文章目录
1 栈
1.1 抽象数据类型栈的定义
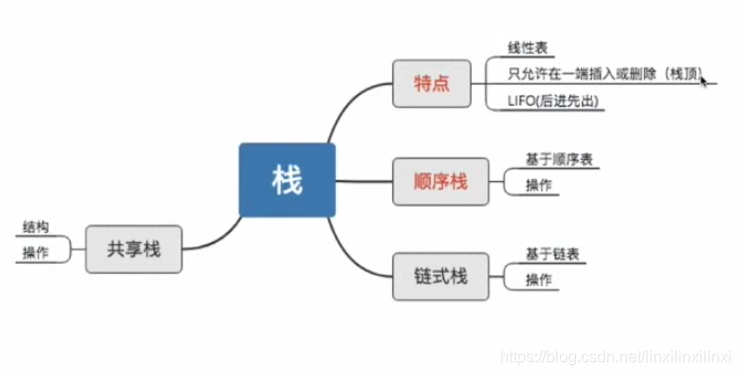
栈(stack)是限定仅在表尾进行插入或删除操作的线性表。
1.1.1 栈顶和栈尾
因此,对栈来说,表尾端有其特殊含义,称为栈顶(top),表头端称为栈底(bottom)。
1.1.2 空栈
不含元素的空表称为空栈
1.1.3 特点
栈的修改是按照后进先出的原则进行的
因此,栈又被称为后进先出(last in first out)的线性表(简称(LIFO)结构)
1.1.4 上溢和下溢
上溢——当堆栈已满时做插入操作。(top=M–1)
下溢——当堆栈为空时做删除操作。(top=–1)
1.2 栈的表示和实现
1.2.1 顺序栈
栈的顺序存储结构是利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,同时附设指针top指示栈顶元素在顺序栈中的位置
typedef struct{
SElemType *base;
SElemType *top;
int stacksize;
}SqStack;
其中,stacksize指示栈的当前可使用的最大容量
1.2.2 链栈
链接堆栈就是用一个线性链表来实现一个堆栈结构
同时设置一个指针变量( 这里不妨仍用top表示)指出当前栈顶元素所在链结点的位置
栈为空时,有top=NULL。
1.3 各种栈的判满与判空条件
2 栈的应用举例
栈的引入简化了程序设计的问题,划分了不同的关注层次,使思考范围缩小了
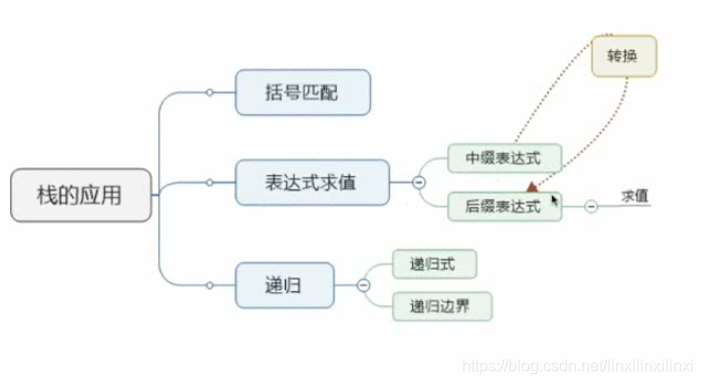
2.1 数值转换
2.2 括号匹配的检验
2.3 行编辑程序
2.4 迷宫求解(深度优先搜索)
2.5 表达式求值(逆波兰表达式)
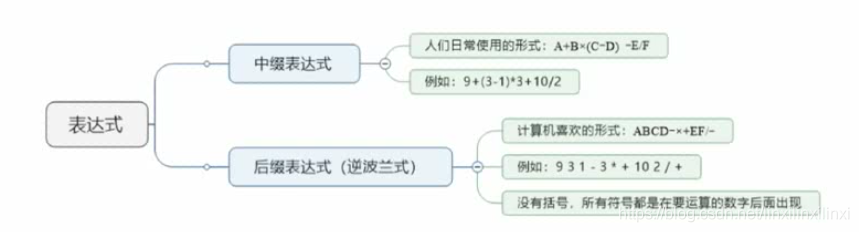
计算机可以通过栈来计算后缀表达式的值,从而计算表达式的值。
3 栈与递归的实现
3.1 递归
如果在一个函数、过程或数据结构的定义中有应用了它自身,那么这个函数、过程或数据结构称为是递归定义的,简称递归。
递归最重要的是递归式和递归边界
3.1 用分治法求解递归问题
3.1.1 分治法
对于一个较为复杂的问题,能够分解成几个相对简单的且解法相同或类似的子问题来求解
3.1.2 必备条件
-
能将一个问题转变成一个新问题,而新问题与原问题的解法相同或类同,不同的仅是处理的对象,且这些处理对象是变化有规律的
-
可以通过上述转化而使问题简化
-
必须有一个明确的递归出口,或称递归的边界
3.2 函数调用过程
3.2.1 调用前
3.2.1.1 将实参,返回地址等传递给被调用函数
3.2.1.2 为被调用函数的局部变量分配存储区
3.2.1.3 将控制转移到被调用函数的入口
3.2.2 调用后
3.2.2.1 保存被调用函数的计算结果
3.2.2.2 释放被调用函数的数据区
3.2.2.3 依照被调用函数保存的返回地址将控制转移到调用函数
3.3 递归算法的效率分析
空间效率 与递归数的深度成正比
时间效率 与递归树的结点数成正比
3.4 借助栈改写递归
(1)设置一个工作栈存放递归工作记录(包括实参、返回地址及局部变量等)。
(2)进入非递归调用入口(即被调用程序开始处)将调用程序传来的实在参数和返回地址入栈(递归程序不可以作为主程序,因而可认为初始是被某个调用程序调用)。
(3)进入递归调用入口:当不满足递归结束条件时,逐层递归,将实参、返回地址及局部变量入栈,这一过程可用循环语句来实现—模拟递归分解的过程。
(4)递归结束条件满足,将到达递归出口的给定常数作为当前的函数值。
(5)返回处理:在栈不空的情况下,反复退出栈顶记录,根据记录中的返回地址进行题意规定的操作,即逐层计算当前函数值,直至栈空为止—模拟递归求值过程。
4 队列
4.1 抽象数据类型队列的定义
队列(queue)是一种先进先出(first in first out,缩写为 FIFO)的线性表。
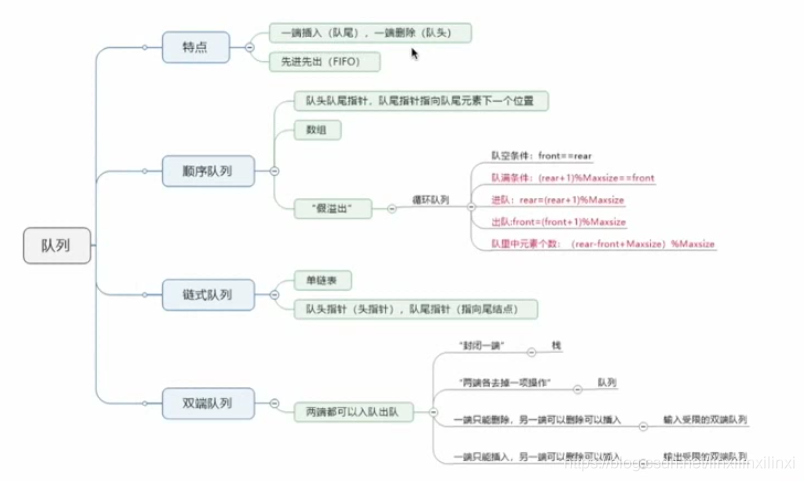
它只允许在表的一端进行插入,而在另一端删除元素。
4.1.1 队尾和队头
在队列中,允许插入的一端叫做队尾(rear),允许删除的一端叫做队头(front)。
4.1.2 双端队列
双端队列是限定插入和删除造作在表的两段进行的线性表。
4.2 链队列——队列的链式表示和实现
用链表表示的队列简称为链队列
队列的链式存储结构是用一个线性链表表示一个队列
指针front与rear分别指向实际队头元素与实际队尾元素所在的链结点。
4.3 循环队列
把队列(数组)设想成头尾相连的循环表,使得数组前部由于删除操作而导致的无用空间尽可能得到重复利用,这样的队列称为循环队列。