一、迭代器
对于Python 列表的 for 循环,他的内部原理:查看下一个元素是否存在,如果存在,则取出,如果不存在,则报异常 StopIteration。(python内部对异常已处理)
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件
特点:
- 访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容
- 不能随机访问集合中的某个值 ,只能从头到尾依次访问
- 访问到一半时不能往回退
- 便于循环比较大的数据集合,节省内存
class listiterator(object)
| Methods defined here:
|
| __getattribute__(...)
| x.__getattribute__('name') <==> x.name
|
| __iter__(...)
| x.__iter__() <==> iter(x)
|
| __length_hint__(...)
| Private method returning an estimate of len(list(it)).
|
| next(...)
| x.next() -> the next value, or raise StopIteration
>>> a = iter([1,2,3,4,5])
>>> a
<list_iterator object at 0x101402630>
>>> a.__next__()
1
>>> a.__next__()
2
>>> a.__next__()
3
>>> a.__next__()
4
>>> a.__next__()
5
>>> a.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
二、生成器
一个函数调用时返回一个迭代器,那这个函数就叫做生成器(generator);如果函数中包含yield语法,那这个函数就会变成生成器;
range不是生成器 和 xrange 是生成器
readlines不是生成器 和 xreadlines 是生成器
| 1 2 3
扫描二维码关注公众号,回复:
4745904 查看本文章

4 |
>>> print range(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> print xrange(10)
xrange(10)
|
生成器内部基于yield创建,即:对于生成器只有使用时才创建,从而不避免内存浪费
| 1 2 3 4 5 6 7 8 9 10 11 |
练习:<br>有如下列表:
[13, 22, 6, 99, 11]
请按照一下规则计算:
13 和 22 比较,将大的值放在右侧,即:[13, 22, 6, 99, 11]
22 和 6 比较,将大的值放在右侧,即:[13, 6, 22, 99, 11]
22 和 99 比较,将大的值放在右侧,即:[13, 6, 22, 99, 11]
99 和 42 比较,将大的值放在右侧,即:[13, 6, 22, 11, 99,]
13 和 6 比较,将大的值放在右侧,即:[6, 13, 22, 11, 99,]
...
|


li = [13, 22, 6, 99, 11]
for m in range(len(li)-1):
for n in range(m+1, len(li)):
if li[m]> li[n]:
temp = li[n]
li[n] = li[m]
li[m] = temp
print li
生成器表达式
1 生成器表达式定义
生成器表达式并不真正的创建数字列表,而是返回一个生成器对象,此对象在每次计算出一个条目后,把这个条目"产生"(yield)出来。生成器表达式使用了"惰性计算"或称作"延时求值"的机制。生成器表达式可以用来处理大数据文件。
序列过长,并且每次只需要获取一个元素时,应该考虑生成器表达式而不是列表解析。
生成器表达式产生的是一个生成器对象,实质就是迭代器。
2 生成器表达式语法
语法:
(expression for iter_val in iterable)
(expression for iter_val in iterable if cond_expr)
例:
| 1 2 3 4 |
g=("egg%s"%i for i in range(100))
print(g)
print(next(g))
print(next(g))
|
输出结果:
| 1 2 3 |
<generator object <genexpr> at 0x0000007E9A403D00>
egg0
egg1
|
可以处理大数据文件:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
f=open("a.txt")
l=[]
for line in f:
line = line.strip()
l.append(line)
print(l)
f.seek(0)
l1=[line.strip() for line in f]
print(l1)
f.seek(0)
g=(line.strip() for line in f)
print(g)
print(next(g))
|
输出结果:
| 1 2 3 4 |
['wen', 'yan', 'jie']
['wen', 'yan', 'jie']
<generator object <genexpr> at 0x0000000A2B173D00>
wen
|
4、List函数可以处理迭代器和可迭代对象
List后面可以跟可迭代对象,和for的实质是一样的。 List函数将可迭代对象使用iter方法,变成迭代器,然后使用迭代器的next方法遍历可迭代器的值,并存储为列表类型,在最后报错的时候结束。
文件a.txt的内容是
编程代码:
| 1 2 3 4 |
f=open('a.txt')
g=(line.strip() for line in f)
l=list(g)
print(l)
|
输出结果:
5、sum函数可以处理迭代器和可迭代对象
Sum后面可以跟可迭代对象,和sum的实质是一样的。 Sum函数将可迭代对象使用iter方法,变成迭代器,然后使用迭代器的next方法遍历可迭代器的值,并,在最后报错的时候结束。
| 1 2 3 4 5 |
g=(i for i in range(10))
print(g)
print(sum(g))
print(sum(range(10)))
print(sum([0,1,2,3,4,5,6,7,8,9]))
|
输出结果:
| 1 2 3 4 |
<generator object <genexpr> at 0x0000008ED3FA3D00>
45
45
45
|
Sum中也可以跟可迭代的对象,跟for,list的工作实质类型
6、声明式编程
一种编程方式,将需要很多语句的代码写成声明变量的形式
| 1 |
g=(line.strip() for line in f)
|
7、 生成器表达式举例
在文件a.txt中的内容:
apple 10 3
tesla 1000000 1
mac 3000 2
lenovo 30000 3
chicken 10 3
1 计算购买总共的花费:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
以前的做法:
money_l=[]
with open('a.txt') as f:
for line in f:
goods=line.split()
res=float(goods[-1])*float(goods[-2])
money_l.append(res)
print(money_l)
使用生成器表达式的做法
f=open('a.txt')
g=(float(line.split()[-1])*float(line.split()[-2]) for line in f)
for i in g:
print(i)
f=open('a.txt')
g=(float(line.split()[-1])*float(line.split()[-2]) for line in f)
print(sum(g))
一句话做法:不要这样做,python代码不是要写少,而是要写好,能看懂,且逻辑好
with open('a.txt') as f:
print(sum(float(line.split()[-1])*float(line.split()[-2]) for line in f))
|
2 将a.txt文件中的每行内容转化为字典类型并且存储到列表
以前做法:
| 1 2 3 4 5 6 7 8 9 10 |
res=[]
with open('a.txt') as f:
for line in f:
l=line.split()
d={}
d["name"]=l[0]
d["price"]=l[1]
d["count"]=l[2]
res.append(d)
print(res)
|
输出结果:
| 1 |
[{'price': '10', 'name': 'apple', 'count': '3'}, {'price': '1000000', 'name': 'tesla', 'count': '1'}, {'price': '3000', 'name': 'mac', 'count': '2'}, <br>{'price': '30000', 'name': 'lenovo', 'count': '3'}, {'price': '10', 'name': 'chicken', 'count': '3'}]
|
生成器表达式做法
有报错的:
| 1 2 3 4 5 6 7 |
with open('a.txt') as f:
res=(line.split() for line in f)
print(res)
dic_g=({'name':i[0],'price':i[1],'count':i[2]} for i in res)
print(dic_g)
print(dic_g)
print(next(dic_g)) #原因在于dic_g生成器迭代需要res生成器迭代,res生成器迭代需要f迭代器迭代,f是打开文件的句柄,一关闭,res生成器和dic_g生成器都不能使用
|
输出结果:
| 1 2 3 4 |
<generator object <genexpr> at 0x00000044A0DA3D00>
<generator object <genexpr> at 0x00000044A0DA3E08>
<generator object <genexpr> at 0x00000044A0DA3E08>
ValueError: I/O operation on closed file. #报错
|
正确生成器做法:
| 1 2 3 4 5 6 7 |
with open('a.txt') as f:
res=(line.split() for line in f)
print(res)
dic_g=({'name':i[0],'price':i[1],'count':i[2]} for i in res)
print(dic_g)
apple_dic=next(dic_g)
print(apple_dic["count"])
|
输出结果:
| 1 2 3 |
<generator object <genexpr> at 0x00000081D5243D00>
<generator object <genexpr> at 0x00000081D5243E08>
3
|
3 将a.txt文件中的每行内容转化为字典类型并且取出单价大于10000的商品存储到列表,
生成器表达式调用生成器表达式
| 1 2 3 4 5 6 7 |
with open('a.txt') as f:
res=(line.split() for line in f)
print(res)
dic_g=({'name':i[0],'price':i[1],'count':i[2]} for i in res if float(i[1]) >10000)
print(dic_g)
for i in dic_g:
print(i)
|
输出结果:
| 1 2 3 4 |
<generator object <genexpr> at 0x000000DB4C633D00>
<generator object <genexpr> at 0x000000DB4C633DB0>
{'price': '1000000', 'count': '1', 'name': 'tesla'}
{'price': '30000', 'count': '3', 'name': 'lenovo'}
|
| 1 2 3 4 5 6 |
with open('a.txt') as f:
res=(line.split() for line in f)
print(res)
dic_g=({'name':i[0],'price':i[1],'count':i[2]} for i in res if float(i[1]) >10000)
print(dic_g)
print(list(dic_g))
|
输出结果:
| 1 2 3 |
<generator object <genexpr> at 0x00000099A0953D00>
<generator object <genexpr> at 0x00000099A0953DB0>
[{'price': '1000000', 'name': 'tesla', 'count': '1'}, {'price': '30000', 'name': 'lenovo', 'count': '3'}]
|
今日作业
(1)有两个列表,分别存放来老男孩报名学习linux和python课程的学生名字
linux=['钢弹','小壁虎','小虎比','alex','wupeiqi','yuanhao']
python=['dragon','钢弹','zhejiangF4','小虎比']
问题一:得出既报名linux又报名python的学生列表
| 1 2 3 4 5 6 |
linux=['钢弹', '小壁虎', '小虎比', 'alex', 'wupeiqi', 'yuanhao']
python=['dragon', '钢弹', 'zhejiangF4', '小虎比']
li=[i for i in linux for j in python if i==j]
print(li)
li=(i for i in linux for j in python if i==j)
print(list(li))
|
问题二:得出只报名linux,而没有报名python的学生列表
| 1 2 3 4 |
li=[ i for i in linux if i not in python]
print(li)
li=(i for i in linux if i not in python)
print(list(li))
|
问题三:得出只报名python,而没有报名linux的学生列表
| 1 2 3 4 |
li=[i for i in python if i not in linux]
print(li)
li=(i for i in python if i not in linux)
print(list(li))
|
(2)
shares={
'IBM':36.6,
'lenovo':27.3,
'huawei':40.3,
'oldboy':3.2,
'ocean':20.1
}
问题一:得出股票价格大于30的股票名字列表
| 1 2 |
li=( i for i,j in shares.items() if j > 30)
print(list(li))
|
问题二:求出所有股票的总价格
| 1 2 3 |
li=(float(j) for j in shares.values())
print(sum(li))
print(sum(float(j) for j in shares.values()))
|
(3)
l=[10,2,3,4,5,6,7]
得到一个新列表l1,新列表中每个元素是l中对应每个元素值的平方。过滤出l1中大于40的值,然后求和
| 1 2 3 4 5 |
l = [10, 2, 3, 4, 5, 6, 7]
l1=[i**2 for i in l]
print(l1)
l2=[i for i in l1 if i >40]
print(sum(l2))
|
1、什么是装饰器
装饰器本质上是一个python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能。
装饰器的返回值是也是一个函数对象。
装饰器经常用于有切面需求的场景,比如:插入日志,性能测试,事务处理、缓存、权限校验等场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能无关的雷同代码并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
为什么要用装饰器及开放封闭原则
函数的源代码和调用方式一般不修改,但是还需要扩展功能的话就需要在需要扩展的函数的开始使用装饰器。举例:带眼镜
装饰器是任意可调用的对象,本质就是函数
装饰器在python中使用如此方便归因于python的函数能像普通的对象一样能作为参数传递给其他函数,可以被复制给其他变量,可以作为返回值,可以被定义在另一个函数内。
2、 简单的装饰器
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
import time
def timmer(func):
def wrapper(*args,**kwargs):
start_time=time.time()
res=func(*args,**kwargs)
stop_time=time.time()
print("run time is %s "%(stop_time-start_time))
return wrapper
@timmer #等同于 index=timmer(index) , 此后index等同于 wrapper
def index():
time.sleep(1)
print("welcom ! wen")
index()
|
输出结果:
| 1 2 |
welcom ! wen
run time is 1.0001096725463867
|
函数timmer就是装饰器,它把执行真正业务方法的func包裹在函数里面,看起来像index被timmer装饰了。
在这个例子中,函数进入和退出时,被称为一个横切面(Aspet),这种编程方式被称为面向切面的编程(Aspet-Oriented Programming)
@符号是装饰器的语法糖,在定义函数的时候,避免再一次赋值操作。
3、装饰器的语法
@timmer
timmer就是一个装饰器
@timmer等同于 被装饰函数名=timmer(被装饰函数名) 被装饰器函数就是紧接@timmer下面的函数
4、无参装饰器
如果多个函数拥有不同的参数形式,怎么共用同样的装饰器?
在Python中,函数可以支持(*args, **kwargs)可变参数,所以装饰器可以通过可变参数形式来实现内嵌函数的签名。
无参装饰器,被装饰函数带参,无返回值
| 1 2 3 4 5 6 7 8 9 10 |
import time
def timmer(func):
def wrapper(*args,**kwargs):
print(func)
return wrapper
@timmer
def index():
time.sleep(1)
print("welcom ! wen")
index()
|
输出结果:
| 1 |
<function index at 0x000000D132F5AF28>
|
多个函数共用一个装饰器:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import time
def timmer(func):
def wrapper(*args,**kwargs):
start_time=time.time()
func(*args,**kwargs)
stop_time=time.time()
print("run time is: %s" %(stop_time-start_time))
return wrapper
@timmer
def home(name):
time.sleep(1)
print(" %s home"%name)
@timmer
def auth(name,password):
time.sleep(1)
print(name,password)
@timmer
def tell():
time.sleep(1)
print("------------------")
home("wenyanjie")
auth("wen","1234")
tell()
输出结果为:
wenyanjie home
run time is: 1.0002663135528564
wen 1234
run time is: 1.0000183582305908
------------------
run time is: 1.0009756088256836
|
无参装饰器,被装饰函数带参,且有返回值
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import time
def timmer(func):
def wrapper(*args,**kwargs):
start_time=time.time()
res=func(*args,**kwargs)
stop_time=time.time()
print("run time is: %s" %(stop_time-start_time))
return res
return wrapper
@timmer
def home(name):
time.sleep(1)
print(" %s home"%name)
@timmer
def auth(name,password):
time.sleep(1)
print(name,password)
@timmer
def tell():
time.sleep(1)
print("------------------")
@timmer
def my_max(x,y):
return x if x > y else y
home("wenyanjie")
auth("wen","1234")
tell()
res=my_max(1,2)
print("----->",res)
|
输出结果:
| 1 2 3 4 5 6 7 8 |
wenyanjie home
run time is: 1.0004072189331055
wen 1234
run time is: 1.0009665489196777
------------------
run time is: 1.0001206398010254
run time is: 0.0
-----> 2
|
5、有参装饰器
装饰器还有更大的灵活性,例如带参数的装饰器:在上面的装饰器调用中,比如@timmer,该装饰器唯一的参数是执行业务的函数。装饰器的语法允许我们在调用时,提供其他参数。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
def auth2(auth_type):
def auth(func):
def wrapper(*args,**kwargs):
if auth_type == "file":
name=input("username:")
password=input("password")
if name=="wen" and password =="123":
print("login successful!")
res=func(*args,**kwargs)
return res
else:
print("auth error")
elif auth_type == "sql":
print("sql no learn.....")
return wrapper
return auth
@auth2(auth_type="file")
def login(name):
print("this is %s index page"%name)
return 1
flag=login("wenyanjie")
print(flag)
|
输出结果:
| 1 2 3 4 5 |
username:wen
password123
login successful!
this is wenyanjie index page
1
|
上面例子中的auth2是允许带参数的装饰器。它实际上是对原有装饰器的一个函数封装,并返回一个装饰器。我们可以将他理解为一个含有参数的闭包。当我们使用@auth2(auth_type=”file”)调用的时候,python能够发现这一层的封装,并把参数传递到装饰器的环境中。
上面有参装饰器的执行步骤分解:
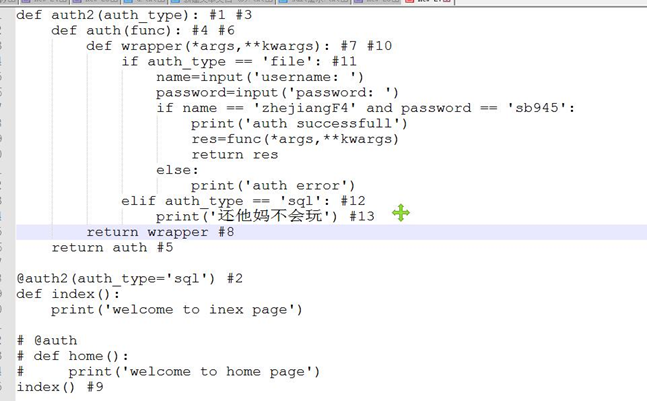
6、多个装饰器
装饰器是可以叠加的,那么这就涉及装饰器调用顺序。对于python中的“@”语法糖,装饰器的调用顺序与使用@语法糖的顺序相反。
多个无参装饰器
| 1 2 3 4 5 |
@ccc
@bbb
@aaa
def func():
pass
|
#相当与
| 1 2 3 |
func=aaa(func)
func=bbb(func)
func=ccc(func)
|
#相当与
| 1 |
func=ccc(bbb(aaa(func)))
|
有参装饰器多个
| 1 2 3 4 5 |
@ccc('c')
@bbb('b')
@aaa('c')
def func():
pass
|
#相当与
| 1 2 3 |
func=aaa('a')(func)
func=bbb('b')(func)
func=ccc('c')(func)
|
#相当与
| 1 |
func=ccc('c')(bbb('b')(aaa('a')(func)))
|
案例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import time
current_login={'name':None,'login':False}
def timmer(func):
def wrapper(*args,**kwargs):
start_time=time.time()
res=func(*args,**kwargs)
stop_time=time.time()
print("run time is %s"%(stop_time-start_time))
return res
return wrapper
def auth2(auth_type):
def auth(func):
def wrapper(*args,**kwargs):
if current_login['name'] and current_login['login']:
res=func(*args,**kwargs)
return res
if auth_type == "file":
name=input("username:")
password=input("password:")
if name=="wen" and password =="123":
print("login successful!")
current_login['name']=name
current_login['login']=password
res=func(*args,**kwargs)
return res
else:
print("auth error")
elif auth_type == "sql":
print("sql no learn.....")
return wrapper
return auth
@timmer
@auth2(auth_type="file")
def login(name):
print("this is %s index page"%name)
login("wenyanjie")
login("wenyanjie")
|
输出结果:
| 1 2 3 4 5 6 7 |
username:wen
Password:123
login successful!
this is wenyanjie index page
run time is 3.228583812713623
this is wenyanjie index page
run time is 0.0
|
7 eval方法:往文件中放有结构的数据
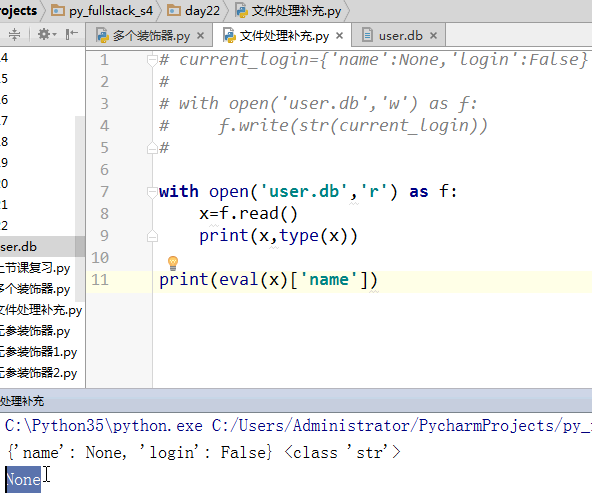
8 被装饰函数将所有注释等自己的定义都传给装饰器
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import time
from functools import wraps
def timmer(func):
@wraps(func)
def wrapper(*args,**kwargs):
"wrapper function"
print(func)
start_time=time.time()
res=func(*args,**kwargs)
stop_time=time.time()
print("run time is %s "%(stop_time-start_time))
return res
return wrapper
@timmer
def my_max(x,y):
"my_max function"
a=x if x>y else y
return a
print(help(my_max))
|
输出结果:
| 1 2 |
my_max(x, y)
my_max function
|
http://www.cnblogs.com/wupeiqi/articles/4943406.html
https://www.cnblogs.com/wupeiqi/articles/4938499.html
https://www.cnblogs.com/wupeiqi/articles/5433893.html