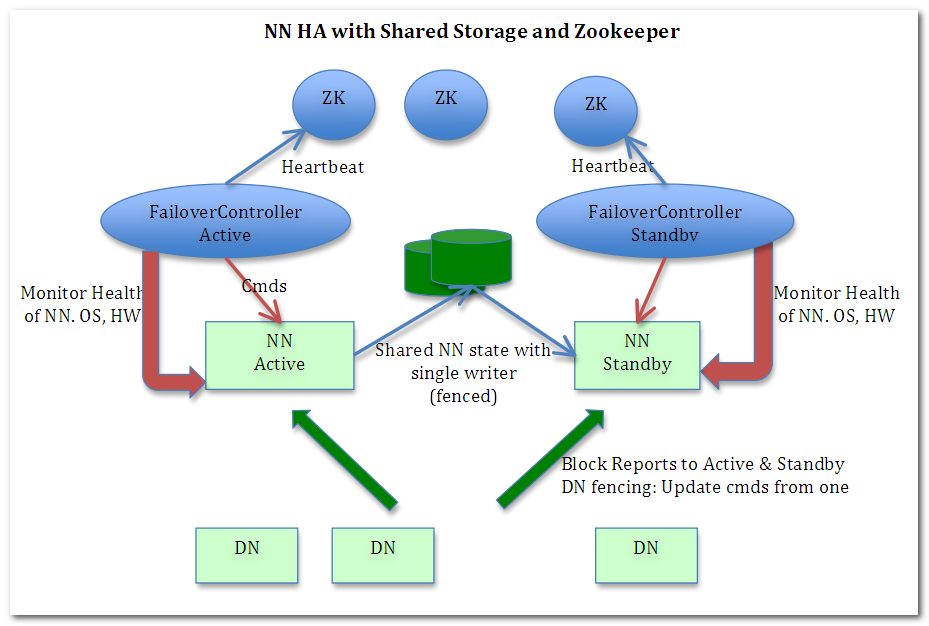
完全分布式功能:主要是使NN互为热备,解决NameNode单点故障问题
– hadoop2.x中的standby NN只有一个,在hadoop3.x中可以有多个。
-
信息共享问题
通过JournalNode集群实现元数据共享,活跃状态(Active)的NN通过元数据的更新发送给大部分的JN机器,只要保证JN集群大部分机器存活,StandBy状态的NameNode就可以获得数据。
多个NameNode之间共享数据,可以通过Network File System或者Quorum Journal Node。前者是通过Linux共享的文件系统,属于操作系统的配置;后者是Hadoop自身的东西,属于软件的配置。
Journal Node集群信息共享实现机制:
Journal Node是在Yarn中新加的,Journal Node的作用是存放EditLog的,在MR1中editlog是和fsimage存放在一起的然后SecondaryNameNode做定期合并,Yarn在这上面就不用SecondaryNameNode了。
Active Namenode往JN集群里写editlog数据,active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到JN中。
Standby NameNode定期的检查,从JN把最近的Edit文件读过来,然后把Edits文件和Fsimage文件合并成一个新的Fsimage,合并完成之后会通知Active Namenode获取这个新Fsimage。Active Namenode被动通过RPC获得这个新的Fsimage文件之后,替换原来旧的Fsimage文件。
另,在配置中定义Journal Node节点的个数是可多个的(一般是奇数个,一般是3),管理者是QJM,全称QuorumJournalManager。(这个关于JN集群高可用的事,以后研究好再说)
扫描二维码关注公众号,回复: 4739643 查看本文章
-
老大选举问题
两个NameNode通过Zookeeper实现选举,这个过程通过FailOverController来具体执行。
FailOverController,联系NN和ZK的进程:
这里采用的是zk的临时节点机制,当active namenode挂掉后,监控到节点消失,就可以把standby namenode切换成active状态,成为active namenode。
注意,可以人工切换和自动切换。人工切换是通过执行HA管理的命令来改变namenode的状态,从standby到active,或者从active到standby。自动切换则在active namenode挂掉的时候,standby namenode自动切换成active状态,取代原来的active namenode成为新的active namenode,HDFS继续正常工作。
集群安装配置原则:
- 两个NameNode一般单独安装
- FailOverConteoller的进程必须和NameNode装在一起
- ResourceManage 一般单独安装或跟NameNode安装到一起
- DataNode单独安装
- NodeManager一般和DataNode装在一起
- JN单独安装,或跟DataNode装在一起
- Zookeeper通常是单独的集群,也可以配在hadoop集群中
不同机器数量的布局规划
六台机器情况下的集群分布
| NameNode | DataNode | JN | FailOverController | ResourceManage | NodeManager | Zookeeper | |
|---|---|---|---|---|---|---|---|
| N 01 | ✔ | ✔ | ✔ | ||||
| S 02 | ✔ | ✔ | |||||
| 03 | ✔ | ✔ | |||||
| 04 | ✔ | ✔ | ✔ | ||||
| 05 | ✔ | ✔ | ✔ | ||||
| 06 | ✔ | ✔ | ✔ |
五台机器情况下的集群分布
| NameNode | DataNode | JN | FailOverController | ResourceManage | NodeManager | Zookeeper | |
|---|---|---|---|---|---|---|---|
| N 01 | ✔ | ✔ | ✔ | ✔ | |||
| S 02 | ✔ | ✔ | ✔ | ||||
| 03 | ✔ | ✔ | ✔ | ✔ | |||
| 04 | ✔ | ✔ | ✔ | ✔ | |||
| 05 | ✔ | ✔ | ✔ | ✔ |
三台机器的集群分布
| NameNode | DataNode | JN | FailOverController | ResourceManage | NodeManager | Zookeeper | |
|---|---|---|---|---|---|---|---|
| N 01 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| N 02 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| 03 | ✔ | ✔ | ✔ | ✔ |
完全分布式安装配置
---------------------------------------------以三台机为例
前期准备
固化IP
关闭每台机器的防火墙
配置主机名,配置host文件,配置ssh免密
安装JDK,配置环境
调整系统时间
软件安装
安装Zookeeper,配置环境变量
1 设置zoo.conf文件
[root@student01 conf]# pwd
/usr/local/src/zookeeper/zookeeper-3.4.7/conf
[root@student01 conf]# vim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# 存储zk快照的文件夹,包括zk的选举文件myid后期也要放里面
dataDir=/usr/local/src/zookeeper/zookeeper-3.4.7/tmp
# zk端口号
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
# server关键字,后面数字是选举id,要求可以比较大小,2888为原子广播端口,3888为选举端口
server.1=192.168.161.121:2888:3888
server.2=192.168.161.122:2888:3888
server.3=192.168.161.123:2888:3888
2 建立tmp文件夹,在里面建立myid文件,里面写选举id
[root@student01 tmp]# cat myid
1
3 配置环境变量
#set env
JAVA_HOME=/usr/local/src/java/jdk1.8.0_51
JAVA_BIN=/usr/local/src/java/jdk1.8.0_51/bin
ZK_HOME=/usr/local/src/zookeeper/zookeeper-3.4.7 #配置zk主文件夹
PATH=$JAVA_HOME/bin:$PATH:$ZK_HOME/bin #方便在主程序调用zk
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH ZK_HOME #方便在子程序调用zk
4 采用SCP复制到其他两台机器上
[root@student01 src]# scp -r zookeeper root@student02:/usr/local/src
[root@student01 src]# scp -r zookeeper root@student03:/usr/local/src
后面记得修改其他两台机的myid文件内容为各自选举编号。
安装Hadoop并配置
位置:主文件夹/etc/hadoop
[root@student01 hadoop]# pwd
/usr/local/src/hadoopX/hadoop-2.7.1/etc/hadoop
[root@student01 hadoop]# vim hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/local/src/java/jdk1.8.0_51 #/etc/profile 中的配置不生效,需重新配置
2 配置core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--指定hadoop数据临时存放目录-->
<property>
<!--在hadoop安装目录下 创建一个tmp目录-->
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoopX/hadoop-2.7.1/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>student01:2181,student02:2181,student03:2181</value>
</property>
</configuration>
3 hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>student01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>student01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>student02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>student02:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://student01:8485;student02:8485;student03:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/src/hadoopX/hadoop-2.7.1/tmp/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!--NameNode数据存放位置-->
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/src/hadoopX/hadoop-2.7.1/tmp/hdfs/namenode</value>
</property>
<property>
<!--DataNode数据存放位置-->
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/src/hadoopX/hadoop-2.7.1/tmp/hdfs/datanode</value>
</property>
<!--HDFS副本数量-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
在tmp文件夹下,新建hdfs和journal文件夹,hdfs文件夹下新建namenode和datanode文件夹
4 配置 mapred-site.xml
[root@student01 hadoop]# cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5 配置yarn-site.xml
注意!我要埋BUG了!!!不要跟着配!!
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<!-- 单一的resourcemanager,会是高可用吗?挂掉一个,集群就烂掉! -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>student01</value>
</property>
6 配置slaves
[root@student01 hadoop]# vim slaves
[root@student01 hadoop]# cat slaves
student01
student02
student03
以上配置,并不能完全启动High Available,缺少了yarn的HA配置,也就是之前讲的yarn-site.xml,需要实现ResourceManage的高可用
NameNode DataNode JN FailOverController ResourceManage NodeManager Zookeeper N 01 ✔ ✔ ✔ ✔ ✔ ✔ ✔ N 02 ✔ ✔ ✔ ✔ ✔(缺了这一个) ✔ ✔ 03 ✔ ✔ ✔ ✔
5.X 重新配置yarn-site.xml,实现yarn-site.xml高可用
<configuration>
<!-- 配置可以在 nodemanager 上运行 mapreduce 程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 激活 resourcemanager 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 resourcemanager 的集群 id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
<!-- 定义 RM 的节点,2个RM实现高可用-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定 RM1 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>student01</value>
</property>
<!-- 指定 RM2 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>student02</value>
</property>
<!-- 激活 resourcemanager 自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置 resourcemanager 状态信息存储方式,有 MemStore 和 ZKStore-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置为 zookeeper 存储时,指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>student01:2181,student02:2181,student03:2181</value>
</property>
</configuration>
7 拷贝文件
[root@student01 src]# scp -r hadoopX root@student02:/usr/local/src
[root@student01 src]# scp -r hadoopX root@student03:/usr/local/src
配置环境变量
1 设置环境变量
[root@student01 hadoop]# vim /etc/profile
JAVA_HOME=/usr/local/src/java/jdk1.8.0_51
JAVA_BIN=/usr/local/src/java/jdk1.8.0_51/bin
HADOOP_HOME=/usr/local/src/hadoopX/hadoop-2.7.1
ZK_HOME=/usr/local/src/zookeeper/zookeeper-3.4.7
PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$ZK_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH HADOOP_HOME ZK_HOME
2 分发环境变量
[root@student01 etc]# scp profile root@student02:/etc
[root@student01 etc]# scp profile root@student03:/etc
3 生效吧!变量!(每一个机器都执行一下并检验)
[root@student01 etc]# source /etc/profile
[root@student01 etc]# echo $HADOOP_HOME
/usr/local/src/hadoopX/hadoop-2.7.1
[root@student01 etc]# hadoop version
Hadoop 2.7.1
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a
Compiled by jenkins on 2015-06-29T06:04Z
Compiled with protoc 2.5.0
From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a
This command was run using /usr/local/src/hadoopX/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar
HA集群启动
1 启动zk
[root@student01 etc]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/zookeeper-3.4.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
2 启动JN集群
在Active NameNode节点(student01节点)运行JN
[root@student01 ~]# hadoop-daemons.sh start journalnode
student02: starting journalnode, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/hadoop-root-journalnode-student02.out
student03: starting journalnode, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/hadoop-root-journalnode-student03.out
student01: starting journalnode, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/hadoop-root-journalnode-student01.out
3 格式化zk中hadoop相关znode信息(仅在第一次启动时启用)
在Active NameNode节点(student01节点)运行
[root@student01 ~]# hdfs zkfc -formatZK
......
18/11/19 16:00:07 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns in ZK.
......
这个时候使用jps查看进程,三台机子都会有这个:
[root@student01 ~]# jps
4966 Jps
4854 JournalNode
4761 QuorumPeerMain
同时,可以检查zk客户端内的信息,发现ns在了
[zk: localhost:2181(CONNECTED) 1] ls /
[park01, zookeeper, park03, hadoop-ha]
[zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha
[ns]
4 格式化NameNode(仅在第一次启动时使用)
在Active NameNode节点(student01节点)运行
[root@student01 ~]# hdfs namenode -format
18/11/19 16:05:14 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
............
18/11/19 16:05:19 INFO common.Storage: Storage directory /usr/local/src/hadoopX/hadoop-2.7.1/tmp/hdfs/namenode has been successfully formatted.
...........
5 启动NameNode
在Active NameNode节点(student01节点)运行
[root@student01 ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/hadoop-root-namenode-student01.out
[root@student01 ~]# jps
5073 NameNode
4854 JournalNode
4761 QuorumPeerMain
5146 Jps
在Standby NameNode节点(student02节点)运行,定义NN为standby namenode节点(做一次就好)
[root@student02 hadoop]# hdfs namenode -bootstrapStandby
...
18/11/19 00:12:59 INFO common.Storage: Storage directory /usr/local/src/hadoopX/hadoop-2.7.1/tmp/hdfs/namenode has been successfully formatted.
...
启动Standby NameNode节点上的NN
[root@student02 hadoop]# hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/hadoop-root-namenode-student02.out
[root@student02 hadoop]# jps
4356 Jps
3877 JournalNode
3816 QuorumPeerMain
4282 NameNode
6 启动DataNode
在Active NameNode节点(student01节点)运行
[root@student01 ~]# hadoop-daemons.sh start datanode
student03: starting datanode, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/hadoop-root-datanode-student03.out
student01: starting datanode, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/hadoop-root-datanode-student01.out
student02: starting datanode, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/hadoop-root-datanode-student02.out
此时,student01 student02在jps指令下会有如下显示
[root@student01 ~]# jps
5073 NameNode
4854 JournalNode
5608 DataNode
4761 QuorumPeerMain
5724 Jps
5390 ZooKeeperMain
student03会有如下显示
[root@student03 hadoop]# jps
3810 QuorumPeerMain
3865 JournalNode
4140 DataNode
4222 Jps
7 启动zkfc
在每个NameNode节点上运行(student01 student02)
[root@student01 ~]# hadoop-daemon.sh start zkfc
starting zkfc, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/hadoop-root-zkfc-student01.out
[root@student01 ~]# jps
5824 DFSZKFailoverController
5073 NameNode
5890 Jps
4854 JournalNode
5608 DataNode
4761 QuorumPeerMain
8 启动yarn
-1 非HA模式(也就是使用第5步配置)
在ResourceManager节点(student01)启动yarn
start-yarn.sh
-2 HA模式(也就是使用第5.X步配置)
在Active ResourceManager(student01)上启动
start-yarn.sh
[root@student01 ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/yarn-root-resourcemanager-student01.out
student03: starting nodemanager, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/yarn-root-nodemanager-student03.out
student01: starting nodemanager, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/yarn-root-nodemanager-student01.out
student02: starting nodemanager, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/yarn-root-nodemanager-student02.out
[root@student01 ~]# jps
5824 DFSZKFailoverController
5073 NameNode
6133 Jps
4854 JournalNode
6088 NodeManager
5608 DataNode
4761 QuorumPeerMain
5995 ResourceManager
在BackUp ResourceManager(student02)上启动
yarn-daemon.sh start resourcemanager
[root@student02 hadoop]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /usr/local/src/hadoopX/hadoop-2.7.1/logs/yarn-root-resourcemanager-student02.out
[root@student02 hadoop]# jps
4403 DataNode
4933 ResourceManager
3877 JournalNode
4792 NodeManager
3816 QuorumPeerMain
4282 NameNode
4603 DFSZKFailoverController
5182 Jps




进程数检查
| 进程名 | NN 01 | NN 02 | 03 |
|---|---|---|---|
| Jps | ✔ | ✔ | ✔ |
| NameNode | ✔ | ✔ | |
| ResourceManager | ✔ | ✔ | |
| DataNode | ✔ | ✔ | ✔ |
| NodeManager | ✔ | ✔ | ✔ |
| JournalNode | ✔ | ✔ | ✔ |
| QuorumPeerMain | ✔ | ✔ | ✔ |
| DFSZKFailoverController | ✔ | ✔ |
原设置比对:
| NameNode | DataNode | JN | FailOverController | ResourceManage | NodeManager | Zookeeper | |
|---|---|---|---|---|---|---|---|
| N 01 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| N 02 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| 03 | ✔ | ✔ | ✔ | ✔ |
进程作用剖析
某公司笔试题:写出Hadoop集群启动时都有哪些进程启动,分别起什么作用?
-
NameNode
hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有 MetaData。NN在完全分布式中支持Active NameNode,和 Standby NameNode。
-
DataNode
文件系统的工作节点,根据需要操作(增删)并检索数据块(受客户端或NameNode调度),并且定期向NameNode发送它们所存储的块的列表。
-
ResourceManager
是YARN的一个组件,全局的资源管理器,负责整个系统的资源管理和分配。它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)。
-
NodeManager
是YARN的一个组件,NM是每个节点上的资源和任务管理器,一方面回想RM汇报本节点上资源使用情况和各个Container的运行状况;另一方面,它接收并处理来自ApplicationManager的Container启动/停止等请求。
-
QuorumPeerMain
zookeeper集群的启动入口类,是用来加载配置启动QuorumPeer线程的,进而运行已经定义好的zk集群。
-
JournalNode
实现Active NameNode和Standby NameNode之间的信息共享。
Active Namenode往JN集群里写editlog数据,active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到JN中。
Standby NameNode定期的检查,从JN把最近的Edit文件读过来,然后把Edits文件和Fsimage文件合并成一个新的Fsimage,合并完成之后会通知Active Namenode获取这个新Fsimage。Active Namenode被动通过RPC获得这个新的Fsimage文件之后,替换原来旧的Fsimage文件。
-
DFSZKFailoverController
DFSZKFailoverController是Hadoop-2.7.x中HDFS NameNode HA实现的中心组件,它负责整体的故障转移控制等。细分职责如下:
1 健康监测
zkfc会周期性的向它监控的NameNode发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态
2 会话管理
如果NameNode是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NameNode挂掉时, 这个znode将会被删除,然后备用的NameNode,将会得到这把锁,升级为主NameNode,同时标记状态为Active,当宕机的NameNode,重新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠
–需要注意,Hadoop2.0支持最多配置2个NameNode,而3.0则支持多个NameNode,即支持一个集群中,一个active、多个standby namenode部署方式。而2.0已经支持了多RM的特性。
3 master选举
通过在zookeeper中维持临时znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态。
HA 面试题试炼
简述启动与停止Hadoop集群的方法(建基在已格式化之上)
Yarn在集群中起到什么作用?zookeeper在集群中起到什么作用?
在HadoopHA集群中Zookeeper主要作用,以及启动和查看状态的命令?
HDFS HA的基本结构是怎样的?如何保证元数据的同步?
假设有一个Hadoop集群,其中有一台NameNode,一台SecondaryNameNode,3台DataNode,请描述当客户端准备写入
一个500M大小的文件到HDFS,从客户端发起请求到DataNode完成所有写入工作的整个过程。