一、Deep Dream
通过调整某一个filter训练得到的值,让filter中的参数绝对值变得更大,那么该filter代表的特征将会强化,机器将会把某些特征训练成它看到过的其他特征。


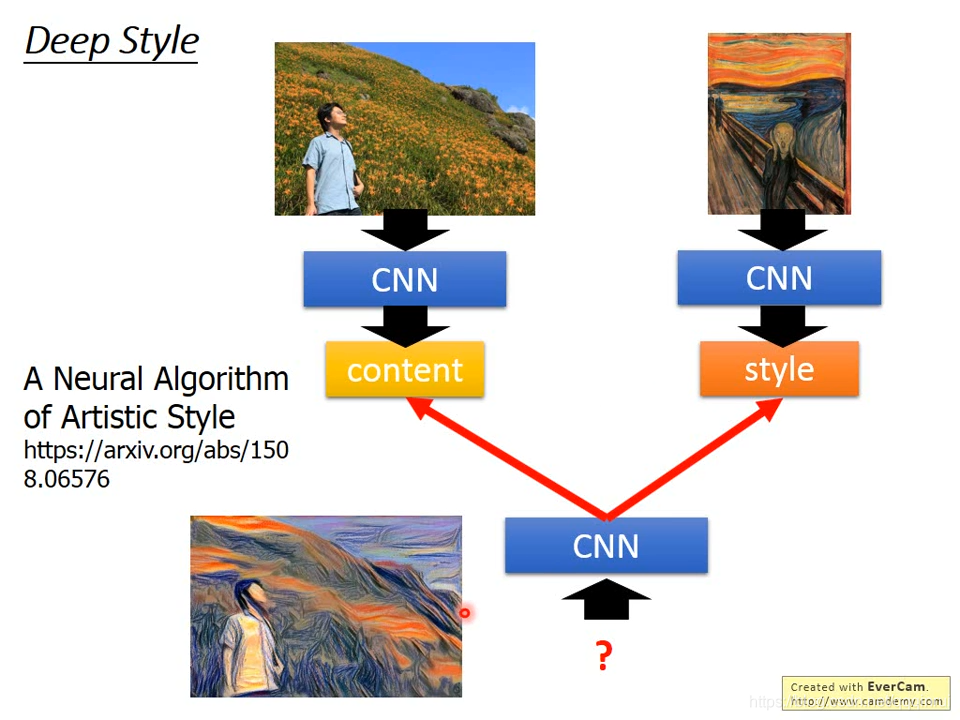
二、Deep Style
算法链接:https://arxiv.org/abs/150/8.06576
训练过程中,运用第一张图片的Content和第二张图片的style。content表示的就是CNN的filter的输出(学到的东西);style表示的是CNN输出值之间的correlation。一张新的图片,maximizing他的content像第一张图,maximizing他的style像第二张图,得出风格转换的图。
三、Playing Go
AlphaGo将围棋额棋盘变成一个19*19的图片,黑色棋子代表1,白色-1,无子0。转换过程很简单:将棋盘分割成19*19的区域,然后计算每个区域中黑白像素的占比即可判断每个区域的实际棋子。那么,一个棋盘就可以用19*19的图片表示出来。
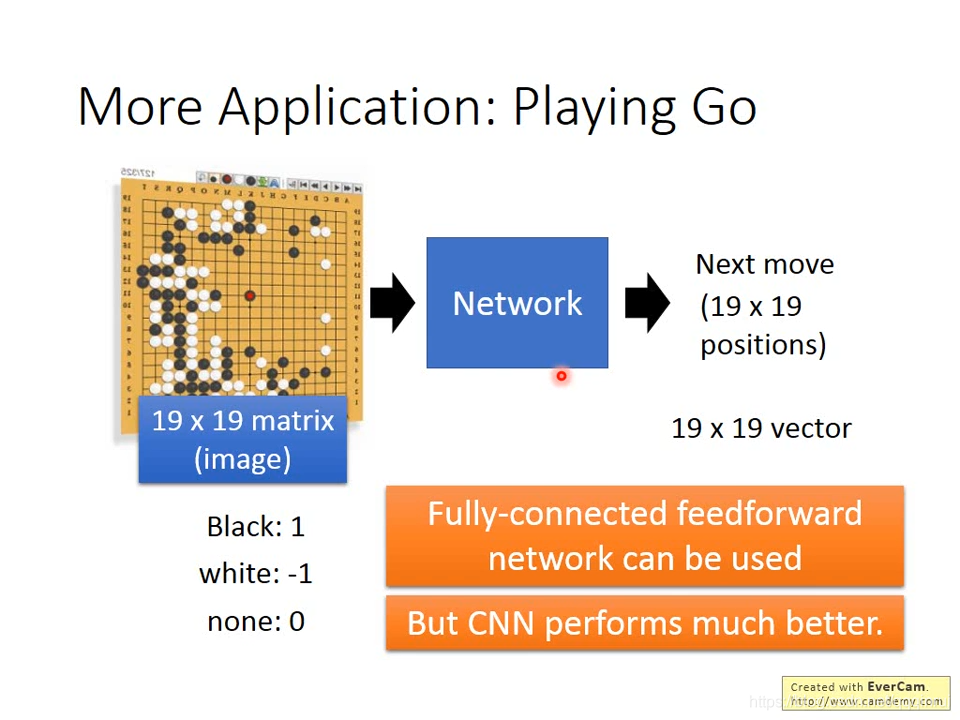
围棋具有适合CNN处理的理由:1、通常5*5的范围就可以判断出一个区域的胜负;2、同一种走法可能出现在任何区域。

AlphaGo并没有使用“池化层”,因为下采样会改变图像特性。

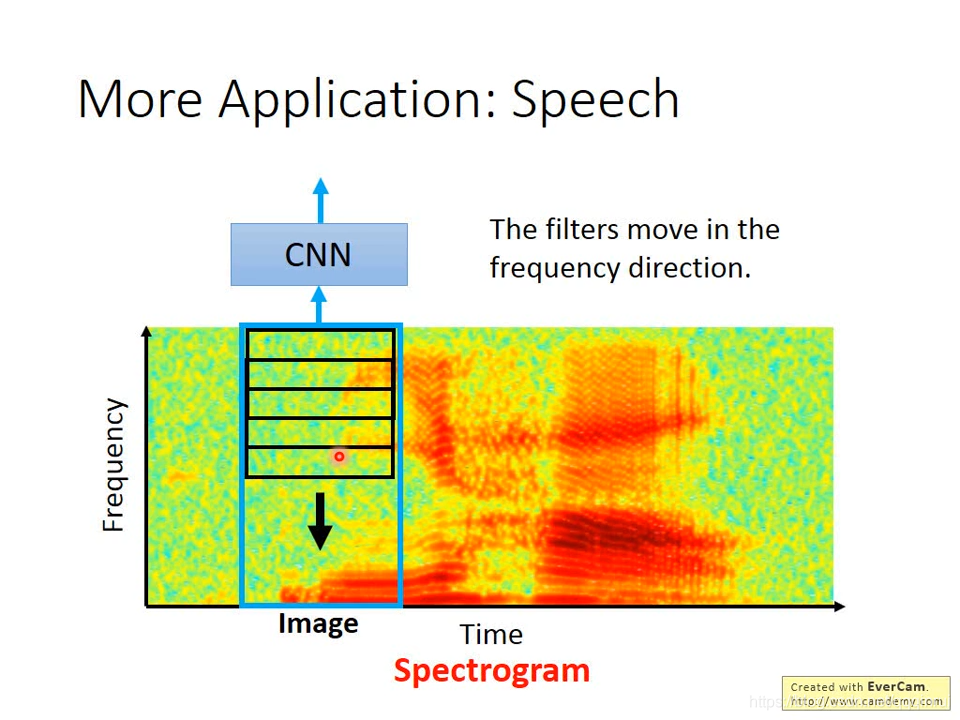
4、Speech
语音信号识别时,CNN的滑窗沿着频率维进行,沿着时间维可能没有太大意义,因为一般语音识别系统还会接LSTM等时间模型。对于雷达运动识别的信号,个人感觉还是需要在时间维移动,反映出频率随时间的变化。
5、Text
每一个单词用一个列向量表示,然后将一个句子组成一个矩阵,然后当作图像去CNN处理。CNN的卷积核的高度是列向量的维数。
