二叉排序树
又称为二叉查找树。它或者是一棵空树,或者是具有下列性质的二叉树,
1. 若它的左子树不空,则左子树上的所有结点的值均小于它的根结构值
2. 若它的右子树不空,则右子树上的所有结点的值均大于它的根结点值
3. 它的左、右子树也分别为二叉排序树。
二叉排序树查找操作
首先我们提供一个二叉树的结构
typedef struct BiTNode
{
int data;
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree然后我们来看一下二叉排序树的查找是如何实现的
/*
递归查找二叉排序树T中是否存在key,指针f指向T的双亲,其初始调用值为NULL
若查找成功,则指针p指向该数据元素结点,并返回TRUE
否则指针p指向查找路径上访问的最后一个结点并返回FALSE
*/
Status SearchBST(BiTree T,int key,BiTree f,BiTree *p)
{
if(!T)
{
*p=f;
return FALSE;
}
else if(key==T->data)
{
*p = T
return TRUE;
}
else if(key<T->data)
{
return SearchBST(T->lchild,key,T,p); //在左子树中查找
}
else
return SearchBST(T->lchild,key,T,p); //在右子树中查找
}二叉排序树插入操作
有了二叉排序树的查找函数,那么所谓的二叉排序树的插入,其实也就是将关键字放到树中的合适位置。代码如下
/*
当二叉排序树T中不存在关键字等于key的数据元素时,插入key并返回TRUE,否则返回FLASE
*/
Status InsertBST(BiTree *T,int key)
{
BiTree p,s
if(!SearchBST(*T,key,NULL,&p))/*查找不成功*/
{
s =(BiTree)malloc(sizeof(BiTNode));
s->data = key;
s->lchild=s->rchild=NULL;
if(!p)
*T = s; //插入s为新的根结点
else if(key<p->data)
p->lchild = s;
else
p->rchild = s;
return TRUE;
}else
return FALSE;
}
有了二叉排序树的插入代码,我们要实现二叉排序树的构建非常容易了,如下代码
int i
int a[10] = {62,88,58,47,35,73,51,99,37,93};
BiTree T=NULL;
for(i=0;i<10;i++)
{
InsertBST(&T,a[i]);
}二叉排序树的删除操作
俗话说“请神容易送神难”,我们已经介绍了二叉排序树的查找与插入算法,但是对于二叉排序树的删除,就不是那么容易,我们不能因为删除了结点,而让这棵树变得不满足二叉排序树的特性,所以删除需要考虑多种情况,删除叶子结点没有问题,因为对整个树来说,其他结点的结构并未受到影响。
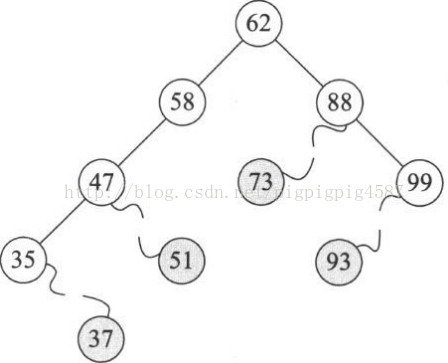
删除只有左子树或只有右子树的情况,相对也比较好解决,那就是结点删除后,将它的左子树或右子树整个移动到删除结点的位置即可,可以理解为独子继承父业。
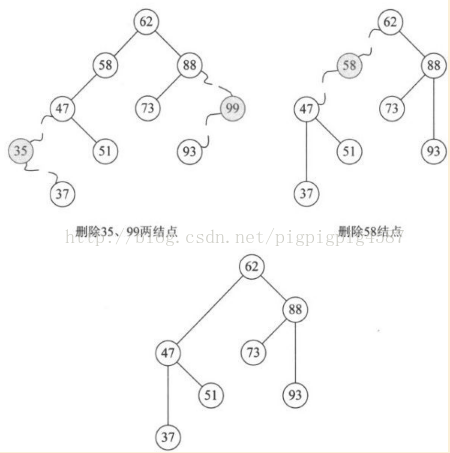
但是对于要删除的结点既有左子树又有右子树的情况怎么办呢?
上图这种重新挨个插入效率不高且不说,还会导致整个二叉排序树结构发生很大的变化,有可能会增加树的调试。增加调试可不是个好事,这我们待会再说。
我们仔细观察一下,47的两个子树中能否找出一个结点可以代替47呢?果然有,37或者48都可以代替47,此时在删除47后,整个二叉排序树并没有必生本质的改变。
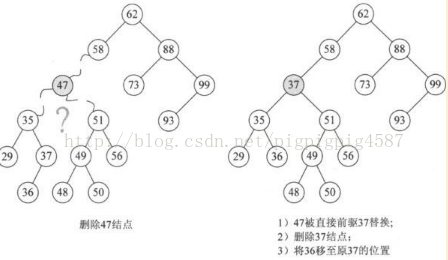
为什么是37和48?对的,它们正好是二叉排序树中比它小或比它大的最接近47的两个数。也就是说,如果我们对这棵二叉排序树进行中序遍历,得到的序列
{25,35,36,37,47,48,49,50,51,56,58,62,73,88,93,99}
它们正好是47的前驱和后继。
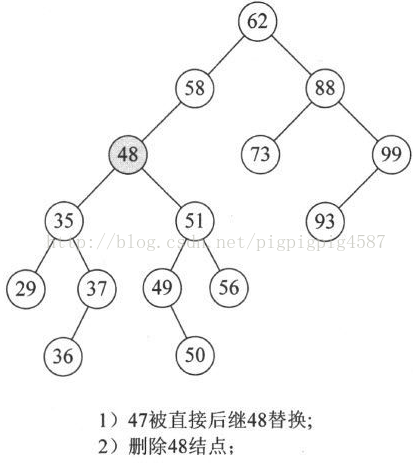
因此比较好的办法就是,找到需要删除的结点p的直接前驱(或直接后继)s,用s来替换结点p,然后再删除此结点s
根据分析 有三种情况:
n 叶子结点
n 仅有左或右子树的结点
n 左右子树都有的结点,我们来看代码,下面这个算法是递归方式对二叉排序树T查找key,查找到时删除
/*
若二叉排序树T中存在关键字等于key的数据元素时,则删除该数据元素结点
并返回TRUE,否则返回FALSE
*/
Status DeleteBST(BiTree *T,int key)
{
if(!*T) //不存在关键字等于key的数据元素
return FALSE;
else
{
if(key==(*T)->data)
return Delete(T);
else if(key<(*T)->data)
return DeleteBST(&(*T)->lchild,key);
else
return DeleteBST(&(&T)->rchild,key);
}
}
/*从二叉排序树中删除结点p,并重接它左或右子树*/
Status Delete(BiTree *p)
{
BiTree q,s;
if((*p)->rchild==NULL) //重接左子树
{
q=(*p);*p=(*p)-lchild;free(q);
}
else if((*p)->lchild==NULL)
{
q=*p;*p=(*p)->rchild;free(q);
}
else //左右子树都不为空
{
q=*p;s=(*p)-lchild;
while(s->rchild)
{
q=s;s=s->rchild; /*转左,然后向右到尽头*/
}
(*p)->data=s->data; //s指向被删结点的直接前驱
if(q!=*p)
q->rchild=s->lchild;//重接q右子树
else
q->lchild=s->lchild; //重接q左子树
free(s);
}
return TRUE;
}
1. 程序开始执行,代码4~7行的目的是为了删除没有右子树只有左子树的结点。此时只需将此结点的左孩子替换它自己,然后释放此结点内存,就等于删除了。
2. 代码第8~11行是同样的道理处理只有右子树没有左子树的结点删除问题。
3. 第12~25行处理复杂的左右子树均存在的问题
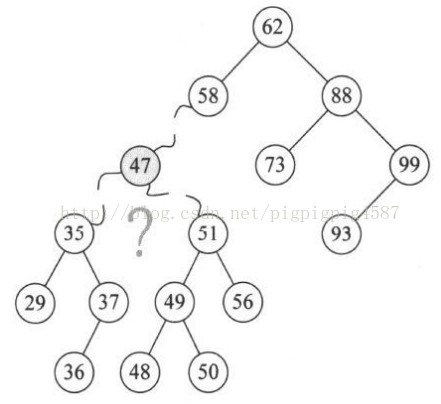
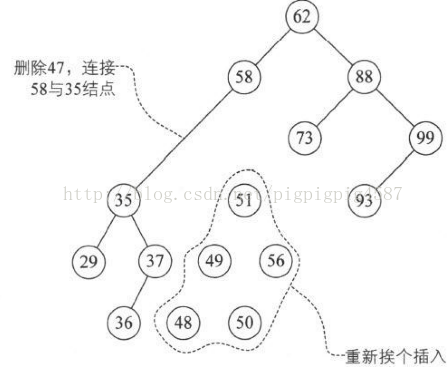
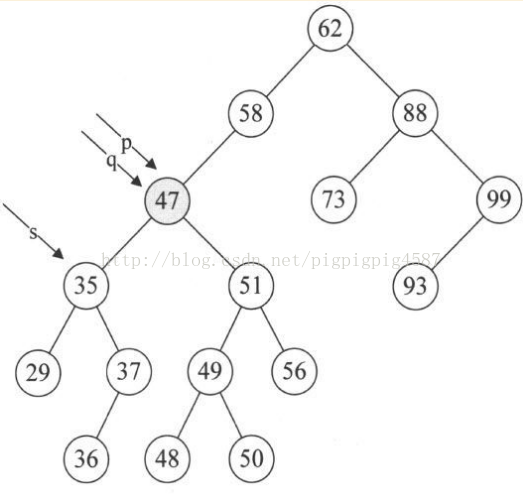
4. 第14行,将要删除的结点p赋值给临时的变量q,再将p的左孩子p->lchild赋值给临时的变量s。此时q指向47结点,s指向35结点。如图
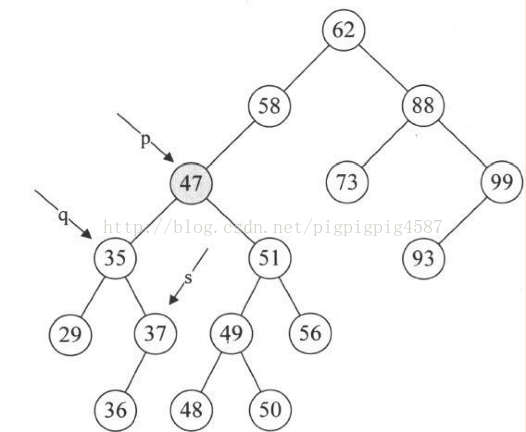
5. 第15~18行,循环找到左子树的右结点,直到右侧尽头。就当前例子来说,就让q指向35,而s指向37这个没有右子树的结点,如图
6. 第19行,此时要删除结点p的位置的数据被赋值为s->data,即让p->data=37,如图
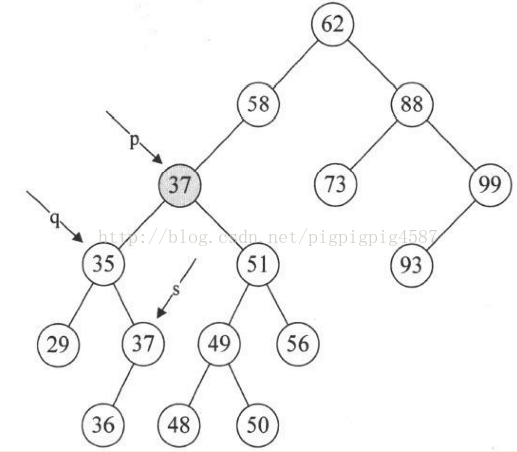
7. 第20~23行,如果p和q指向不同,则将s->lchild赋值给q->rchild,否则就是将s->lchild赋值给q->lchild。显然这个例子p不等于q,将s->lchild指向的36赋值给q->rchild,也就是让q->rchild指向36结点,如图
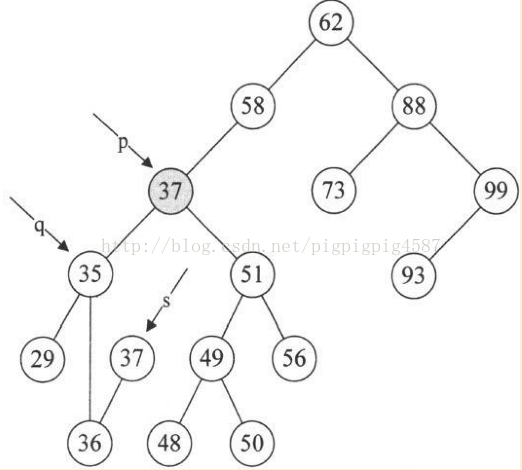
8. 第24行,free(s),就非常好理解了,将37结点删除,
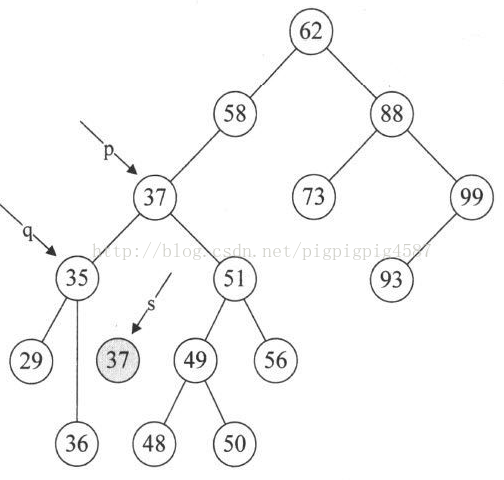
从这段代码也可以看出,我们其实是在找删除结点的前驱结点替换的方法,对于后继结点来替换,方法上是一样的
二叉排序树总结
二叉排序树是以树是以链接的方式存储,保持了链接存储结构在执行插入或删除操作时不用移动元素的优点,只要找到合适的插入和删除位置后,仅需要修改链接指针即可。插入删除的时间性能比较好。而对于二叉排序树的查找,走的就是人根结点到要查找的结点的路径,其比较次数等于给定值的结点在二叉树的层数。极端情况,最少为1次,最多也不超过树的深度。也就说,二叉排序树的查找性能取决于二叉排序树的形状。
如图
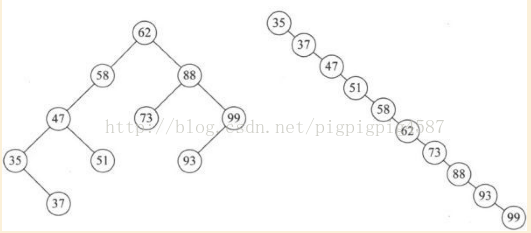
{62,88,58,47,35,73,51,99,37,93}这样的数组,我可以表示为上图左图的二叉排序树。
但如果数组元素的次序是从小到大的有序,如
{35,37,47,51,58,62,73,88,93,99},则二叉排序树就成了极端的右斜树,注意它依然是一棵二叉排序树,如上图右。同样去找99。左图比较两次,右图要比较10次。二者差异很大的
也就是说,我们希望二叉排序树是比较平衡的,即其深度与完全二叉树相同,均为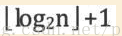
平衡二叉树(AVL树)
平衡二叉树(Self-Blancing Binary Search Tree 或 Height-Blanced Binary Search Tree)是一种二叉排序树,其中每个节点的左子树和右子树的高度差至多等于1。
我们将二叉树上结点的左子树深度减去右子树深度的值称为平衡因子BF(Balance Factor)
那么平衡二叉树上所有结点的平衡因子只可能是-1、0、1。只要二叉树上所有结点的平衡因子的绝对值大于1,则该二叉树就是不平衡的。如图
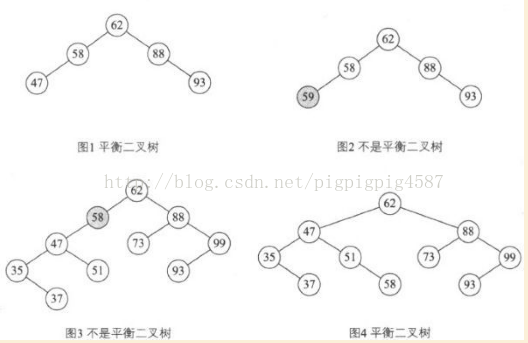
为什么上图1是平衡二叉树,图2不是?这就考查我们对平衡二叉树的定义的理解,它的前提首先是一棵二叉排序树。
图3不是的原因是,结点左子树高度是3,右是0,差值大于1啦。不符合定义。
距离插入结点最近的,且平衡因子的绝对值大于1的结点为根的子树,我们称为最小不平衡树。如图
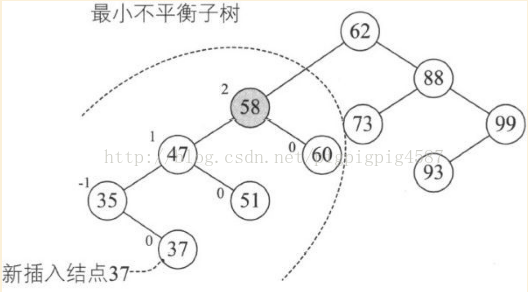
新插入结点37时,距离它最近的平衡因子绝对值超过1的结点是58,所以从58开始以下的子树为最小不平衡子树。
平衡二叉树实现原理
平衡二叉树构建的基本思想就是在构建二叉排序 树的过程中,每当插入一个结点时,先检查是否因插入而破坏了树的平衡性,若是,则找出最小不平衡子树。在保持二叉排序树特性的前提下,调整最小不平衡子树中各结点之间的链接关系,进行相应的旋转,使之成为新的平衡子树。
为了在学习算法时能够轻松一些,我们先讲一个平衡二叉树的构建过程。如
{3,2,1,4,5,6,7,10,9,8}需要构建二叉排序树。在没有学习平衡二叉树之前,根据二叉排序树的特性,我们通常会将它构建成下图左
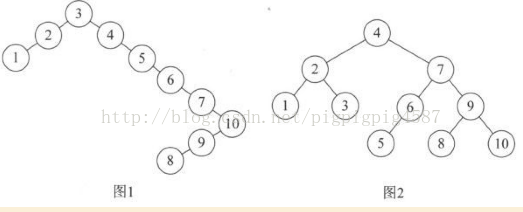
虽然符合二叉排序树的定义,但是对这样的高度达到8的二叉树来说,查找是非常不利的。我们更期望能构建右图那的二叉排序树。
对于数组{3,2,1,4,5,6,7,10,9,8}的前两们3和2,我们很正常地构建,到了第3个数时“1”时,发现此时根结点“3”的平衡因子变成了2,此时整棵树都成了最小不平不平衡子树,因此需要调整,如图,结点左上角的数字为平衡因子BF值。因为BF值为正,因此我们将整个树进行右旋(顺时针旋转),此时结点2成了根结点,3成了2的右孩子这样三个结点的BF值均为0。非常平衡如图2
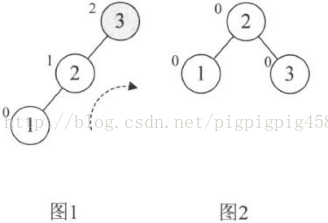
然后我们再增加结点4,平衡因子没有超出限定范围,如图3
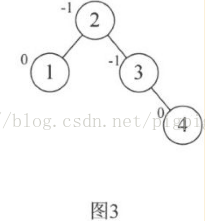
增加结点5时,结点3的BF为-2说明要旋转了。由于BF是负值,所以我们对这棵最小不平衡子树进行左旋(逆时针旋转)图4
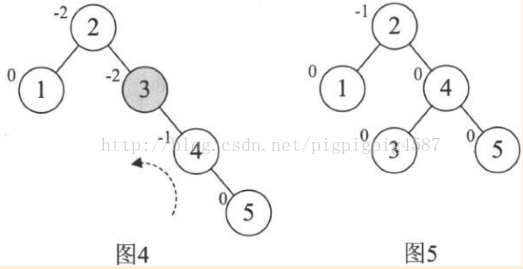
继续,增加结点6时,发现根结点2的BF值变成了-2,如下图6。所以对根结点进行了左旋,注意此时本来结点3是4的左孩子,由于旋转后需要满足二叉排序树特性,因此它成了结点2的右孩子,如图7。增加结点7, 同样的左旋转,使得整棵树达到平衡,如图8,图9
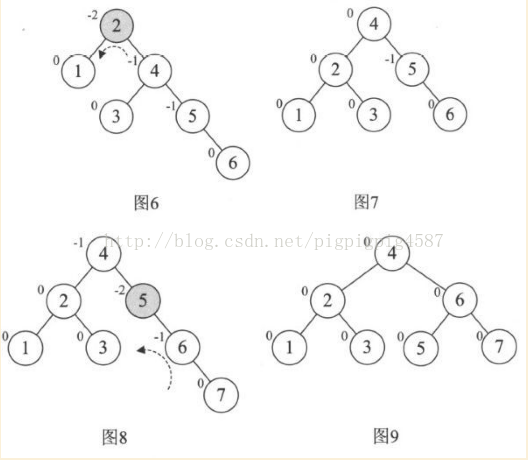
当增加结点10时,结构无变化,如图10。
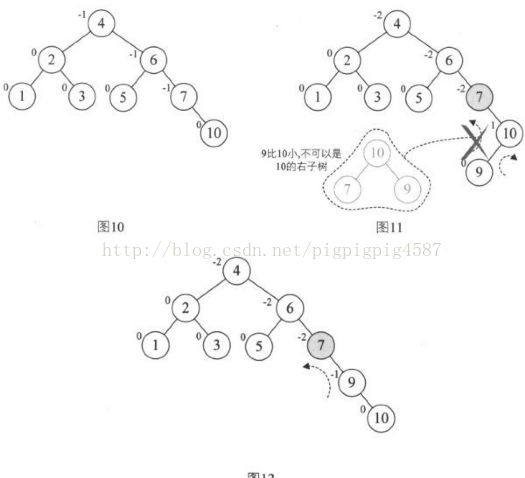
再增加结点9,此时结点7的BF的变成了-2,理论上我们只需要旋转最小不平衡子树7、9、10即可,但是如果左旋转后,结点9就成了10的右孩子,这不符合二叉排序树的特性的。此时不能简单的左旋。
仔细观察图11,发现根本原因在于结点7的BF是-2,而结点10的BF是1,也就是说,它们俩一正一负,符号并不统一,而前面几次旋转,无论左还是右旋,最小不平衡树的根结点与它的子结点符号都是相同的。这就是不能直接旋转的关键。
不统一,就将其统一。于是我们对结点9和结点10进行右旋,使得结点10成为9的右子树,结点9的BF为-1,此时就与结点7的BF值符号统一了,如图12
这样我们再以结点7为最小不平衡树进行左旋,得到图13。
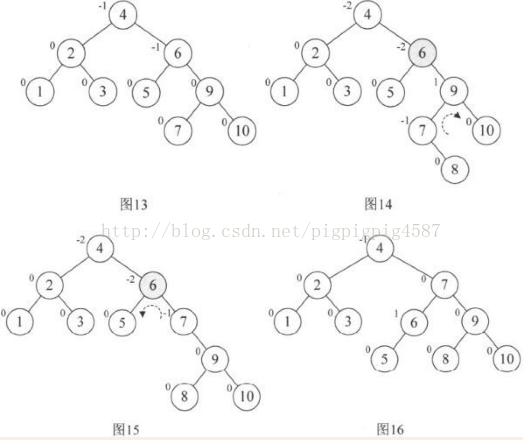
接着插入8,情况与赐教类似,结点6的BF是-2,而它的右孩子9的BF是1,因此首先以9为根结点,进行右旋,得到图15.此时结点6,7的符号都是负的,再以结点6为根结点左旋,最终得到最后的平衡二叉树,如图
平衡二叉树实现算法
首先是需要改进二叉排序树的结点结构,增加一个bf,用来存储平衡因子。
typedef struct BiTNode
{
int data;
int bf;
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;然后对右旋操作,代码如下
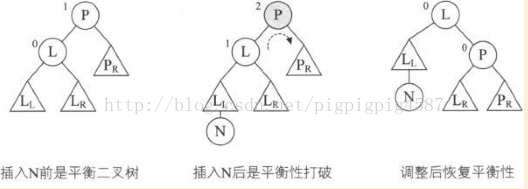
/*对以p为根的二叉排序树作右旋处理,处理之后,p指向新的根结点,即处理之前的左子树的根结点*/
void R_Rotate(BiTree *P)
{
BiTree L;
L = (*P)->lchild;
(*P)-lchild=L->rchild;
L-rchild=(*P);
(*P) = L; //P指向新的根结点
}此函数代码的意思就是,当传入一个二叉排序树P,将它的左孩子结点定义为L,将L的右子树变成P的左子树,再将P改成L的右子树,最后将L替换P成为根结点。这样就完成了一次右旋操作,如下图:
左旋操作代码哪下:
void L_Rotate(BiTree *P)
{
BiTree R;
R= (*P)->rchild;
(*P)->rchild=R->lchild; //R的左子树挂为P的右子树
R->lchild=(*P);
*P=R;
}
左平衡旋转处理的函数代码
#define LH +1; //左高
#define EH 0; //等高
#define RH -1; //右高
/*
对于指针T所指结点为根的二叉树作左平衡旋转处理
本算法结束时,指针T指向新的根结点
*/
void LeftBalance(BiTree *T)
{
BiTree L,Lr;
L=(*T)->lchild; //指向T的左子树根结点
switch(L->bf)
{
//检查T的碟子树的平衡度,并作相应的平衡处理
case LH://新结点插入在T的左孩子的左子树上,要作单右旋处理
(*T)->bf=L->bf=EH;
R_Rotate(T);
break;
case RH://新结点插入在T的左孩子的右子树上,要作双旋处理
Lr = L->rchild;//Lr指向T的左孩子的右子树根
switch(Lr->bf) //修改T及其左孩子的平衡因子
{
case LH:(*T)->bf=RH;
L->bf=EH;
break;
case EH: (*T)->bf=EH;
break;
case RH:(*T)->bf=EH;
L->bf=LH;
break;
}
Lr->bf=EH;
L_Rotate(&(*T)->lchild); //对T的左子树作左旋平衡处理
R_Rotate(T); //对T作右旋平衡处理
}
}首先定义了三个常数变量,分别代表1、0、-1
1. 函数被调用,传入一个需要调整平衡性的子树T。由于LeftBalance函数被调用时,其实是已经确认当前子树是不平衡状态,且左子树的高度大于右子树的高度。换句话说,此时T的根结点应该是平衡因子BF的值大于1的数
2. 第4行,我们将T的左孩子赋值给L
3. 第5~27行是分支判断
4. 当L的平衡因子为LH,即为1时,表明它与根结点的BF值符号相同,因此,第8行,将它们的BF值都改为0,并且第9行,进行右旋操作。
5. 当L的平衡因子为RH,即-1时,表明它与根结点的BF值符号相反,此时需要做双旋处理。针对L的右孩子Lr的BF作判断,修改根结点T和L的BF值。第24行当前Lr的BF改为0
6. 对根结点的左子树进行左旋
7. 对根结点进行右旋,完成平衡操作。
同样的,右平衡旋转处理的函数代码非常类似,略()
接下来我们来看看主函数
/*
若在平衡二叉排序树T中不存在和e相同的关键字,则插入一个数据元素e的新结点并返回1,否则返回0。若因插入而使二叉排序对失去平衡,则作平衡旋转处理,布尔变量taller反应T长高与否
*/
Status InsertAVL(BiTree *T,int e,Status *taller)
{
if(!*T)
{//插入新结点,树”长高”,置taller为TRUE
*T=(BiTree)malloc(sizeof(BiTNode));
(*T)->data=e;
(*T)->lchild = (*T)->rchild=NULL;
(*T)->bf=EH;
*taller = TRUE;
}else{
if(e==(*T)->data){//树中已存在e有相同关键字的结点则不再插入
*taller=FALSE;
return FALSE;
}
if(e<(*T)->data){
//继续在左子树中搜索
if(!InsertAVL(&(*T)->lchild,e,taller))
return FALSE;
if(*taller) //已插入到T的左子树中
{
switch((*T)->bf)
{
case LH:
LeftBalance(T);
*taller = FALSE;
break;
case EH:
(*T)->bf=LH
*taller=TRUE;
break;
case RH:
(*T)->bf=EH;
*taller = FALSE;
break;
}
}
}else{ //应继续在右子树中进行搜索
if(!InsertAVL(&(*T)->rchild,e,taller))
returnFALSE;
if(*taller){ //插入…长高
switch((*T)->bf)
{
case LH:
(*T)->bf=EH
*taller = FALSE;
break;
case EH:
(*T)->bf=RH
*taller=TRUE;
break;
case RH:
RightBalance(T);
*taller = FALSE;
break;
}
}
}
}
return TRUE;
}