一、需求
研究生学长让我把一个植物表型资讯系列文章的一系列文章爬下来保存为pdf或者html格式。
首页网址:
https://mp.weixin.qq.com/s?__biz=MzI0Mjg5ODI1Ng==&mid=2247486022&idx=1&sn=5f7c9aff1e3f1847812ce92304a3affc&chksm=e9740e79de03876fffc5ca39f70c105298acf5d2329d632e69cb997f8a07ba1234f97c91464c&scene=21#wechat_redirect

二、思路分析
列表的每一篇文章都应该是一个链接,因此先将首页保存下来分析其元素结构

找到各链接所在主体<div>元素<div class="rich_media_content " id="js_content">记录

确认每一个文章链接都在都是<a>元素
因此思路就是 先获得主体块中的链接标签,根据文章名和链接保存每一篇文章。
三 、难点
难点在于保存pdf时,图片是要保存在pdf之中的,因此如果文章界面图片如果是是懒加载的时候,爬取的文章保存位html和pdf 图片都将会是空白的。
因此先去分析文章中图片的加载形式
选一篇文章分析:

可以看到图片加载采用的是data-src加载的,因此需要将每一个<img>的标签t图片链接改成src形式。
四、采用工具
import requests//用来请求获得页面
import pdfkit// 用来保存成pdf格式
from bs4 import BeautifulSoup//用来将html划分成各标签进行处理五、源码
# -*- coding:UTF-8 -*-
import time
import requests
import pdfkit
import re
from bs4 import BeautifulSoup
# 模版
html_template = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
{content}
</body>
</html>
"""
def save_pdfs(a):
i=0
for each in a:
i=i+1
if i>0: # 如果因为某种原因中断后可以根据已经下载的篇数设定i值从第i篇开始
if each.string != None:
rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |' #存到本地 剔除特殊符号
each.string = re.sub(rstr, "_", each.string)
file_name = "E:\\pdf1\\" + each.string + ".pdf"
html_name = "E:\\html1\\" + each.string + ".html"
path_wk = r'D:\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf=path_wk) # windows需要进行此配置 才能转化pdf
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'no-outline': None
}
target = each.get('href')
time.sleep(4) # 设置强制睡眠时间减少IP被禁的可能性
page = requests.get(url=target)
soup = BeautifulSoup(page.content, 'html.parser')
article = soup.select('.rich_media_content')[0]# 选择主体部分下载
for img in article.find_all('img'):
img['src'] = img['data-src'] ##!!!将所有的懒加载改成直接加载
article = str(article)
html = html_template.format(content=article)
html = html.encode('utf-8')
with open(html_name, 'wb') as f:
f.write(html) # 保存html格式
try: # 保存pdf格式
pdfkit.from_file(html_name, file_name, configuration=config, options=options) # 转化成pdf格式
except Exception as e:
print(e)
def main():
target = 'https://mp.weixin.qq.com/s?__biz=MzI0Mjg5ODI1Ng==&mid=2' \
'247486022&idx=1&sn=5f7c9aff1e3f1847812ce92304a3affc&chksm=e9' \
'740e79de03876fffc5ca39f70c105298acf5d2329d632e69cb997f8a07ba \
1234f97c91464c&scene=21#wechat_redirect'
req = requests.get(url=target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_='rich_media_content')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')# 获得主页面的所有链接标签
save_pdfs(a)
if __name__ == "__main__":
main()
六、效果展示
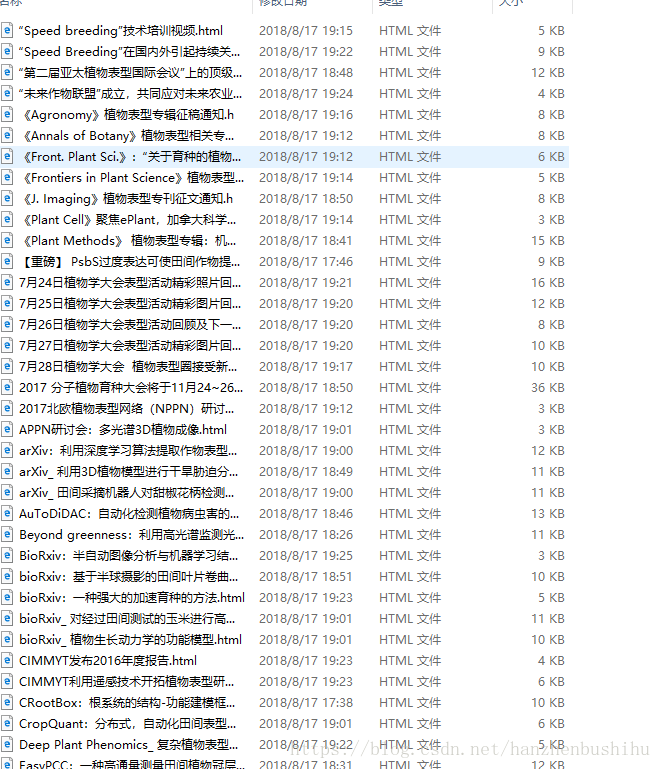
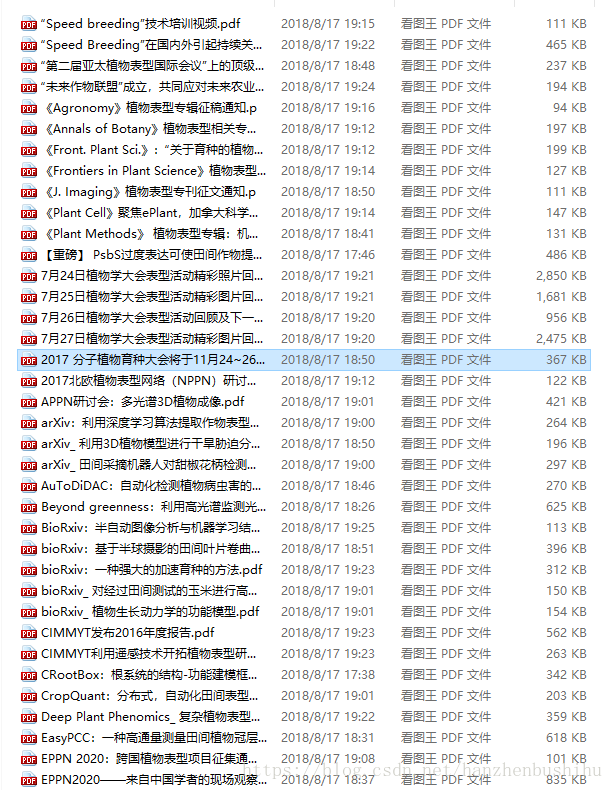
其中一篇pdf,可以看到是带有图片的。
