第三章:Data语意学
3.1 Data Member的绑定
主要讲Alignment,之前做笔试题遇到过挺多的,大概就是不满计算机一个字节的会加入padding填充满这一个字节。
3.2 Data Member的布局
3.3 Data Member的存取
静态数据&非静态数据
Point3d origin;
origin.x=0.0;//x的存取成本分x是否为静态数据以及Point3d是否是独立的class。
重点:
Point3d origin,*pt=&origin;
origin.x=0.0;
pt->x=0.0;问:这两种取法有什么重大差异。
.和->的问题,一个是针对对象,一个是针对指针。
比如你有这个结构体:
struct xx
{
int a;
int b;
}yy, *kk;
yy.a=3, yy.b=5;
kk=new xx;
kk->a=4, kk->b=6;
class A
{
public :
int a;
}
A ma;
A *p=&ma;那么指针p应使用->来访问成员a,比如p->a,而ma应使用.来访问,比如ma.a区别就在这里,凡是指针就使用->,对象就使用.运算符。
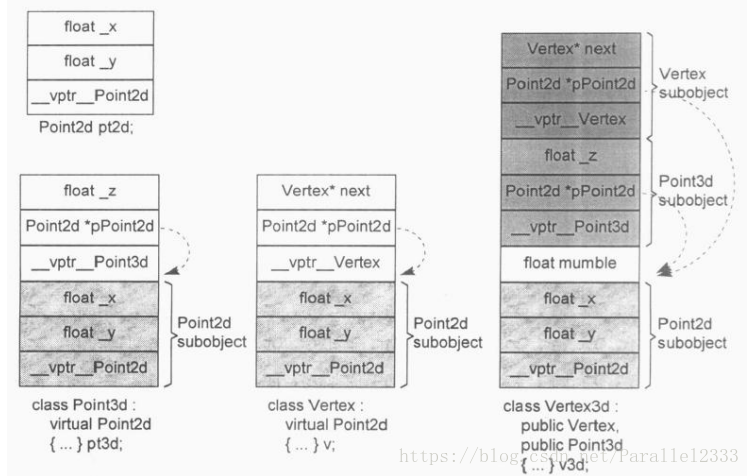
只有当Point3d是一个derived class,而在其继承结构中有一个virtual base class,并且存取的member是一个从该virtual base class继承而来的member时就会有重大的差异。因为我们无法在编译时期知道这个member的真正的offset的位置,因此这个存取操作需要被延迟到执行期,经由一个额外的间接导引才能够解决。但如果使用引用就不会有这个问题,由于其类型无疑是Point3d类型,即使它继承自virtual base class,members的offset位置在编译时期也就固定了。一个积极进取的编译器甚至可以静态的经由origin就解决掉对x的存取。
非静态数据会以明喻的或者暗喻的方式去调用。
明喻(explicit)
暗喻(implicit)也就是使用隐含的this指针。
对nonstatic data member进行存取操作编译器需要把class object的起始地址加上data member的偏移量。对于data member来说:
//下面两种形式等价
&origin._y
&origin+(&Point3d::_y-1);//这个-1是对于data member来说的。编译器会对data member的offset值进行加一使得编译器去区分"一个指向data member的指针,用以指出class的第一个member"和"一个指向data member的指针,没有指出任何member"的情况。相当于只要指出了member就需要-1还原。
3.4 继承与Data Member
a.单一继承而且没有virtual function时
这样做是没有virtual的成本的,也就是跟普通C结构没两样,没有额外的成本。
inline定义的函数会被放入符号表中,在使用时像宏一样展开进行替换,效率很高,并且会有参数检查,在类中定义还可以保护类的保护成员和私有成员。缺点在于代码过大过繁会造成很大开销。
b.加上多态,也就是引入了virtual function
c.多重继承
d.虚拟继承
3.5 对象成员的效率
实际上具体继承(非virtual继承)并不会增加空间或者存取时间上的额外负担,但是虚拟继承的间接性压抑了"把所有运算都移往缓存器执行"的优化能力,即使通过类对象访问编译器也会像对待指针一样,效率令人担心,一般来说virtual base class最有效地运用形式就是一个抽象的virtual base class,没有任何的data member。
虚函数到底有多慢:https://blog.csdn.net/hengyunabc/article/details/7461919
调用虚函数其实相当于多了3条汇编指令:根据指针或引用取虚表,取虚表的函数地址,对函数进行call调用。
call指令主要会影响CPU的流水线。
在获得引用和指针前无法进行内联优化。
3.6 指向Data Member的指针
&Point3d::z将得到z坐标在class object中的偏移量(offset)
上文提到过的-1操作是为了区分:
float Point3d::*p1=0;//Point3d::*的意思是:"指向Point3d data member"的指针类型。
float Point3d::*p2=&Point3d::x;
每次存取Point::x,也就是pB.*bx会被转化为&pB->__vbcPoint+(bx-1),而不是转化为最直接的&pB+(bx-1),因此会降低"把所有处理都搬移到缓存器中执行"的优化能力。
Base2* pb1 = new Derived; // 调整指针指向base2 clss子对象
Base2* pb2 = pb1->clone(); // pb1被调整至Derived对象的地址,产生新的对象,再次调整对象指针指向base2基类子对象,赋值给pb2。
Derived* pDerived = new Derived;
Base2* pBase2 = pDerived; // Base2为Derived的第二个基类
pBase2 != pDerived; // 两者不等,进行了this指针转换class Point3d
{
public:
virtual ~Point3d();
protected:
static Point3d origin;
float x, y, z;
};
&Point3d::z;//返回的是float Point3d::*
&origin.z;//返回的是float*
//问:这两个之间的差异是什么?
//第一个会得到其在类中的offset,第二个会得到member在内存中的真正地址,因为它是绑定于真正classobject身上的data member地址。第四章:Function语意学
name managling//重载时候的名字改编
extern "C"//实现C与C++混合编程
4.1 Member的各种调用方式
a.Nonstatic Member Function
C++设计的准则之一是nonstatic member function至少必须和nonmember function有相同的效率。也就是说在要有一样的访问速度。
float magnitude3d(const Point *_this){...}
float Point3d::magnitude3d() const{...}实际上对于member function会被内化为nonmember的形式。
步骤一:给类成员函数添加一个this指针
Point3d Point3d::magnitude(Point3d *const this)
Point3d Point3d::magnitude(const Point3d *const this)
步骤二:对数据成员的调用改为this,如x改为this->x
步骤三:将成员函数名称进行mangling处理,使它在程序中成为独一无二的语汇
extern magnitude__7Point3dFv(
register Point3d *const this);此时函数转化操作已完成,而为每一个调用操作也都必须转化:
obj.magnitude();转为magnitude__7Point3dFv(&obj);
ptr->magnitude();转为magnitude__7Point3dFv(ptr);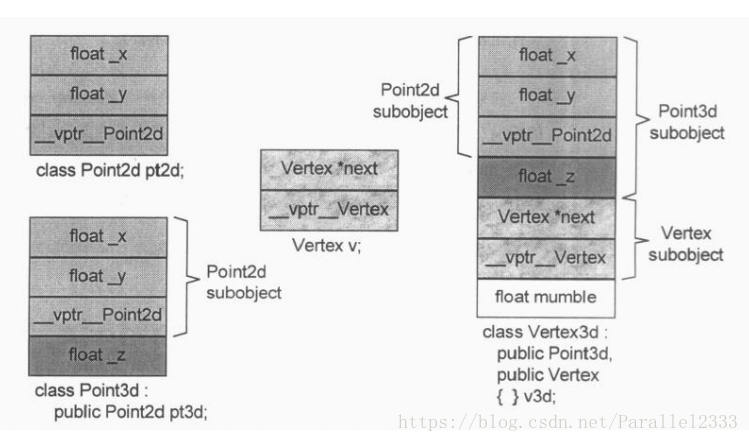
关于named return value的介绍:
https://www.cnblogs.com/zzj3/articles/3728902.html
https://blog.csdn.net/luofengmacheng/article/details/21072255
https://www.cnblogs.com/autosar/archive/2011/10/09/2204181.html
NRV操作主要就是在返回一个对象时直接用返回值去取代函数内部的局部对象,此时函数只产生一个对象。而普通的编译器会在返回一个对象时会再创建一个临时对象用于获取返回值,因此函数会产生两个对象。
CTest(const CTest& rcTest)//所谓的拷贝构造函数
{
cout << "CTest(CTest)" << this << endl;
}
void bar(X& __result)
{
// 调用__result的默认构造函数
__result.X::X();
// 处理__result
return;
}
// 函数实现
void bar(X& __result) // 加上一个额外参数
{
// 预留x1的内存空间
X x1;
// 编译器产生的默认构造函数的调用,
x1.X::X();
// 处理 x1..
// 编译器产生的拷贝操作
__result.X::X(x1);
return;
}
// 函数调用
X x2; // 这里只是预留内存,并未调用初始化函数
bar(x2); NRV这里涉及了一个拷贝构造函数的问题,默认的拷贝构造函数是浅拷贝,也是位拷贝,没有进行过内存的开辟而是直接给变量添加了一个引用,如果原始变量被删除就会产生一个野指针。位拷贝的效率也不见得高效,因此自定义拷贝构造函数很重要,举两个例子。
class A
{
public:
A()
{
data = new char;
cout << data << endl;
cout << "默认构造函数" << endl;
}
A(const A& a)//深拷贝
{
data = new char;
memcpy(data, a.data, sizeof(a.data));
}
//浅拷贝
/*A(const A& a)
{
data=a.data;
}*/
~A()
{
cout << "析构函数" << endl;
delete data;
cout << data << endl;
data = NULL;
}
private:
char* data;
};
class CA
{
public:
CA(int b,char* cstr)
{
a=b;
str=new char[b];
strcpy(str,cstr);
}
CA(const CA& C)
{
a=C.a;
str=new char[a]; //深拷贝
if(str!=0)
strcpy(str,C.str);
}
void Show()
{
cout<<str<<endl;
}
~CA()
{
delete str;
}
private:
int a;
char *str;
};
调用方式:
A a;
A b(a);//A b=a;b.Virtual Member Function
virtual Point3d::normalize();
ptr->normalize()=>(*ptr->vptr[1])(ptr);//第二个ptr表示this指针
obj.normalize()=>(*obj.vptr[1])(&obj)=>normalize__7Point3dFv(&obj)c.Static Member Function
((Point3d*)0)->object_count();
4.2 Virtual Member Function
什么是RTTI:其存储着类运行的相关信息,比如类的名字,以及类的基类。可以在运行时识别对象的信息。C++里面只记录类的名字和类的继承关系链,是的编译成二进制的代码中对象可以知道自己的名字,以及在继承链中的位置。
const type_info& typeinfo = typeid(pbase);
cout << typeinfo.name()<<endl;//输出pbase的类型class Base*
if(NULL != dynamic_cast<Derive*>(pbase))
{
cout<<"type: Derive"<<endl;//type:Derive
}
else if(NULL != dynamic_cast<Derive2*>(pbase))
{
cout<<"type: Derive2"<<endl;//type:Derive2
}
else
{
//ASSERT(0);
}C++中有4中强制类型转换符:dynamic_cast、const_cast、static_cast、reinterpret_cast。
其中dynamic_cast与运行时类型转换密切相关。该转换符用于将一个指向派生类的基类指针或引用转换为派生类的指针或引用,也就是dynamic_cast只能作用于含有虚函数的类。
B *pb; D *pd, md; pb=&md; pd=dynamic<D*>(pb);//含有虚指针的基类B和从基类B派生出的派生类D。
比如派生类D中含有特有的成员函数g(),这时可以这样来访问该成员dynamic_cast<D*>(pb)->g();但这个转换并不总是成功的。
dynamic_cast转换操作符在执行类型转换时首先将检查能否成功转换,如果能成功转换则转换之,如果转换失败,如果是指针则返回一个0值。因此pd=dynamic_cast<D*>(pb); if(pd){…}else{…},或者这样测试if(dynamic_cast<D*>(pb)){…}else{…}。
已知dynamic_cast依赖于RTTI,那么是如何绑定的?
原来虚表上面的地址是指向一个结构 Derive::`RTTI Complete Object Locator , 这个结构指向该类的名字,和其对象继承链。
实现一个代码用来从RTTI中读取类的名字:
https://www.cnblogs.com/zhyg6516/archive/2011/03/07/1971898.html
4.3 函数的效能
编译器将视为不变的表达式提到循环之外,因此只计算一次。因此inline函数不仅可以节省一般函数调用带来
的额外负担也提供程序优化的额外机会。
4.4 指向Member Functions的指针
获取地址:https://blog.csdn.net/microsues/article/details/6452249
Derived d;
cout<<"&d="<<&d<<endl;
int *vptr1=(int*)*((int*)&d+0);//vptr1为virtual table[0]的地址
int *pf1=(int*)*((int*)*((int*)&d+0)+0);//pf1为virtual table[0]里的第一个虚拟函数
Derived::~Derived的地址
int sz=sizeof(Base1)/4;
int *vptr2=(int*)*((int*)&d+sz);//vptr2为virtual table[1]的地址
cout<<"vptr2="<<vptr2<<endl;
pf1=(int*)*((int*)*((int*)&d+sz)+0);//pf1为virtual table[1]里的第一个虚函数
cout<<"&vptr2[0]="<<&vptr2[0]<<endl;//这里是virtual table[1][0]的地址
cout<<"pf1="<<pf1<<endl;//这里是virtual table[1][0]里存储的地址,也就是真正函数的地址一个问题:开C语言深度剖析那本书的时候再细讲:
#include<iostream>
using namespace std;
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr1 = (int*)(&a+1);
int *ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);//ptr1[-1]值为5,ptr2会根据大小端来辨别。&a是一整个数组,而a也能代表一个数组但只存有a[0]一个。
system("pause");
}
4.5 Inline Functions
由于调用函数的开销比求解等价表达式要慢得多,在大多数机器上调用函数需要在调用前先保存寄存器,并在返回时恢复,复制实参,程序还必须转向一个新位置执行。内联展开也就是省去了写成函数的开销。如下代码:
inline int max(int a, int b)
{
return a > b ? a : b;
}
//会被内联展开为:cout<<max(a, b)<<endl;inline函数不能包含循环、switch、if语句。
在一个c文件中定义的inline不能在其他c文件中使用,最好将inline函数定义在一个**-inl.h头文件中。
不要过度的使用inline。
第五章:构造、解构、拷贝 语意学
什么是POD:
1.所有的标量类型(基本类型和指针类型)、POD结构类型、POD联合类型、以及这几种类型的数组、const/volatile修饰的版本都是POD类型。
2.不能有用户自定义的构造函数、析构函数、拷贝构造函数。
POD的本质是与c兼容的数据类型。也就是不受虚函数、C++特性等的影响,可以在转化成二进制时不发生变化。
Point *heap=new Point会转换为对new运算符的调用:
Point *heap=__new(sizeof(Point));
delete heap会被转化为__delete(heap);
构造函数入栈,析构函数出栈
并且构造是从基类开始的,每一个继承的类都是从基类构造函数一层层构造上去的。

拷贝构造函数
Point::Point(Point &p)
{
X=p.x;
Y=p.y;
cout<<"这里是拷贝构造函数"<<endl;
}拷贝构造函数使用的三个地方:
a.用类的一个对象去初始化该类的另一个对象
Point A(1,2);
Point B(A);b.函数的形参为类的对象
void fun1(Point p)
{
cout<<p.GetX()<<endl;
}
Point A(1,2);
fun1(A);c.函数的返回值是类的对象
Point fun2()
{
Point A(1,2);
return A;
}拷贝赋值函数
class Foo
{
public:
Foo& operator=(const Foo&);//返回自引用,拷贝新内容。都是同类型引用。
}重载是在一个类中有两个及以上的方法,要求方法名相同但参数却不相同。
动态重载与静态重载
动态重载是指继承多态,静态就是单纯的代码函数重载
int Max (int,int);//返回两个整数的最大值;
int Max (const vector <int> &);//返回vector容器中的最大值;
int Max (const matrix &);//返回matrix引用的最大值;
int Add (int a,int b);
float Add(int a,float b);
float Add(float a,int b);
float Add(float a,float b);第六章 执行期语意学
全局对象:class object会在编译时期放置在data segment并且内容为0,但constructor一直到程序及或是才会实施。cfront的实现策略是munch策略,会产生__sti()和__std()函数,以及一组运行时库,一个_main()函数,一个_exit()函数。
局部静态对象:
const Matrix & identity(){
static Matrix mat_identity;//mat_identity的constructor和destructor必须只能执行一次,就算函数被调用很多次,会有一个临时变量的导入来判断constructor是否已经被调用过。
return mat_identity;
}
对象数组:
#include<iostream>
using namespace std;
class CSample{
public:
CSample(){ //构造函数 1
cout<<"Constructor 1 Called"<<endl;
}
CSample(int n){ //构造函数 2
cout<<"Constructor 2 Called"<<endl;
}
}
int main(){
CSample arrayl[2];
cout<<"stepl"<<endl;
CSample array2[2] = {4, 5};
cout<<"step2"<<endl;
CSample array3[2] = {3};
cout<<"step3"<<endl;
CSample* array4 = new CSample[2];
delete [] array4;
return 0;
}输出结果:
Constructor 1 Called
Constructor 1 Called
stepl
Constructor 2 Called
Constructor 2 Called
step2
Constructor 2 Called
Constructor 1 Called
step3
Constructor 1 Called
Constructor 1 Called
class CTest{
public:
CTest(int n){ } //构造函数(1)
CTest(int n, int m){ } //构造函数(2)
CTest(){ } //构造函数(3)
};
int main(){
//三个元素分别用构造函数(1)、(2)、(3) 初始化
CTest arrayl [3] = { 1, CTest (1, 2) };
//三个元素分别用构造函数(2)、(2)、(1)初始化
CTest array2[3] = { CTest(2,3), CTest (1,2), 1};
//两个元素指向的对象分别用构造函数(1)、(2)初始化
CTest* pArray[3] = { new CTest(4) , new CTest(1,2) };
return 0;
}
只要对象里声明了构造函数&析构函数,对象数组里的每个元素都需要进行构造&析构操作。
对象的new和delete
Point3d *origin=new Point3d;
//被转化为:
Point3d *origin;
if(origin=__new(sizeof(Point3d)))
Point3d::Point3d(origin);
delete originl;
//被转化为
if(orgin!=0)
{
Point3d::~Point3d(origin);
__delete(orgin);
}
针对数组的new的情况:
如果class中定义有一个default constructor,某些版本的vec_new()就会被调用配置并构造class objects组成的数组。
Point3d *p_array=new Point3d[10];//通常会被编译为Point3d *p_array;
p_array=vec_new(0,sizeof(Point3d),10,&Point3d::Point3d,&Point3d::~Point3d);