集群HDFS文件的操作(Shell)
1.基本语法
1.既能操作分布式也能操作本地:bin/hadoop fs 具体命令
2.只能操作分布式:bin/hdfs dfs 具体命令
注:如果配了hadoop的环境变量可以省去bin/
2.一些帮助理解的例子
2.1命令执行条件(启动集群)
1.执行命令:[lsl@hadoop102 hadoop-2.7.2]$ start-dfs.sh
2.再执行命令:[lsl@hadoop103 hadoop-2.7.2]$ start-yarn.sh
2.2查看常用命令
1.执行命令:[lsl@hadoop102 hadoop-2.7.2]$ hadoop fs

2.3查看单个命令详情
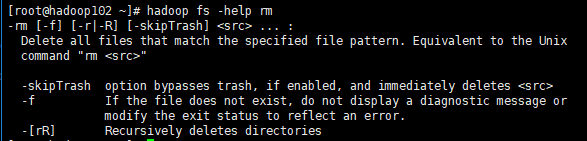
1.执行命令:hadoop fs -help [命令]
2.例:
2.4一些思考
1.-setrep:设置HDFS中文件的副本数量
2.执行命令:hadoop fs -setrep 10 /user/lsl/input/wc.input
3.结果:


4.现象说明:
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数增加到10台时,副本数才能真正达到10。
版权声明:本博客为记录本人自学感悟,转载需注明出处!
https://me.csdn.net/qq_39657909