版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_33907408/article/details/85260888
8.DRPC
- 8.1 RPC(hadoop)
remote procedure call 远程过程调用
跨网络(跨越传输和应用两层),跨进程

hadoopRPC
依赖hadoop client的RPC自己包
- 8.2 storm中本地模式的DRPC编程
DRPC并不是一个storm的特性,可以单独用,也可以放在一起用(将会很棒–form官网)
DRPC server进行协调:
拿到一个PRC请求,交给一个topology,将产生的结果返回给客户端。(和PRC的调用流程基本一样的)
最后是通过id匹配结果
之前不是远程调用的时候,是直接new一个topologyBuilder;现在是分布式远程调用,需要用的类是LinearDRPCTopologyBuilder

9.storm整合周边框架的使用
可以整合hin多的框架

- 9.1 redis
已经有一些现成的实现类:RedisLookupBolt RedisStoreBolt RedisFilterBolt
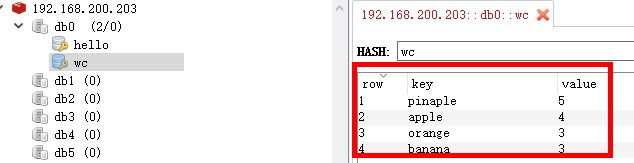
还是举一个wordcount的例子,不过最后输出到ziboris3:6379的redis上面,通过rdm进行结果查看
代码见最后LocalWordCountRedisStormTopology.java


- 9.2 jdbc
ConnectionProvider
JDBCMapper
JDBCInsertBolt(写入table的bolt)
- 9.3 hdfs
待更新
- 9.4 hbase
待更新
- 9.5 elasticSearch
待更新
=======================================================================
LocalWordCountRedisStormTopology.java
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.redis.bolt.RedisStoreBolt;
import org.apache.storm.redis.common.config.JedisPoolConfig;
import org.apache.storm.redis.common.mapper.RedisDataTypeDescription;
import org.apache.storm.redis.common.mapper.RedisStoreMapper;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.ITuple;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
/**
* 使用storm完成词频统计功能
*/
public class LocalWordCountRedisStormTopology {
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
public static final String[] words=new String[]{"apple","orange","banana","pinaple"};
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
Random random=new Random();
String word=words[random.nextInt(words.length)];
this.collector.emit(new Values(word));
System.out.println("emit:"+word);
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line_"));
}
@Override
public void ack(Object msgId) {
super.ack(msgId);
System.out.println(msgId);
}
}
/**
* 对数据进行分割,并发送分隔好的单词出去
*/
public static class SplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* 业务逻辑:
* line对其分割,按照“,”
*
* @param input
*/
@Override
public void execute(Tuple input) {
String word = input.getStringByField("line_");
this.collector.emit(new Values(word));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word_"));
}
}
/**
* 词频汇总Bolt
*/
public static class CountBolt extends BaseRichBolt{
Map<String,Integer> map=new HashMap<>();
private OutputCollector collector;//还会继续往下面发送,发送给redis
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
/**
* 业务逻辑:
* 1.获取每一个单词
* 2.对所有单词进行汇总
* 3.输出
* @param input
*/
@Override
public void execute(Tuple input) {
String word=input.getStringByField("word_");
Integer count=map.get(word);
if(count==null){
count=1;
}else{
count++;
}
map.put(word,count);//添加的时候hashmap会自动覆盖相同的key的entry
this.collector.emit(new Values(word,map.get(word)));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word_","count_"));
}
}
/**
* Mapper
*
*/
public static class WordCountStoreMapper implements RedisStoreMapper{
private RedisDataTypeDescription description;
private final String hashKey="wc";
public WordCountStoreMapper(){
description=new RedisDataTypeDescription(
RedisDataTypeDescription.RedisDataType.HASH,hashKey
);
}
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return description;
}
@Override
public String getKeyFromTuple(ITuple iTuple) {
return iTuple.getStringByField("word_");
}
@Override
public String getValueFromTuple(ITuple iTuple) {
return iTuple.getIntegerByField("count_")+"";
}
}
public static void main(String[] args) {
//topo创建
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout_",new DataSourceSpout());
builder.setBolt("SplitBolt_",new SplitBolt()).shuffleGrouping("DataSourceSpout_");
builder.setBolt("CountBolt_",new CountBolt()).shuffleGrouping("SplitBolt_");
JedisPoolConfig poolConfig=new JedisPoolConfig.Builder()
.setHost("192.168.200.203")
.setPort(6379)
.build();
WordCountStoreMapper storeMapper = new WordCountStoreMapper();
RedisStoreBolt storeBolt=new RedisStoreBolt(poolConfig,storeMapper);
builder.setBolt("RedisStoreBolt_",storeBolt).shuffleGrouping("CountBolt_");
//创建本地集群
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("LocalWordCountStormTopology",new Config(),builder.createTopology());
}
}