文章目录
第 1 章、神经网络如何工作
1.1、尺有所短,寸有所长
计算机和人的关系:尺有所短,寸有所长
有些任务,对传统的计算机而言很容易,对人类而言却很难。例如,对数百万个数字进行乘法运算。
另一方面,有些任务对传统的计算机而言很难,对人类而言却很容易。例如,从一群人的照片中识别出面孔。
1.2、一台简单的预测
1、思想过程
人类:问题->思考->答案
计算机:输入->流程(计算)->输出
计算机的实例:输入(3*4)->流程(4+4+4)->输出(12)
所有有用的计算机系统都有一个输入和一个输出,并在输入和输出之间进行某种类型的计算。神经网络也是如此。
2、案例
一个预测案例:千米和英里的转换
计算机:输入(千米)->流程(?)->输出(英里)
已知:千米和英里之间的关系是线性的。(这里,“线性的”被叫做模型)
一些线索:0千米=0英里 100千米=62.137英里
所以,假设流程是英里=千米*C(根据“线性的”模型得到的公式)
假设C=0.5,得到100千米=50英里,和目标62.137英里差距是12.137,这个12.137被叫做误差。
然后,修改参数值,0.5变成0.6,100千米=60英里,和目标62.137英里差距是2.137,现在这个误差比之前好多了。
然后,修改参数值,0.6变成0.7,100千米=70英里,和目标62.137英里差距是-7.863,这个误差的负号告诉我们,我们超调了。
那么我们将参数值变成0.61,100千米=61英里,和目标62.137英里差距是1.137,现在这个误差比之前好多了,这改变参数的方法,叫做学习率,在梯度下降法中又叫步长。
3、启发
通过预测案例得到的启发
误差的大小指导如何改变参数C的值。
大误差意味着大的修正值,小误差意味着小的修正值。
迭代:尝试得到一个答案,并多次改进答案,这是种方法叫做迭代。
当我们不能精确知道一些事情如何运作时,我们可以尝试使用模型来估计其运作方式,在模型中,包括了我们可以调整的参数。如果我们不知道如何将千米转换为英里,那么我们可以使用线性函数作为模型,并使用可调节的梯度值作为参数。
改进这些模型中参数的一种好方法是,基于模型和已知真实示例之间的比较,得到模型偏移的误差值,调整参数。
选择正确的模型很重要。
1.3、分类器与预测器并无太大差别
预测器:机器接受了一个输入,并作出应有的预测,输出结果。
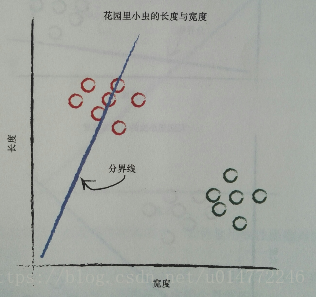
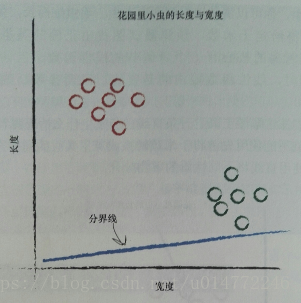
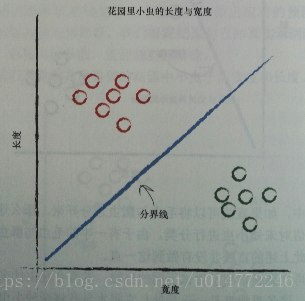
书中举了个根据长度和宽度分类花园里毛虫和瓢虫的案例。
因为毛虫细而长,瓢虫短而宽,所以可以用一条线来分开。
在修改这条线的过程中,用预测器来做参数的改变,其实也就是分类。
所以,分类器和预测期并没有太大差别,机制都是一样的。
1.4、训练简单的分类
1、例子引入
根据一个数据来设置分割线的例子讲解:
还是之前1.3的分类毛虫和瓢虫的问题。
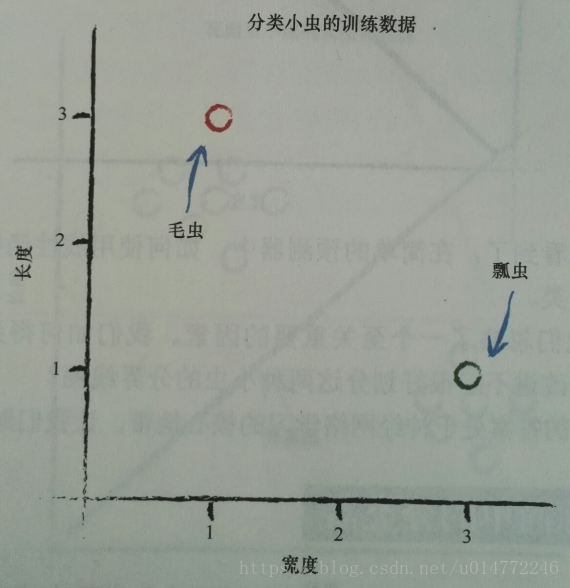
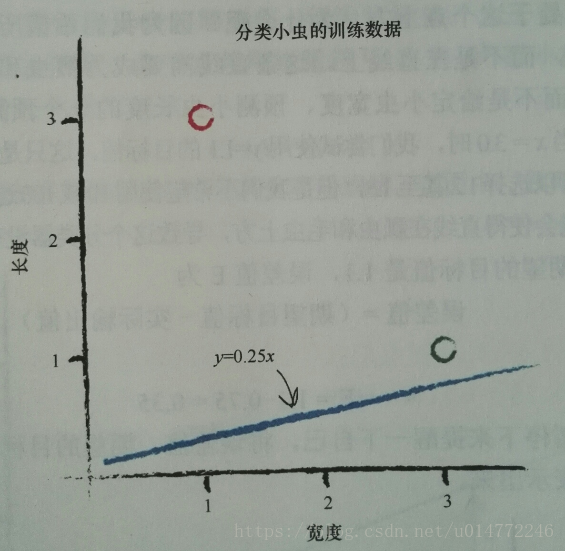
假设模型为线性的,分界线函数为y=Ax,长度为y,宽度为x。
已知有两个实例:
瓢虫:宽3.0 长:1.0
毛虫:宽1.0 长:3.0
即:
从常识A=0.25开始,即:
我们做什么样的期望呢,即:我们希望毛虫得到的结果Y都在这条线的下方,瓢虫得到的结果Y都在这条线的上方。
期望值是多少呢,我们希望瓢虫得到的结果Y都在这条线的上方,现在的瓢虫的数据是(3.0,1.0),即我们期望的值应该比1.0大一些,注意,大一点即可,比如1.1,所以,瓢虫的期望目标值为1.1。同理,希望毛虫得到的结果Y都在这条线的下方,毛虫的是(1.0,3.0),所以假设毛虫的期望目标值是2.9即可。
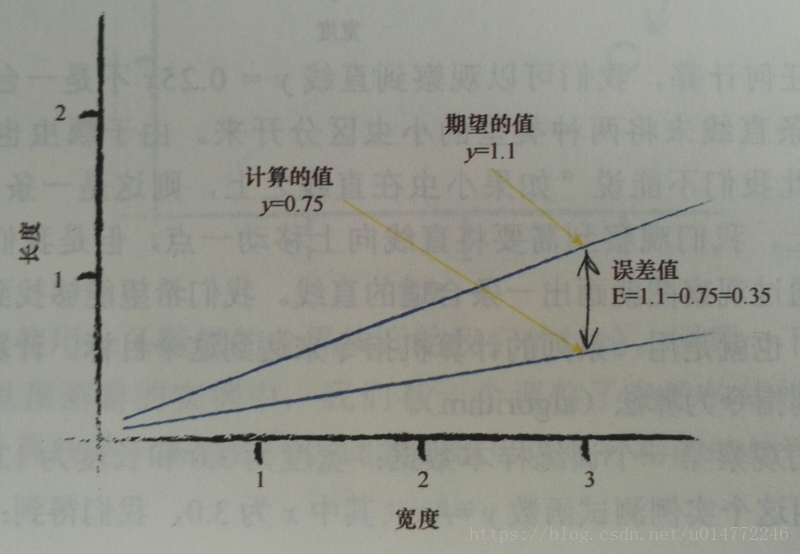
误差值=(期望目标值-实际输出值)。
所以,瓢虫的数据在A=0.25的情况下,得到的误差值E=1.1-(0.253)=1.1-0.75=0.35。
如下图所示:
现在,我们的任务是对A做调整,用以得到合适的A,方法是要对E做些什么,来调整A,即用E来调整A(根据误差调整参数的思想)。
E是误差值,根据期望值算出来的y叫做目标值t,t=(A+ΔA)x
所以这里瓢虫的期望值作为目标值,即目标值t=1.1。那么误差E=目标值-实际输出=t-y=(A+ΔA)x-Ax=ΔAx。
所以E和ΔA系就有了,可以使用误差E,讲所得到的ΔA所谓调整分界线的斜率A的量,来调整A,是之得到正确的A。
比如上例,误差值E为0.35,x=0.3。这样ΔA=E/x=0.35/3=0.1167,这样目标t=当前的A+当前的ΔA即t=0.25+0.1167=0.3667,这样计算出来的y=0.3667*3=1.1,即为目标结果。
同理,如果根据毛虫的数据设定目标值,将目标值定为2.9,这样误差E=2.9-0.3667=2.5333,ΔA=E/x=2.5333/1.0=2.5333,则新的A=0.3667+2.5333=2.9,得到了目标期望值。
2、改进
机器学习的一个重要思路,我们应该进行适度改进(moderate),即我们不要改进的过于激烈。也就是说不要一下子将本次的A改进到目标的A。
这种自我节制的调整,还带来了一个非常强大、行之有效的“副作用”。当训练数据本身不能确信为完全正确并且包含在现实世界测量中普遍出现的错误或噪声这两种情况时,有节制的调整可以抑制这些错误或噪声的影响。这种方法使得错误或噪声得到了调解和缓和。
这次,我们添加一个调剂系数:ΔA=L* (E/x),假设L=0.5,第一次训练,x=3.0,A=0.25,y=0.253.0=0.75,期望值为1.1,得到了误差值E为0.35,ΔA=L (E/x)=0.0583,更新后的A为0.25+0. 0583=0.3083。
使用更新后的A进行第二次训练,x=3.0,A=0.3083,y=0. 3083*3.0=0.9250,期望值为小于1.1,虽然还是错误的,但是再进行多次训练,总能正确,因为这条直线确实向正确的方向移动了。
3、结论
我们使用简单的数学,理解了线性分类器输出误差值和可调节斜率参数之间的关系。也就是说,我们知道了在何种程度上调整斜率,可以消除输出误差值。
使用朴素的调整方法会出现一个问题,即改进后的模型只与最后一次训练样本最匹配,“有效地”忽略了所有以前的训练样本。解决这个问题的一种好方法是使用学习率:调节改进速率,这样单一的训练样本就不能主导整个学习过程。
来自真实世界的训练样本可能充满噪声或包含错误。适度更新有助于限制这些错误样本的影响。
1.5、有时候一个分类器不足以求解问题
如果数据本身不是由单一线性过程支配,那么一个简单的线性分器不能对数据进行划分。例如,由逻辑XOR运算符支配的数据明了这一点。
但是解决方案很容易,你只需要使用多个线性分类器来划分由单直线无法分离的数据。
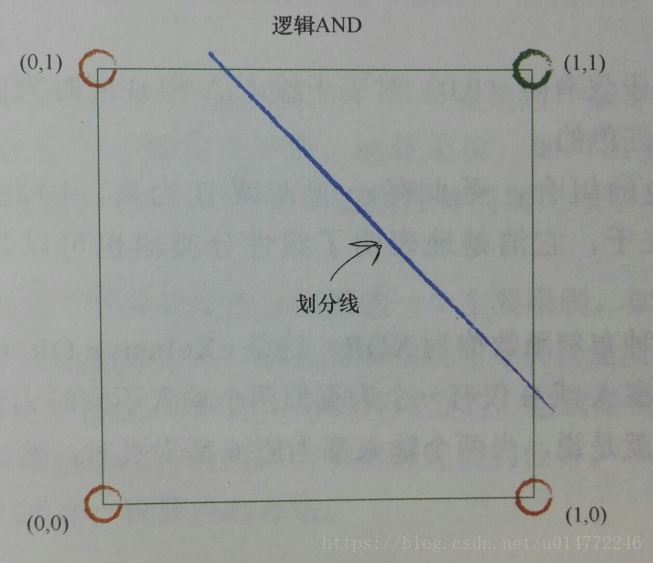
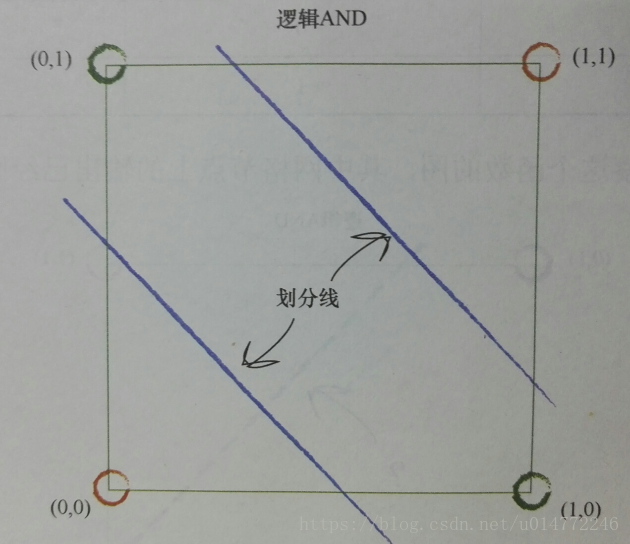
比如,逻辑and运算的分类,一个分类器解决问题:
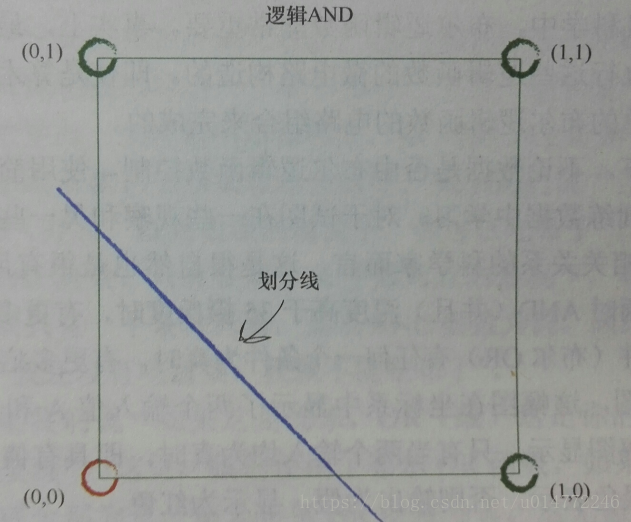
比如逻辑or运算的分类(书上的这个标题写错了),一个分类器解决问题:
比如逻辑xor运算(异或)的分类(书上的这个标题写错了),就得两个分类器了:
神经网络的核心思想:使用多个分类器一起工作,多条直线可以分离出异常状的区域,对各个区域进行分类。
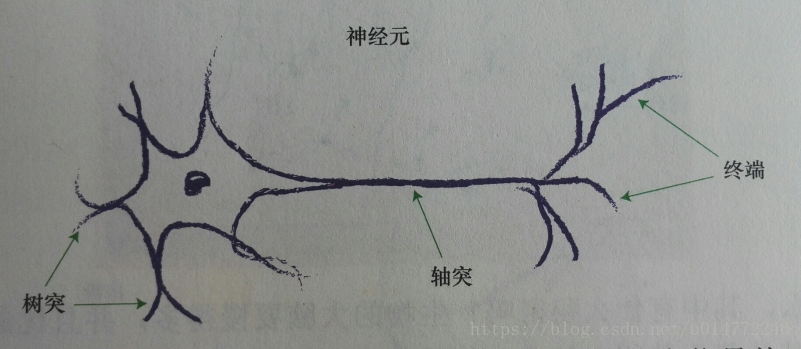
1.6、神经元——大自然的计算机器
1、神经元的结构
由上图可知,单个神经元通过树突接收一些神经元给他的信号,即电输入,经过轴突的传递,发送给终端,也就是突触,然后传递给下一个神经元。
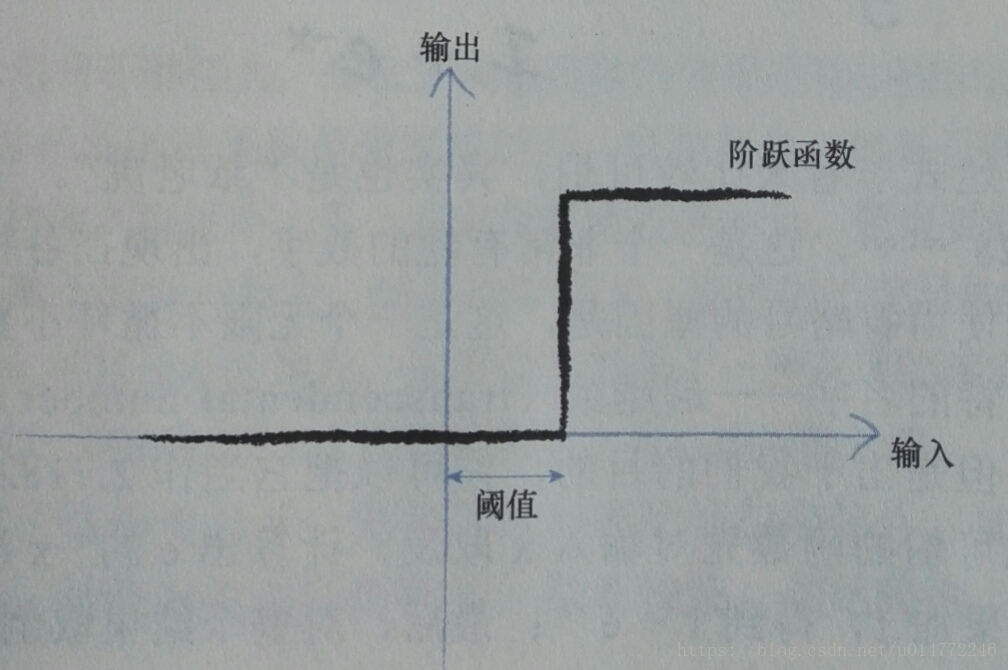
2、阈值(threshold)
观察表明:神经元不会立即反应,而是会抑制输入,直到输入增强,强大到可以触发输出。一些简单的阶跃函数可以实现这种效果,如下图所示:
改进阶跃函数,如下图所使用的sigmoid函数。书中解释是:“这个函数,比起冷冰冰、硬邦邦的阶跃函数要相对平滑,这使得这个函数更自然、更接近现实。自然界很少有冰冷尖锐的边缘!”
这点我觉得解释的不够,要么就是这个函数和神经元的机制更像,要么就是他对预测结果更好,他仅仅是说更平滑,更接近自然,难道更平滑和更接近自然和神经元的机制有关系吗,还是对预测机制有好处?
Sigmoid函数的表达形式如下所示:
Sigmoid函数的优点:一个是它比较简单,事实上也非常常见,另一个原因是比其他S型函数计算起来容易得多。

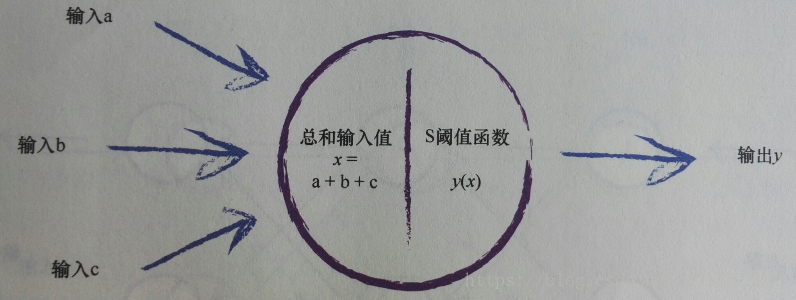
3、输入问题
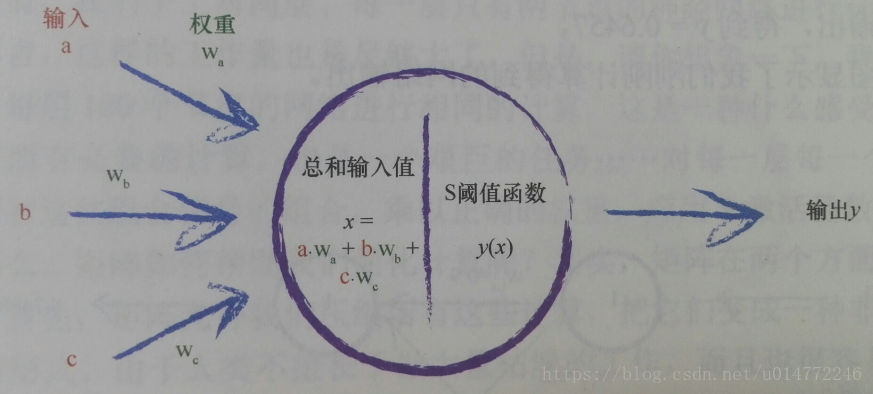
现在,整理一下整个神经元的模拟结果,如下图所示:
书上说:“对于所有这些输入,我们只需对它们进行相加,到最终总和,作为 S 函数的输入, 然后输出结果。 这实际上反映了神经元工作机制。”
后面有说了:“如果组合信号不够强大, 那么 S 阈值函数的效果是抑制输出信号。 如果和x足够大, S 函数的效果就是激发神经元。”
还有:“如果中一些输入,单个而言一般大,但不是非常大,这样由于信号的组合足够大超过阈值, 那么神经元也能激发。”
说明了神经元的各个输入的信号电量大小是不同的。
4、权重
本来神经元的结构如下所示:
当前信号传到后一个的各个神经元都是一样的。
但是,为了执行学习功能,为了针对训练样本做出调整和反应,为了达到之前线性分类器中斜率类似的参数可以供我们调整的效果,所以给每个连接设置权重。
采用完全连接形式的原因:
(1)、这种一致的完全连接形式事实上可以相对容易地编码成计算机指令
(2)、神经网络的学习过程将会弱化这些实际上不需要的连接(也就是这些连接的权重将趋近于0),因此对于解决特定任务所需最小数量的连接冗余几个连接,也无伤大雅。
(3)、随着神经网络学习过程的进行,神经网络通过调整优化网络内部的链接权重改进输出,一些权重可能会变为零或接近于零。零或几乎为零的权重意味着这些链接对网络的贡献为零,因为没有传递信号。零权重意味着信号乘以零,结果得到零,因此这个链接实际上是被断开了。
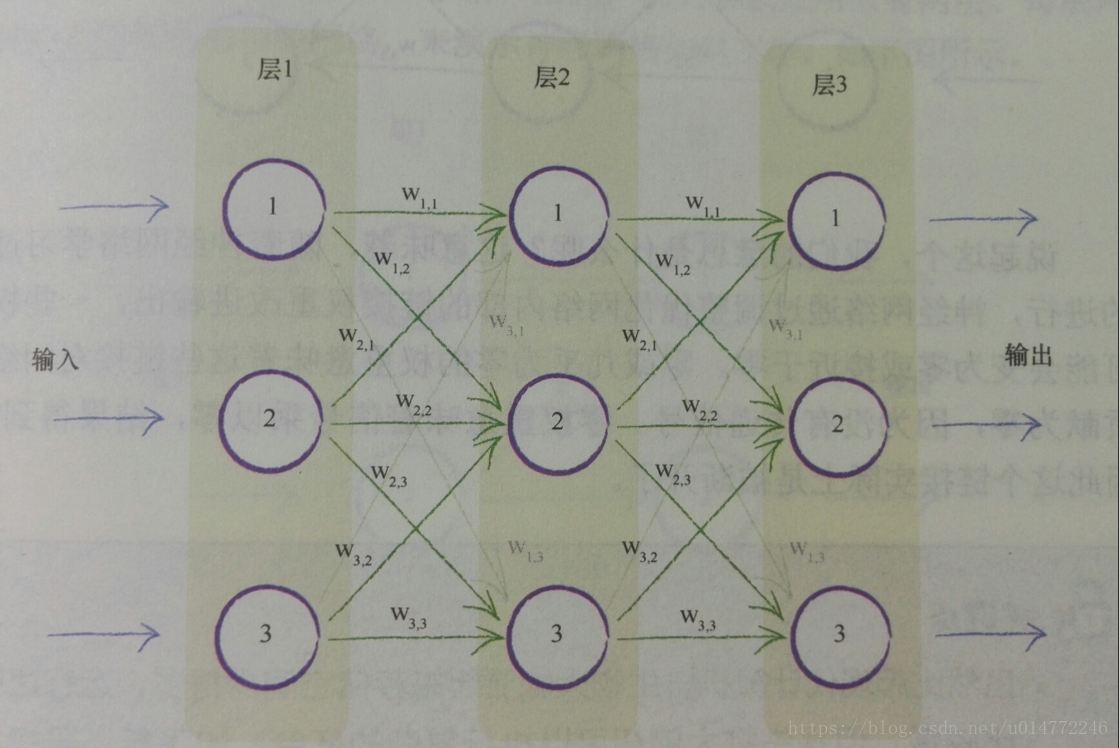
1.7、在神经网络中追踪信号
本节模拟了输入如何在神经网络中变成输出的过程。使用的是一个很简单的神经网络。
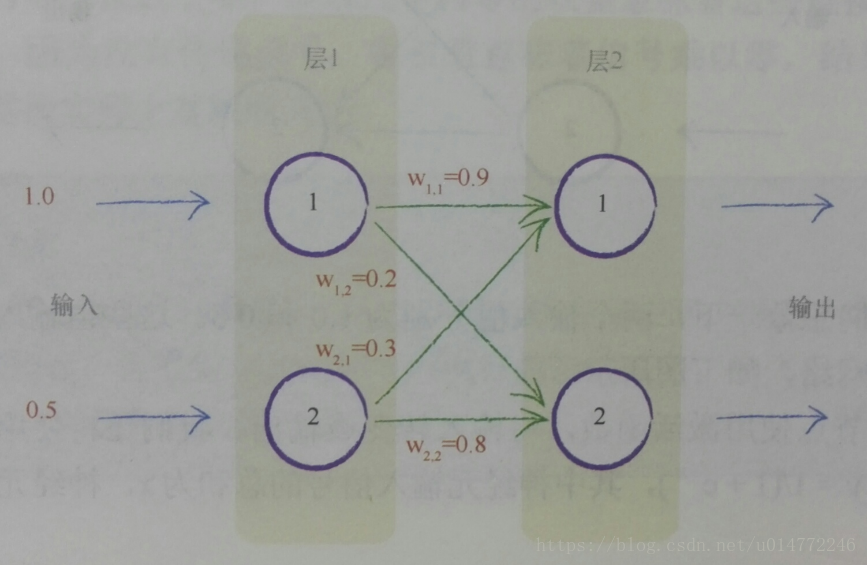
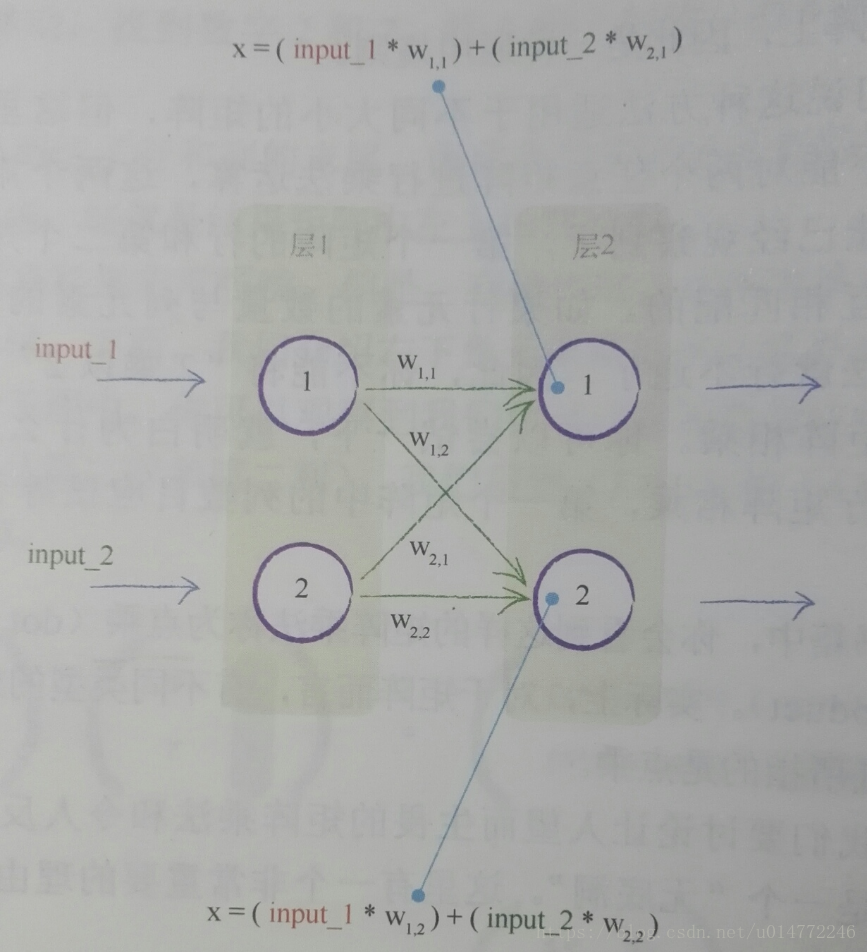
如下图,一个简单的神经网络示意图,两个输入分别为1.0和0.5,四个权重也已经标在了图上。
按照下图的原理进行计算,在前几节已经做了一些解释。
则第2层1结点的输出为:y(x)=y((1.00.9)+(0.50.3))=y(0.9+0.15)=y(1.05)=1/(1+e^(-1.05))=1/(1+0.3499)=0.7408
同理,第2层2结点的输出为:0.6457
除了计算量大一些,好像并不难。
1.8、凭心而论,矩阵乘法大有用途
本节用大量的语音解释了矩阵的点乘的原理,这里我就不详细记录了,都是学过好几遍的东西。
重点记录一下关于神经网络的东西。
对于上一节所描述的计算,假设有权值矩阵和输入值矩阵,并将其做点乘运算,将会得到如下结果:
在来看看上一节的示意图:
就会发现第2层的两个结点的输入,正好和矩阵运算的结果一样。
所以有结论:X=W·I,此处,W是权重矩阵,I是输入矩阵,X是组合调节后的信号,即输入到第2层的结果矩阵。
所以,第二次的最终输出O=sigmoid(X),O代表来自神经网络最后一层的所有输出。
通过神经网络向前馈送信号所需的大量运算可以表示为矩阵乘法。
不管神经网络的规模如何,将输入输出表达为矩阵乘法,使得我们可以更简洁地进行书写。
更重要的是,一些计算机编程语言理解矩阵计算,并认识到潜在的计算方法的相似性。这允许计算机高速高效地进行这些计算。
未完待续······
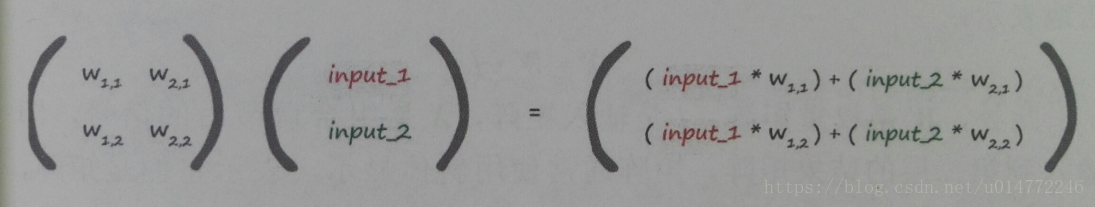
另:一些说明
1、本博客仅用于学习交流,欢迎大家瞧瞧看看,为了方便大家学习。
2、如果原作者认为侵权,请及时联系我,我的qq是244509154,邮箱是[email protected],我会及时删除侵权文章。
3、我的文章大家如果觉得对您有帮助或者您喜欢,请您在转载的时候请注明来源,不管是我的还是其他原作者,我希望这些有用的文章的作者能被大家记住。
4、最后希望大家多多的交流,提高自己,从而对社会和自己创造更大的价值。