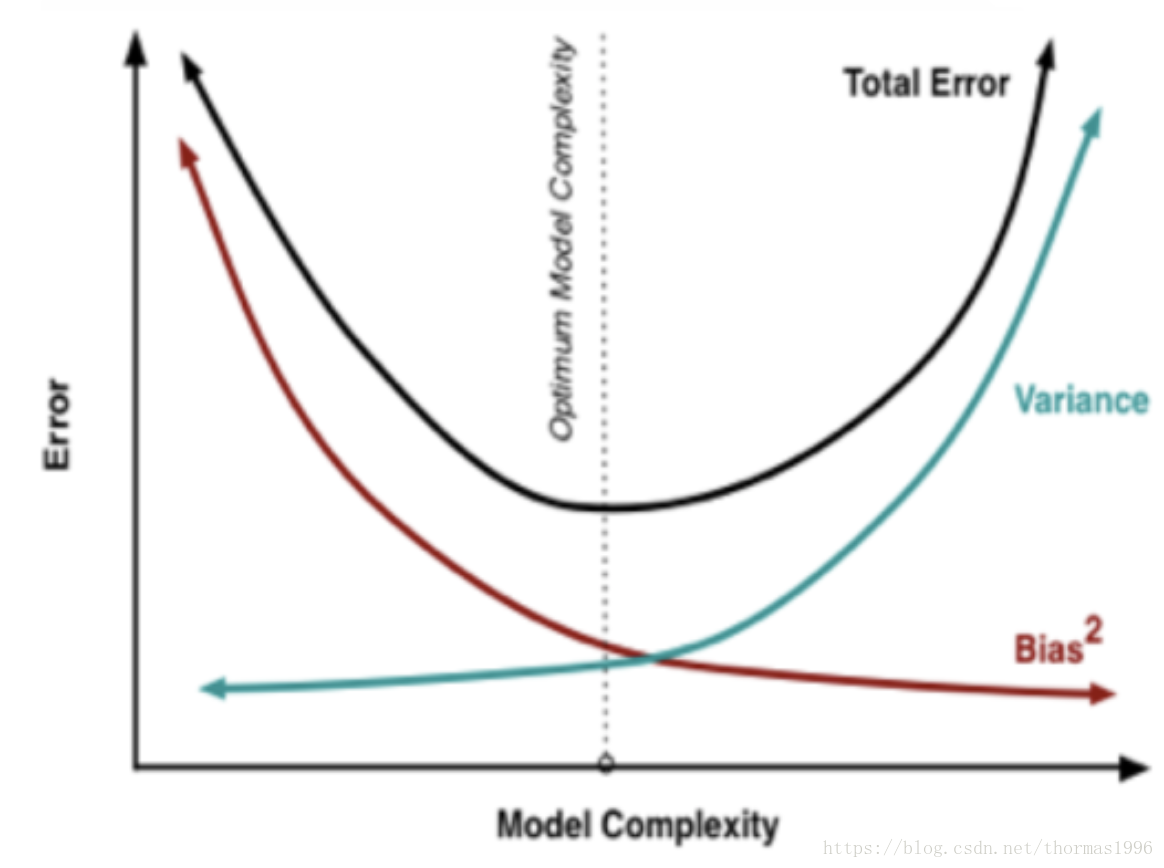
偏差和方差
- 在统计学习框架下,Error = Bias + Variance。Error指的模型的预测错误率,由两部分组成,一部分是由于模型太简单而带来的估计不准确的部分(Bias),另一部分是由于模型太复杂而带来的更大的变化空间和不确定性(Variance)。
- 如果要降低模型的Bias,就一定程度上会提高模型的Variance,反之亦然。根本原因是如果我们更相信训练数据的真实性,忽视对模型的先验知识,就会保证模型在训练样本上的准确度,这样可以减少模型的Bias,但这样会使模型的泛化能力不够,导致过拟合,降低模型在真实数据上的表现,增加模型的不确定性。反之,如果我们更注重模型的先验知识,在学习模型的过程中对模型增加更多的限制,就可以降低模型的variance,提高模型的稳定性,但也会使模型的Bias增大。
- 模型太简单:欠拟合;模型太复杂:过拟合。
抑制欠拟合与过拟合方法
欠拟合主要是因为模型太简单,不能很好地捕捉模型特征。
- 添加其他特征项让模型学习
- 使模型更复杂,比如说对一个线性模型添加多项式特征等
- 减少正则化参数
过拟合主要是因为模型太复杂,过度拟合训练数据,或是训练数据太少,导致模型不能很好地学习到全局特征。
- 清洗数据,去掉outliner
- 扩大数据集,包括从数据源头采集更多数据,复制原有数据并加上随机噪声,重采样,根据当前数据集估计数据分布参数,使用该分布产生更多数据等方法
- Early stopping,当valid准确率不提高时适时停止
- 正则化,包括L0正则、L1正则和L2正则
- dropout
L1与L2正则化说明和区别
L0范数:向量中非0元素的个数。
L1范数(Lasso Regularization):向量中各个元素绝对值的和。
L2范数(Ridge Regression):向量中各元素平方和求平方根。
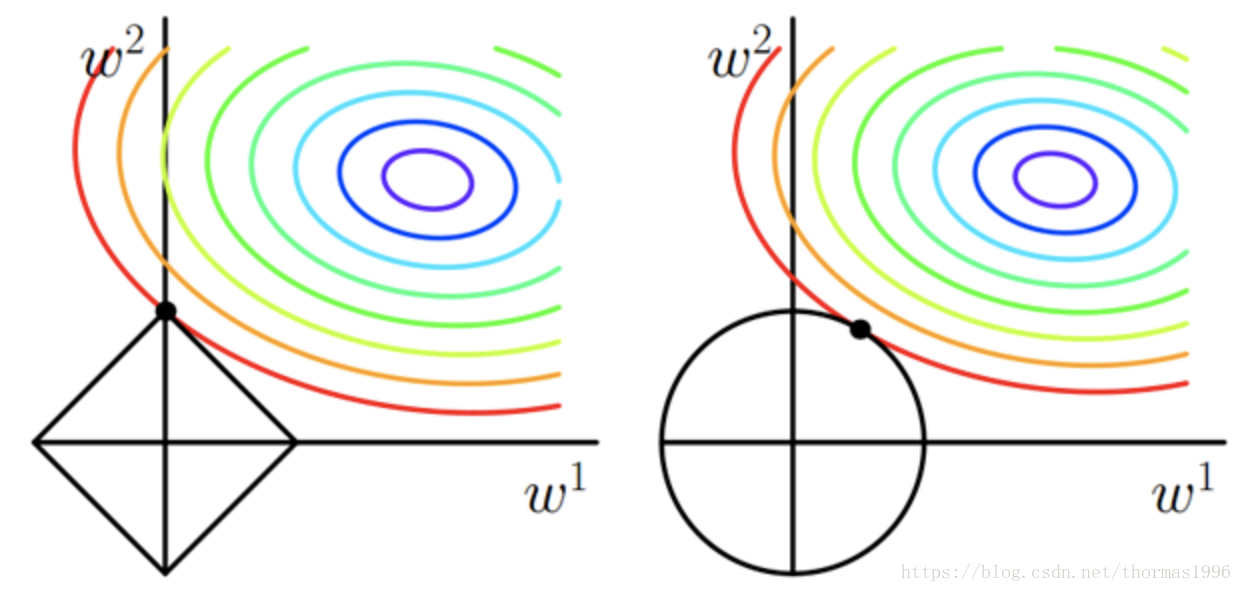
L1正则化也叫Lasso回归(图左):
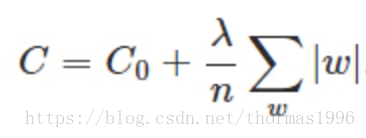
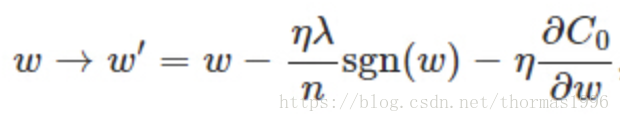
可以看到如果ω为正,那么L1使ω减小,反之ω为负,L1使ω增大,也就是L1会让ω趋向于零,因此产生稀疏解。网络参数越多为零,可以认为模型越简单,有助于抑制过拟合。
缺点是在原点无法求导,一般人为定义为原点导数为零。
L2正则化也叫Ridge回归(图右):
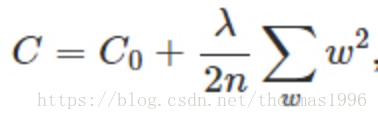
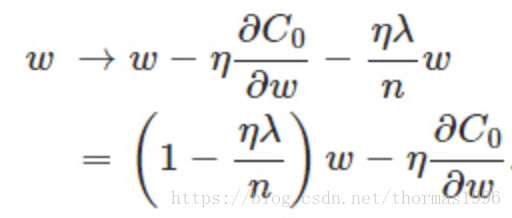
会使ω变小,参数变小一般可以认为使模型更简单,从而减小过拟合。并且L2正则化可以让优化求解变得稳定很快速(这是因为加入了L2范式之后,满足了强凸)。
为什么有助于让优化求解变得稳定很快速的原理可见:https://blog.csdn.net/zouxy09/article/details/24971995
L2对outliner更加敏感,outliner在图上就是离原点更远,惩罚就越大,所以L2会让解更加稠密,向原点靠拢。一般来说,L2在抑制过拟合的表现比L1好。
知乎上对为什么参数值变小能抑制过拟合有一个更为数学上的解释:
过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
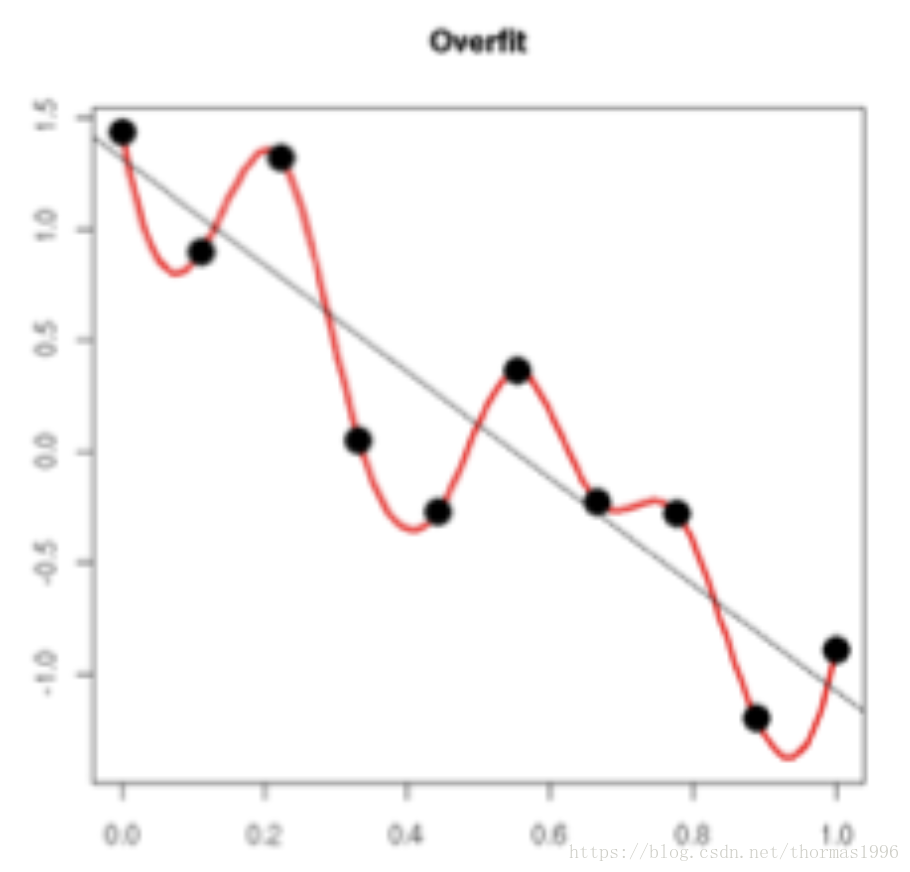
正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
从统计概率的角度来看,L1 Norm和L2 Norm其实对向量中值的分布有着不同的先验假设:
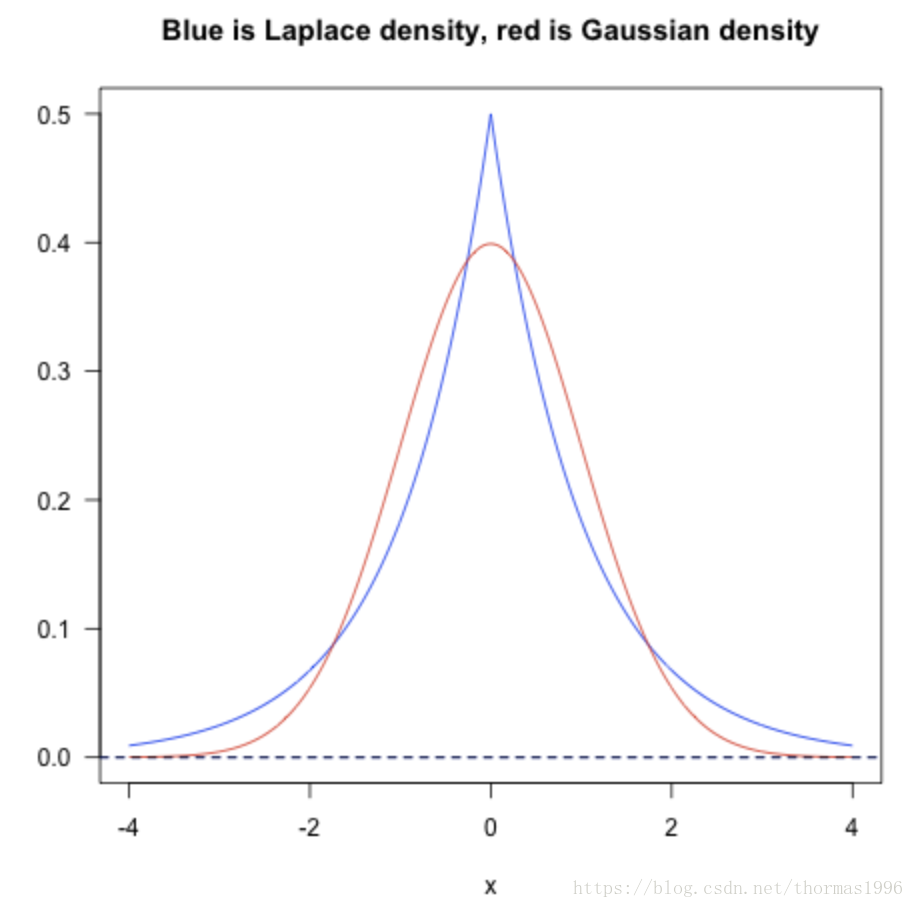
蓝色是L1,红色是L2,L1认为是拉普拉斯先验,L2认为是高斯先验。可以看出L1对极端情况,也就是outliner忍受度更高。
如何从拉普拉斯和高斯先验推出L1和L2正则化可见:http://www.cnblogs.com/heguanyou/p/7688344.html
稀疏解的优点
- 能实现特征的自动选择,能自动过滤掉很多相关性低的特征
- 更少的特征意味着模型更容易解释
梯度下降算法
SGD 震荡很厉害
Momentum 改变一阶项,考虑之前的batch的影响,能够在相关方向加速SGD,抑制振荡,从而加快收敛
Ada 学习率自适应的方法,通过二阶项的约束,前期加大梯度,后期减小梯度,使得更快收敛。问题是分母的累加可能导致梯度消失太快,提前结束训练
Adadelta 减少了分母的累加
Rmpop Adadelta的一个变种,善于处理非平稳目标
Adam 结合了Momentum和Ada,结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点,效果是最好的
如何避免局部最小?
- 用多个初始值,选择误差最小的参数作为最终结果
- 模拟退火,即在每一步以一定概率接受比当前解更差的结果,该概率随时间推移而降低,有助于跳出局部最小
- 随机梯度下降(SGD),由于每次只选择部分样本,有几率跳出局部最小
为什么说bagging是减少variance,而boosting是减少bias?
简单来说如果bagging的n个分类器的样本都是独立的,那么方差可以缩小n倍,偏差不变。尽管一般来说都不是完全独立的,也能一定程度上减小方差。boosting是用弱分类去训练错误样本,目标是减少偏差。
详细解释可见:https://www.zhihu.com/question/26760839
Batch Normalization归一化作用
用的不是很多,目的是为了解决不同层之间数据分布改变导致训练速度慢等的问题。
可以参考:
https://blog.csdn.net/yujianmin1990/article/details/78764597
https://blog.csdn.net/hjimce/article/details/50866313
特征选择
数据属性过多会造成维度灾难,特征选择就是从中选出更重要的部分属性。
- 过滤式:计算相关性,丢掉方差改变小的特征(方差阈值),丢掉高度相关的特征(冗余信息)。
- 包裹式:利用测试集作为评价标准,反过来选。
- 嵌入式:利用了L1norm直接做筛选。
特征提取
创造全新的,较小的特征集
- PCA:选取方差最大化的投影平面
(1)先对所有样本中心化,xi = xi - x(average)
(2)计算协方差矩阵
(3)对协方差矩阵用奇异值分解SVD
(4)选取最大的k个特征值对应的特征向量
稀疏表示
稀疏表示本来是最小化L0范数的问题,这往往是一个NP hard的问题,一般用最小化L1范数作为近似。(L1是L0的最优近似)
是对于庞大数据集的一种降维表示,优点是省空间;奥卡姆剃刀说:如果两个模型的解释力相同,选择较简洁的那个。稀疏表达就符合这一点。
关于模型的选择
这篇讲的很好:https://www.leiphone.com/news/201608/WosBbsYqyfwcDNa4.html
1. 首当其冲应该选择的就是逻辑回归,如果它的效果不怎么样,那么可以将它的结果作为基准来参考,在基础上与其他算法进行比较;
2. 然后试试决策树(随机森林)看看是否可以大幅度提升你的模型性能。即便最后你并没有把它当做为最终模型,你也可以使用随机森林来移除噪声变量,做特征选择;
3. 如果特征的数量和观测样本特别多,那么当资源和时间充足时(这个前提很重要),使用SVM不失为一种选择。
通常情况下:【GBDT>=SVM>=RF>=Adaboost>=Other…】