SQL DDL 操作
什么是SQL DDL 操作?
DDL是SQL定义语言,它主要包括三个关键字:create ,alter , drop(数据库关键字不分大小写 ),主要操作对象 有数据库、表、索引、视图等。
语句说明:
创建数据库 create database
修改数据库 alter database
删除数据库 drop database
创建表 create table
修改表 alter table
删除表 drop table
创建索引 create index
删除索引 drop index
实验的目的
- 掌握创建数据库和撤销。
- 掌握基本表的创建、修改和撤销。
- 掌握索引的创建和撤销。
实验内容与要求
利用SQL语句创建数据库Lesson,并指定数据文件和日志文件的存储位置为E:\sqldata。
通过SQL语句创建以下基本表
- 教师关系 T (T#, TNAME,TITLE)
- 课程关系 C (C#,CNAME,T#)
- 学生关系 S (S#,SNAME,AGE,SEX)
- 选课关系 SC (
S#,C#,SCORE) - 班级关系CLASS(CLASSID,CLASSNAME)
- 其中粗体为主键,划线的属性为外键。
- 通过SQL语句在CLASS表的CLASSID列上创建聚集索引IDX_CLASSID
- 通过SQL语句创建在S#和C#两个列上创建索引IDX_S#_C#,并指定索引按S#降序,C#升序有序。
- 通过SQL语句实现以下操作:
- 撤销索引IDX_CLASSID及IDX_S#_C#
- 在学生关系中增加班级号属性列CLASSID
- 撤销学生关系中的班级号属性列CLASSID
- 撤销班级关系CLASS
实验主要步骤
一、创建数据库Lesson
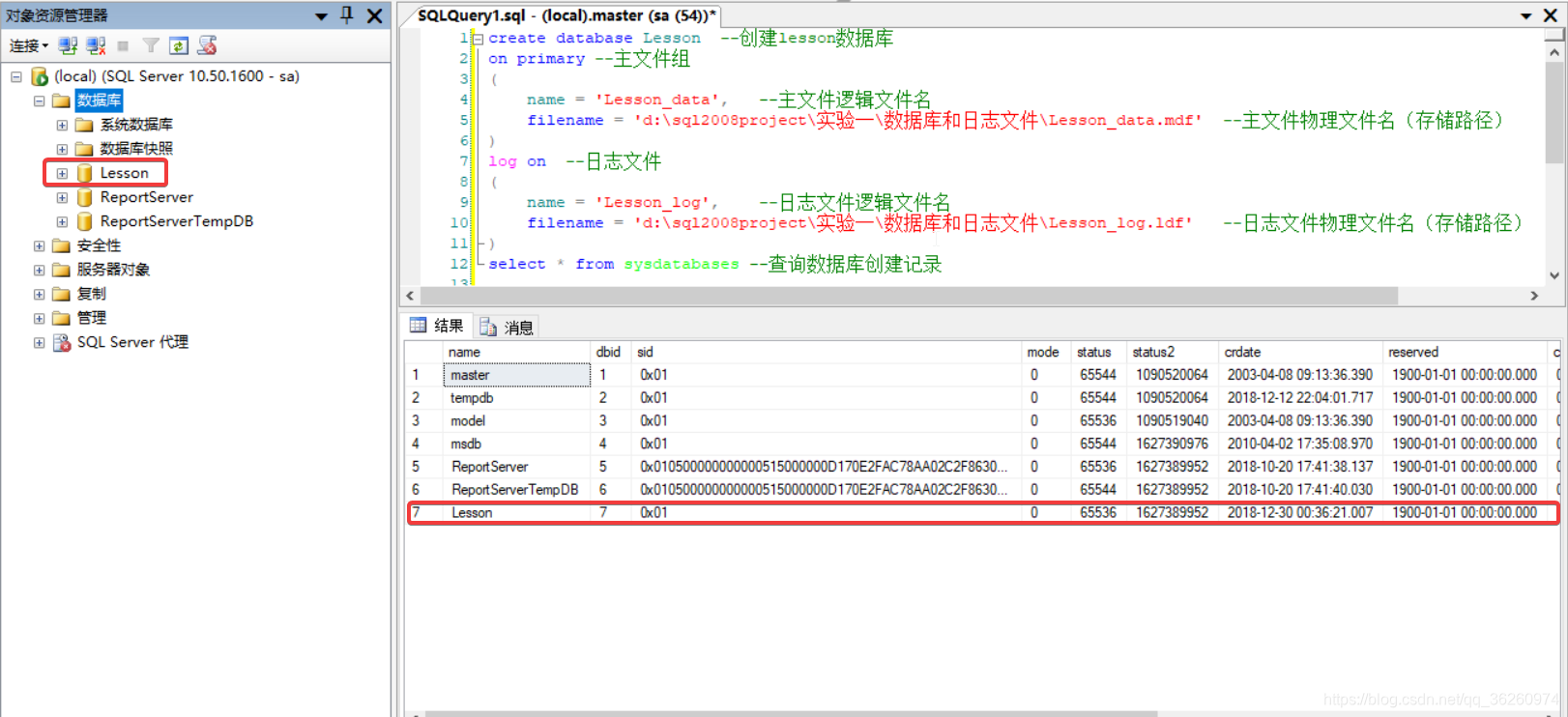

源码:
create database Lesson --创建lesson数据库
on primary --主文件组
(
name = 'Lesson_data', --主文件逻辑文件名
filename = 'd:\sql2008project\实验一\数据库和日志文件\Lesson_data.mdf' --主文件物理文件名(存储路径)
)
log on --日志文件
(
name = 'Lesson_log', --日志文件逻辑文件名
filename = 'd:\sql2008project\实验一\数据库和日志文件\Lesson_log.ldf' --日志文件物理文件名(存储路径)
)
select * from sysdatabases --查询数据库创建记录
创建数据库后创新可见所建立的数据库。
二、通过SQL语句创建基本表
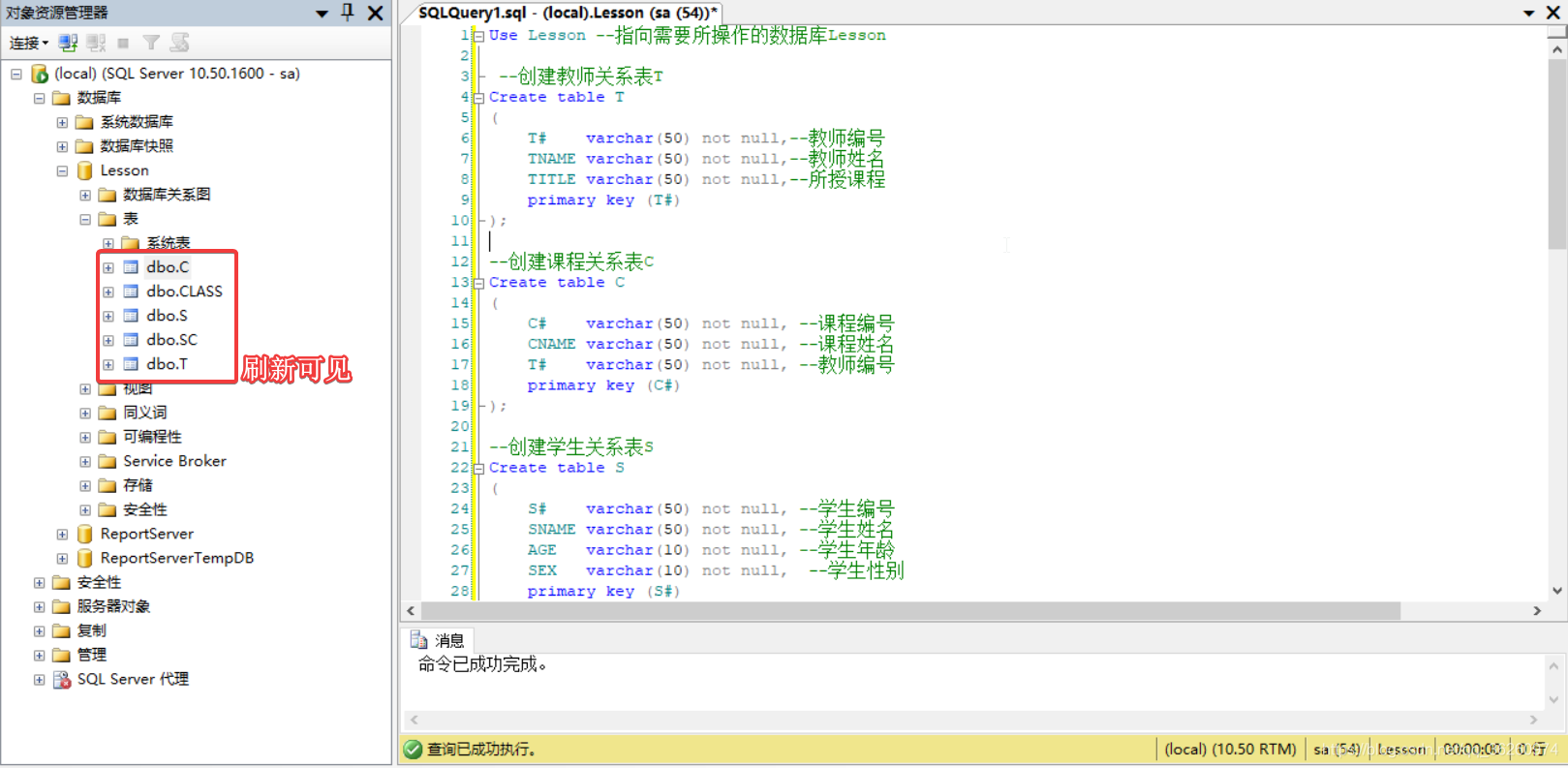
源码:
Use Lesson --指向需要所操作的数据库Lesson
--创建教师关系表T
Create table T
(
T# varchar(50) not null,--教师编号
TNAME varchar(50) not null,--教师姓名
TITLE varchar(50) not null,--所授课程
primary key (T#)
);
--创建课程关系表C
Create table C
(
C# varchar(50) not null, --课程编号
CNAME varchar(50) not null, --课程姓名
T# varchar(50) not null, --教师编号
primary key (C#)
);
--创建学生关系表S
Create table S
(
S# varchar(50) not null, --学生编号
SNAME varchar(50) not null, --学生姓名
AGE varchar(10) not null, --学生年龄
SEX varchar(10) not null, --学生性别
primary key (S#)
);
--创建选课关系表SC
Create table SC
(
S# varchar(50) not null, --学生编号
C# varchar(50) not null, --课程编号
SCORE varchar(50) not null --学生分数
primary key (S#,C#),
foreign key (S#) references S (S#),
foreign key (C#) references C (C#)
);
--创建选课关系表CLASS
Create table CLASS
(
CLASSID varchar(50) not null,--班级编号
CLASSNAME varchar(50) not null,--班级姓名
)
三、通过SQL语句在CLASS表的CLASSID列上创建聚集索引IDX_CLASSID

源码:
Use Lesson --指向需要所操作的数据库Lesson
create clustered index IDX_CLASSID --创建聚集索引
on CLASS(CLASSID) --为某表某列创建索引
四、通过SQL语句创建在S#和C#两个列上创建索引IDX_S#_C#,并指定索引按S#降序,C#升序有序。
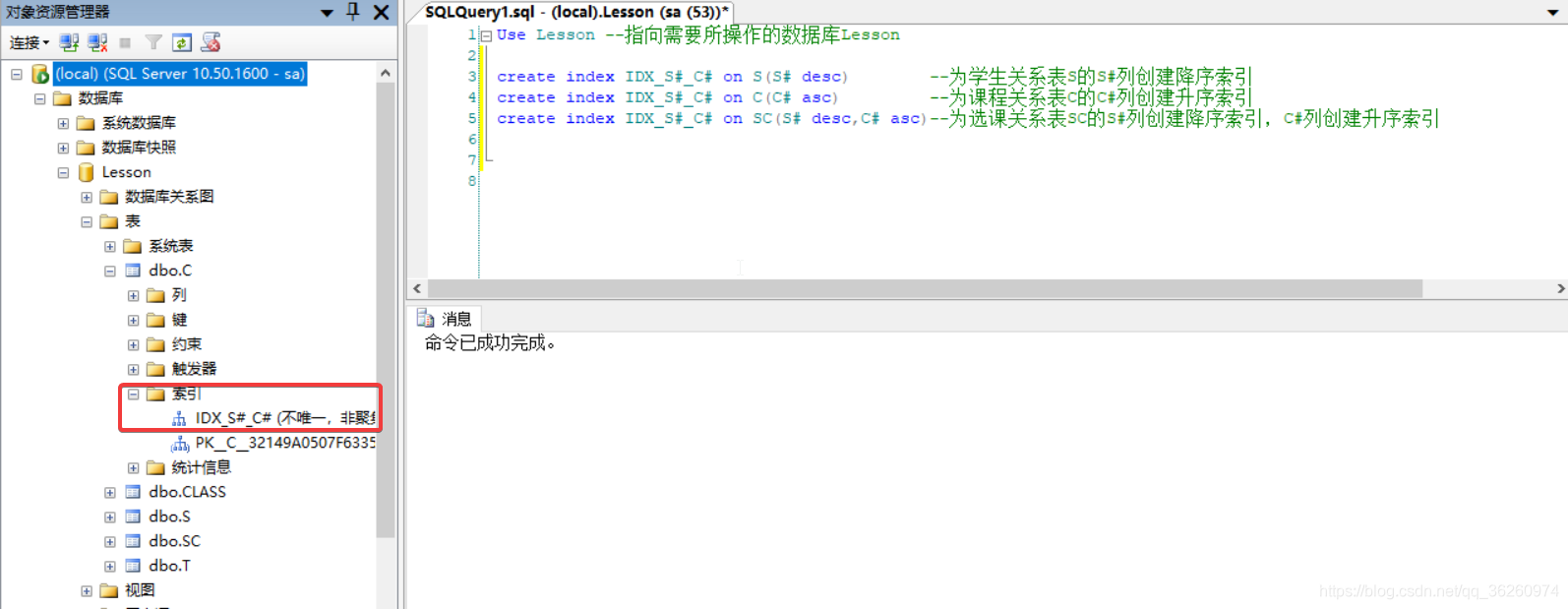
源码:
Use Lesson --指向需要所操作的数据库Lesson
create index IDX_S#_C# on S(S# desc) --为学生关系表S的S#列创建降序索引
create index IDX_S#_C# on C(C# asc) --为课程关系表C的C#列创建升序索引
create index IDX_S#_C# on SC(S# desc,C# asc)--为选课关系表SC的S#列创建降序索引,C#列创建升序索引
五、撤销索引IDX_CLASSID及IDX_S#_C#
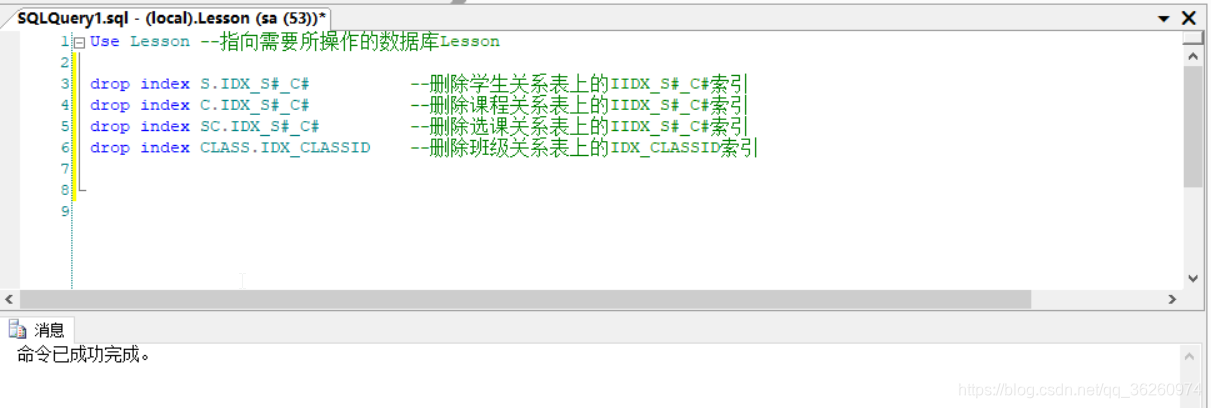
源码:
Use Lesson --指向需要所操作的数据库Lesson
drop index S.IDX_S#_C# --删除学生关系表上的IIDX_S#_C#索引
drop index C.IDX_S#_C# --删除课程关系表上的IIDX_S#_C#索引
drop index SC.IDX_S#_C# --删除选课关系表上的IIDX_S#_C#索引
drop index CLASS.IDX_CLASSID --删除班级关系表上的IDX_CLASSID索引
六、在学生关系中增加班级号属性列CLASSID
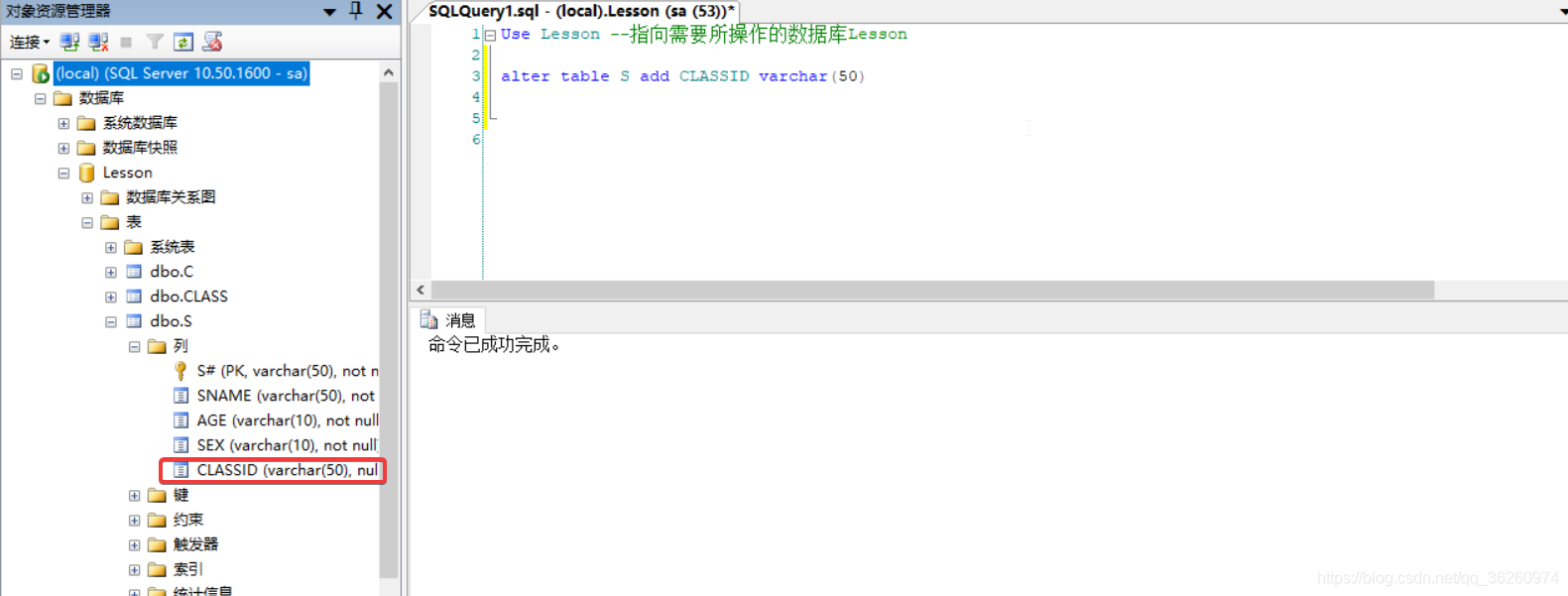
源码:
Use Lesson --指向需要所操作的数据库Lesson
alter table S add CLASSID varchar(50)
七、撤销学生关系中的班级号属性列CLASSID
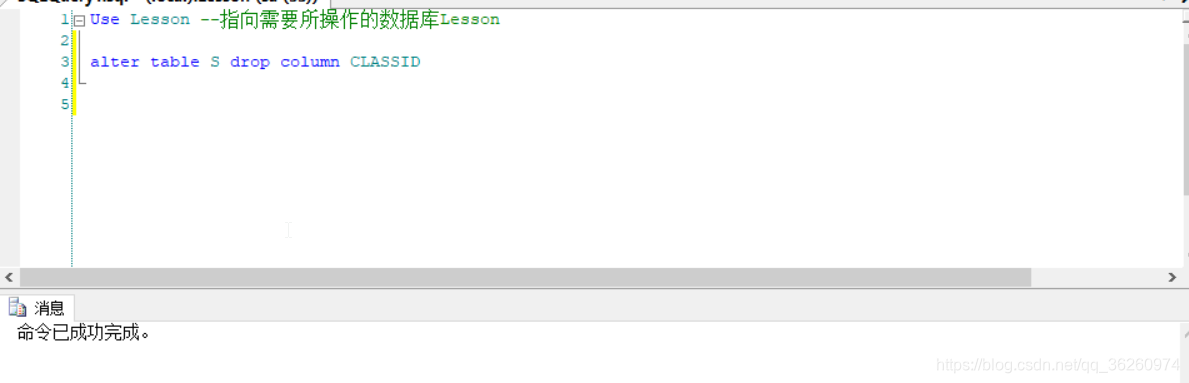
源码:
Use Lesson --指向需要所操作的数据库Lesson
alter table S drop column CLASSID
八、撤销班级关系CLASS
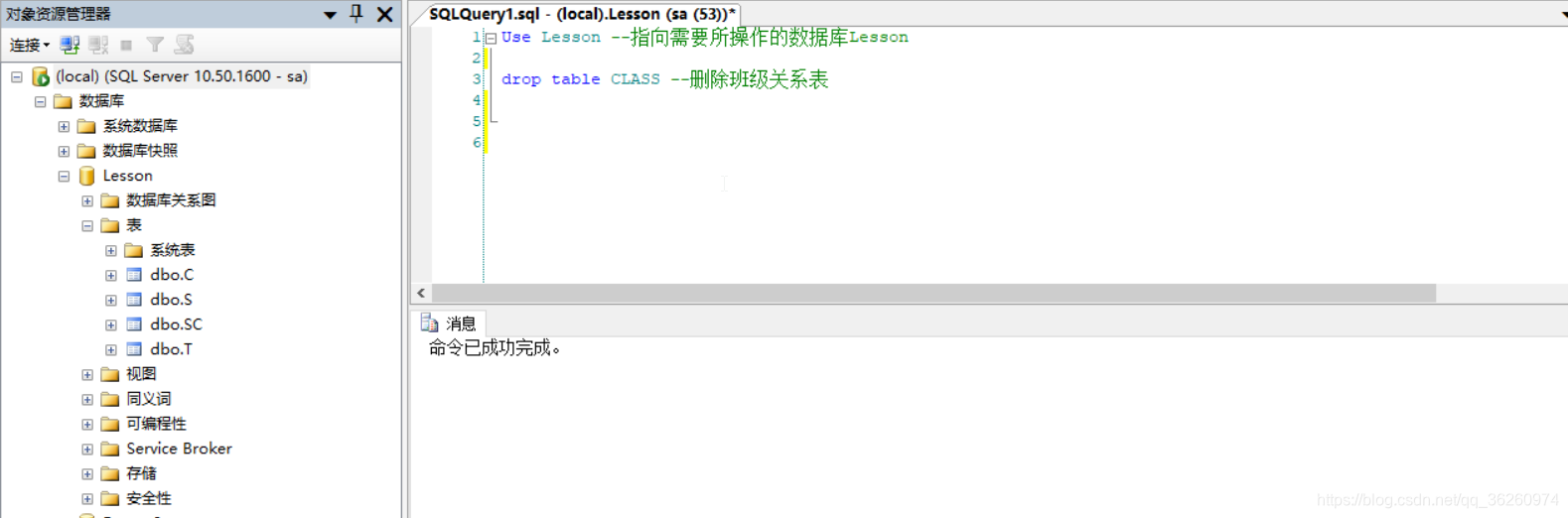
源码:
Use Lesson --指向需要所操作的数据库Lesson
drop table CLASS --删除班级关系表
至此,本实验全部要求已完成!
关键语法介绍:
-
建库
create database 数据库名
on primary --主文件组
(
name = ‘主文件逻辑文件名’,
filename = ‘主文件物理文件名(存储路径)’ ,
size = 主文件初始大小(单位MB),
maxsize = 主文件增长的最大值(单位MB),
filegrowth = 主文件的增长率(单位MB或者%)
)<此处可以继续添加子文件组>
log on --日志文件
(
name = ‘日志文件逻辑文件名’,
filename = ‘日志文件物理文件名(存储路径)’,
size = 日志文件初始大小(单位MB),
maxsize = 日志文件增长的最大值(单位MB),
filegrowth = 日志文件的增长率(单位MB或者%)
) <此处可以继续添加日志文件> -
建表
create table 表名
(
列名 数据类型 是否为空 等
) -
创建索引
create [unique] [clustered] [nonclustered] index 索引名
on 表名(列名 [desc][asc])为某表某列创建索引(降序/升序) -
删除索引
drop index 表名.索引名 -
新增列
alter table 表名 add 需要添加的列名 数据类型 -
删除列
alter table 表名 drop column 列名 -
删除表
drop table 表名
关键知识点
- 主键:
- 表中一列或几列组合的,能够唯一的表示表中的每一行
- 一个表只能有一个主键
- 多列组合当主键称为符合主键
- 原则:最少性和唯一性
- 外键
- 相对于主键而言
- 一个表可以有多个外键
- 约束的类型
- 主键约束:要求主键列不能为空,要求主键列唯一
- 非空约束:要求列不能存在空值
- 唯一约束:要求列的值必须是唯一的,允许为空,但只能出现一个空值
- 检查约朿:限制某列取值的范围是否合适
- 默认约束:设计列的默认值
- 外健约束:用于在两表之间建立关系,需要指定引用主表的哪一列
主健约束与唯一约束的区别:
- 主键约束所在的列不允许有空值,唯一约束所在的列允许空值
- 每个表中可以有一个主键,多个唯一键
- 索引
索引:是SQL编排数据的内部方法,为SQL SERVER 提供一种方法来编排查询数据
索引的分类:
- 聚集索引:正文内容本身就是一种按照规定排列的目录称为 “聚集索引”。例如新华字典正文就是按照字母顺序排序的,也可以说字典正文本身就是目录,不需要查看其它目录去查找,这就是聚集索引。
- 非聚集索引:目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。例如在新华字典查询不知道读音的字,那就需要使用偏旁部首来查询,而在偏旁部首里并没有按照读音来排序,会出现偏旁部首里邻近的两个字,而在正文里相差甚远,像这样目录是目录,内容是内容的方式就是非聚集索引。
- 作用:大大提高数据库的检索速度,改善数据库性能。
建立索引的一般原则:
- 每个表只能创建一个聚集索引;
- 每个表最多只能创建一249个非聚集索引;
- 在进程查询的字段上建立索引;
- Text,Image和bit数据类型的列上不要建立索引;
- 外键列可以建立索引;
- 主键列必须建立索引;
- 重复值表较多,查询较少的列上不要建立索引。
如有错误,欢迎指正!