版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/85273308
1 Spark 介绍
1.1 Spark 特点
- 速度:在内存中存储中间结果
- 支持多种语言
- 内置 80+ 的算子
- 高级分析:MR,SQL/ Streaming/Mlib/Graph
1.2 Spark 模块
core: 通用执行引擎,提供内存计算和对外部数据集的引用;SQL: 构建在 core 之上,引入抽象的schemaRDD,提供了结构化和半结构化的支持;streaming: 小批量计算;
2 RDD
- spark 的基本数据结构,是不可变数据集,RDD中的数据集进行逻辑分区,每个分区可以单独在集群节点进行计算
- RDD 是只读的记录分区集合,具有容错机制
- 创建RDD的 2种方式 ,1:读取外部数据集;2:在驱动程序里分发驱动器程序中的对象集合;
- hadoop 90%的时间在读和写
- 内存处理计算,
2.1 RDD 包含的5个主要属性
- 分区列表
- 针对每个 split 的计算函数
- 对其他RDD的依赖列表
- 可选,如果是 KeyValueRDD,可以带分区类
- 可选,首选块位置列表(hdfs block location)
2.2 RDD 变换
- 返回指向新的 RDD 的指针,在RDD 之间创建依赖关系,每个RDD都有计算函数和指向父RDD的指针;
- 执行
collect语句时才打印
2.3 并发度和分区
map: 对每个元素进行变换,应用变换函数mapPartition: 对每个分区应用变换,输入:Iterator,返回新的迭代器,可以对分区进行函数处理
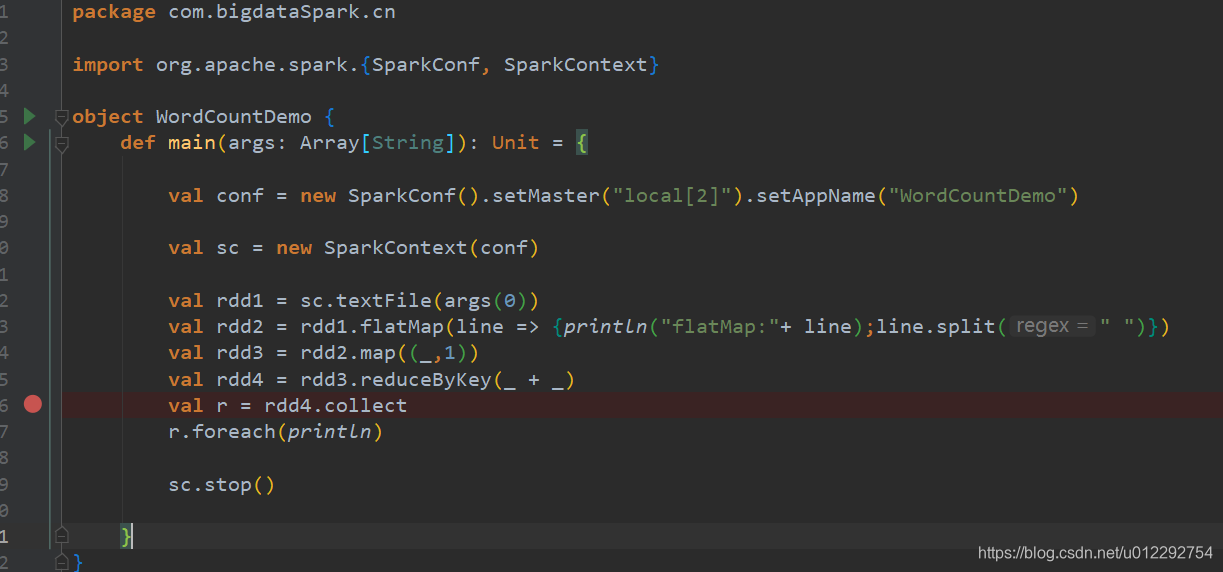
- 测试1
package com.bigdataSpark.cn
import org.apache.spark.{SparkConf, SparkContext}
object WordCountDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCountDemo")
val sc = new SparkContext(conf)
val rdd1 = sc.textFile(args(0))
val rdd2 = rdd1.flatMap(_.split(" "))
val rdd3 = rdd2.mapPartitions(it => {
import scala.collection.mutable.ArrayBuffer
val buf = ArrayBuffer[String]()
println("partition start :")
for (e <- it) {
buf.+=("_" + e)
}
buf.iterator
})
val rdd5 = rdd3.map((_, 1))
val rdd4 = rdd5.reduceByKey(_ + _)
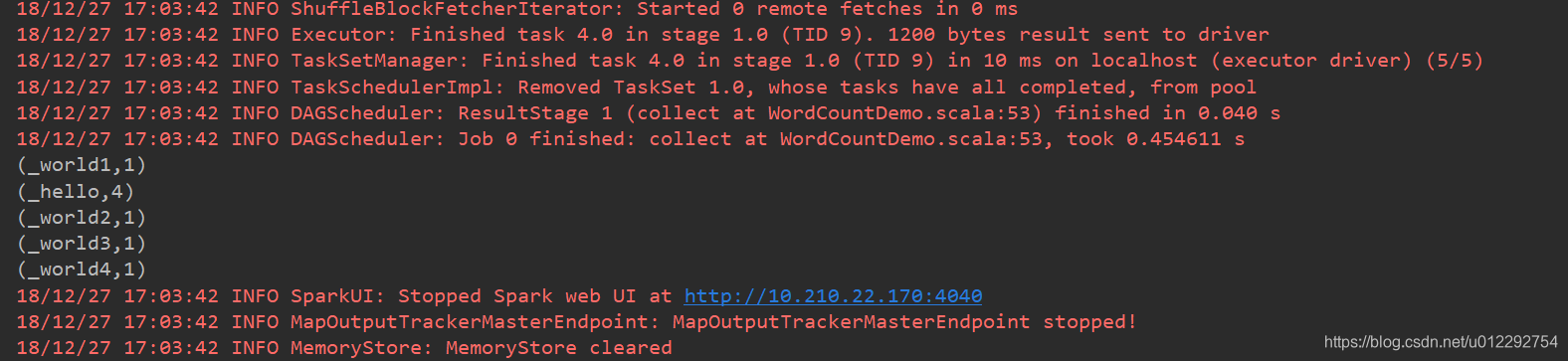
val r = rdd4.collect
r.foreach(println)
sc.stop()
}
}


- 测试2 ,单线程修改分区数为2
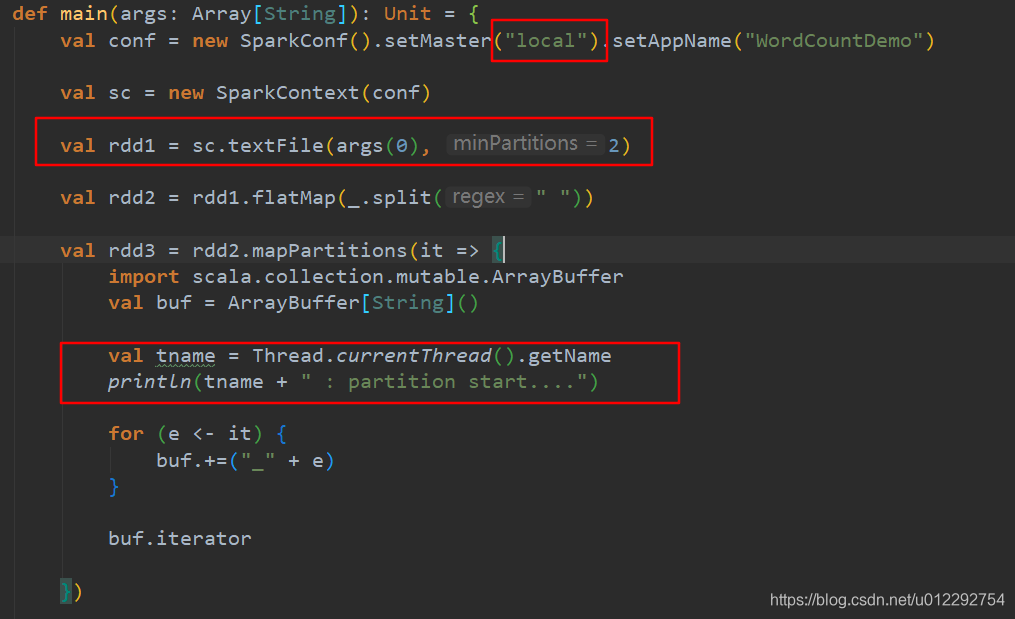
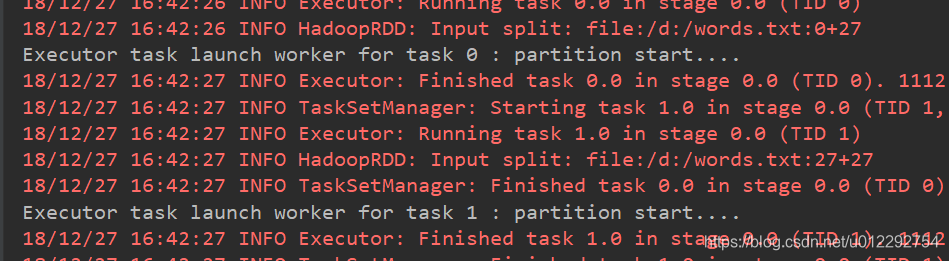

- 测试3,修改线程为2,其他不变
package com.bigdataSpark.cn
import org.apache.spark.{SparkConf, SparkContext}
object WordCountDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("WordCountDemo")
val sc = new SparkContext(conf)
val rdd1 = sc.textFile(args(0), 2)
val rdd2 = rdd1.flatMap(_.split(" "))
val rdd3 = rdd2.mapPartitions(it => {
import scala.collection.mutable.ArrayBuffer
val buf = ArrayBuffer[String]()
val tname = Thread.currentThread().getName
println(tname + " : partition start....")
for (e <- it) {
buf.+=("_" + e)
}
buf.iterator
})
val rdd5 = rdd3.map(word =>{
val tname = Thread.currentThread().getName
println(tname + " : map " + word)
(word,1)
})
val rdd4 = rdd5.reduceByKey(_ + _)
val r = rdd4.collect
r.foreach(println)
sc.stop()
}
}
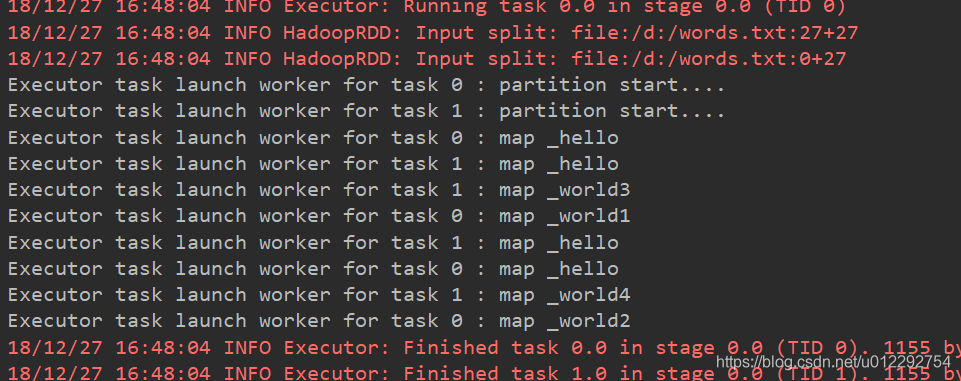

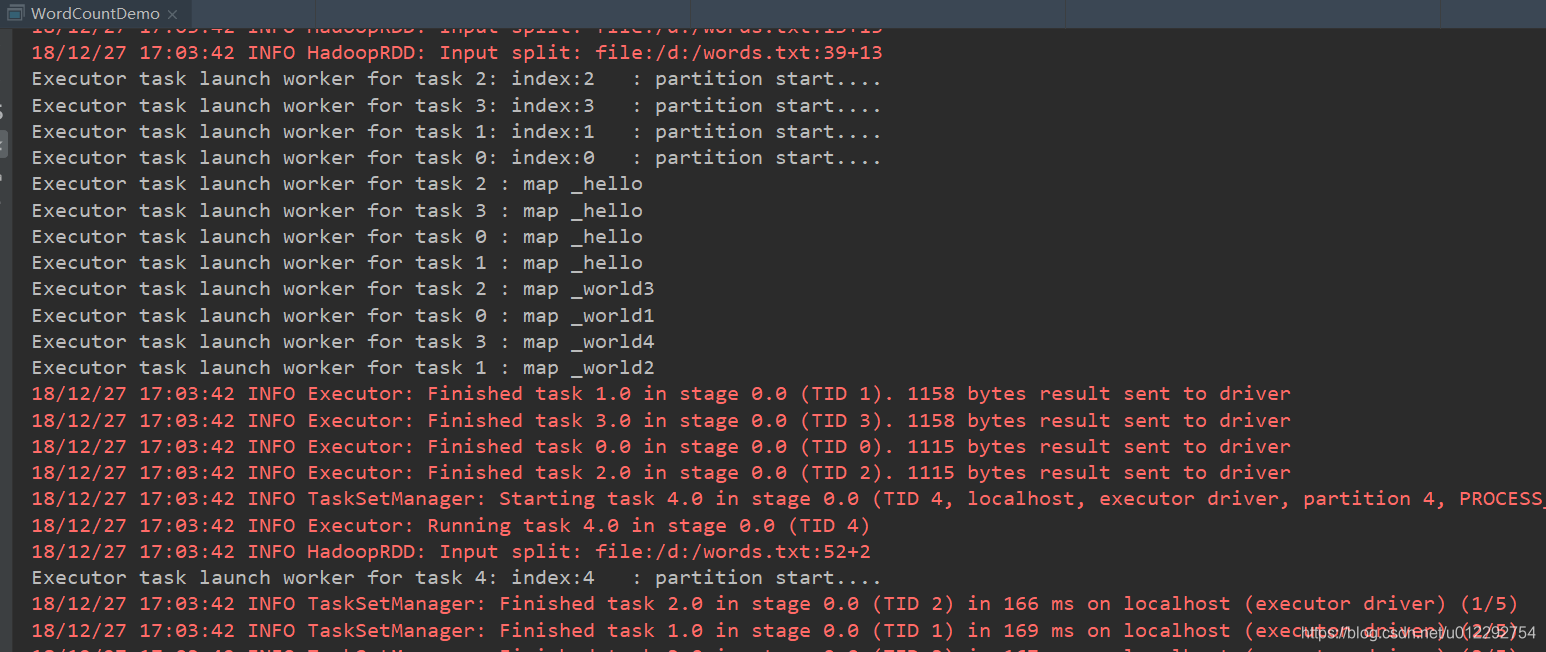
- 测试4 ,设置线程和分区为4
具体的分区数和设置的数字不一定对应
package com.bigdataSpark.cn
import org.apache.spark.{SparkConf, SparkContext}
object WordCountDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("WordCountDemo")
val sc = new SparkContext(conf)
val rdd1 = sc.textFile(args(0), 4)
val rdd2 = rdd1.flatMap(_.split(" "))
// val rdd3 = rdd2.mapPartitions(it => {
// import scala.collection.mutable.ArrayBuffer
// val buf = ArrayBuffer[String]()
//
// val tname = Thread.currentThread().getName
// println(tname + " : partition start....")
//
// for (e <- it) {
// buf.+=("_" + e)
// }
//
// buf.iterator
//
// })
val rdd3 = rdd2.mapPartitionsWithIndex((index, it) => {
import scala.collection.mutable.ArrayBuffer
val buf = ArrayBuffer[String]()
val tname = Thread.currentThread().getName
println(tname + ": index:" + index + " : partition start....")
for (e <- it) {
buf.+=("_" + e)
}
buf.iterator
})
val rdd5 = rdd3.map(word => {
val tname = Thread.currentThread().getName
println(tname + " : map " + word)
(word, 1)
})
val rdd4 = rdd5.reduceByKey(_ + _)
val r = rdd4.collect
r.foreach(println)
sc.stop()
}
}