# 矩阵乘以数组
A = np.array([[1,2],[3,4],[5,6]])
A.shape # (3, 2)
B = np.array([7,8])
B.shape # (2,)
A.dot(B) # array([23, 53, 83])
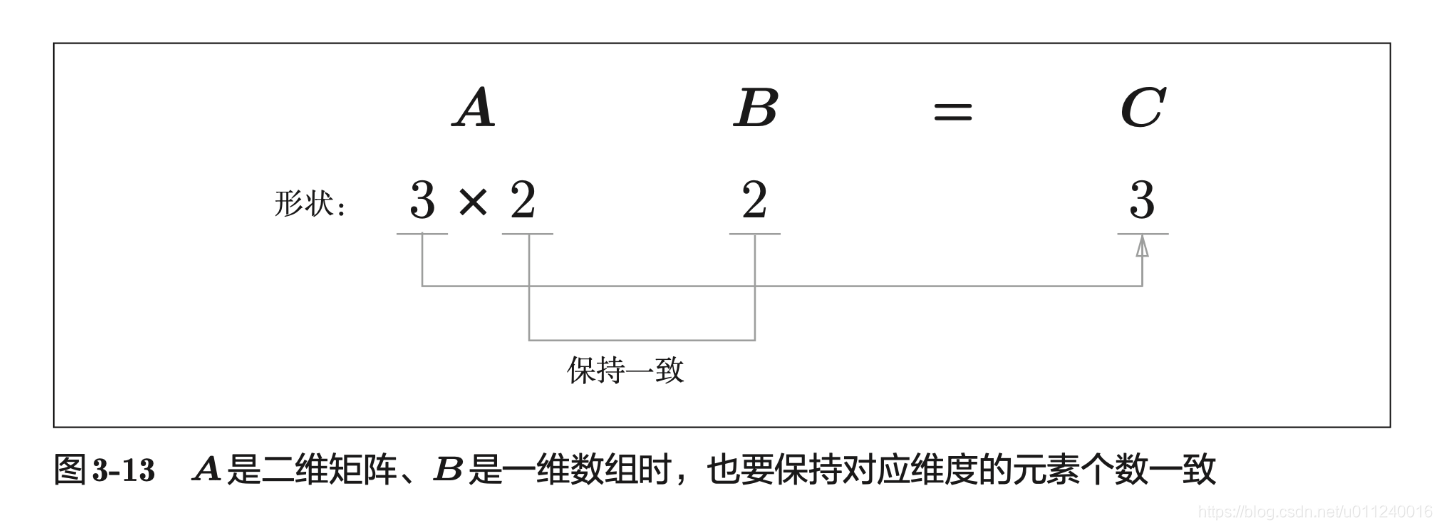
B这个一维数组会被当成列向量使用。
反过来,一维数组在前,矩阵在后的情况如下:
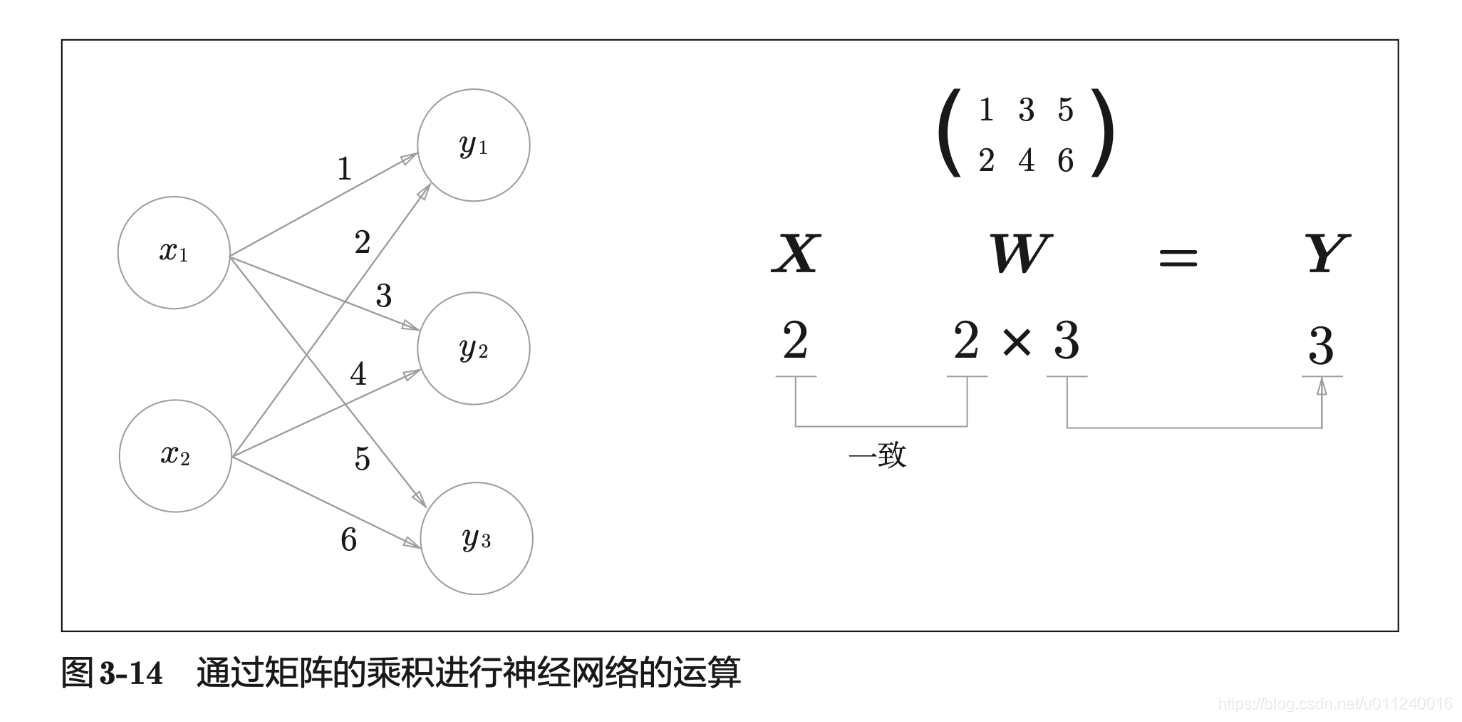
X = np.array([1,2])
X.shape # (2,)
W = np.array([[1,3,5],[2,4,6]])
W.shape #(2,3)
np.dot(X,W) # array([ 5, 11, 17])
一维数组在前,会被当做行向量使用。
同时,这里很值得注意的是,用多维数组实现神经网络时,开头输入的是一个一维数组,进行一次计算后输出结果也是一个一维数组,只不过这个一维数组的大小和神经元的数量是一样的。那么,再往后推演,道理是一样的,相当于同样的过程一直向后。
即,再加一层,也相当于一个一维数组和它进行矩阵计算。
三层神经网络的实现
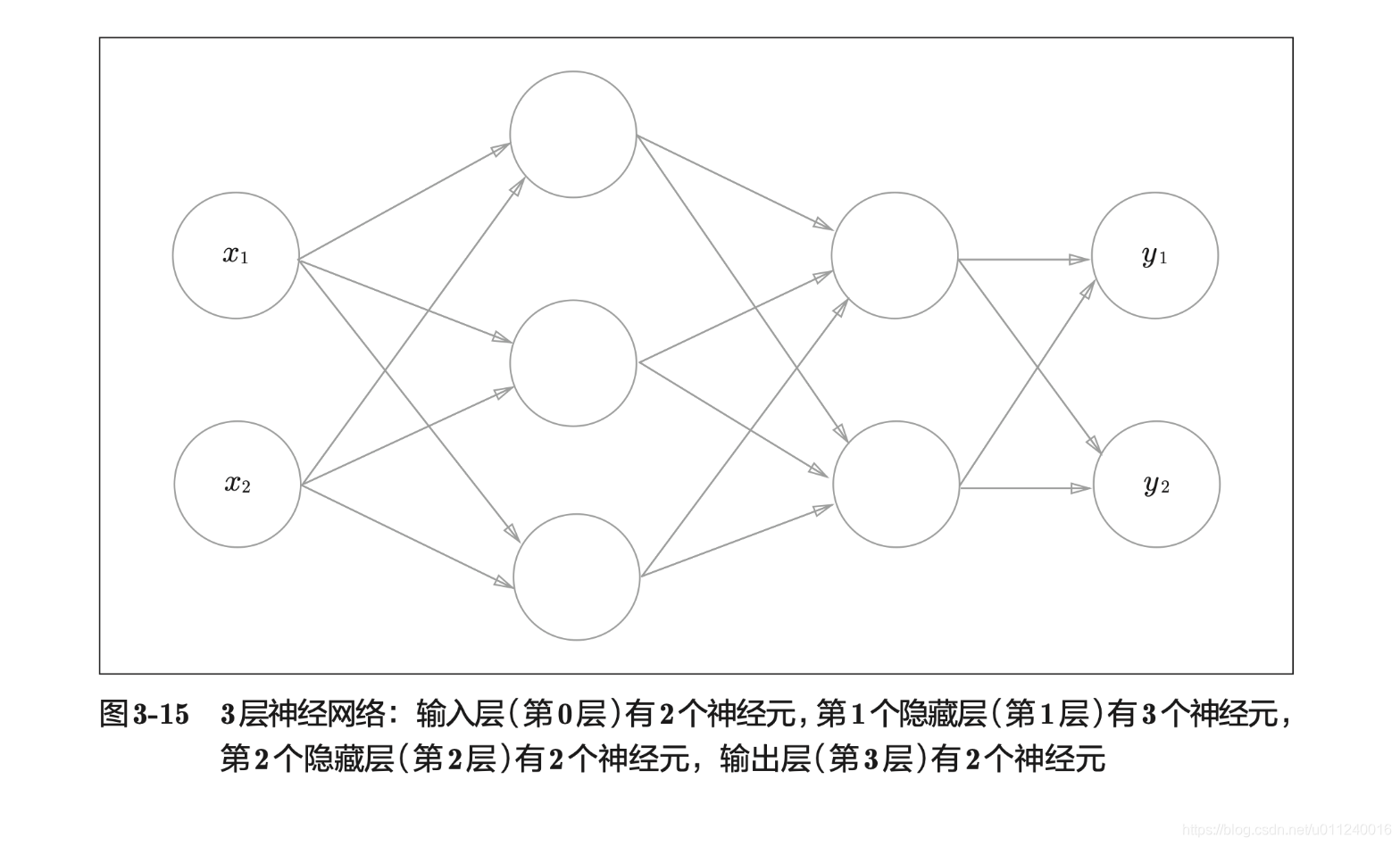
通过这个案例可以看出,神经网络真的在于细节,从最小的地方入手,理解透彻以后,再扩展,要容易理解得多。
符号的设定
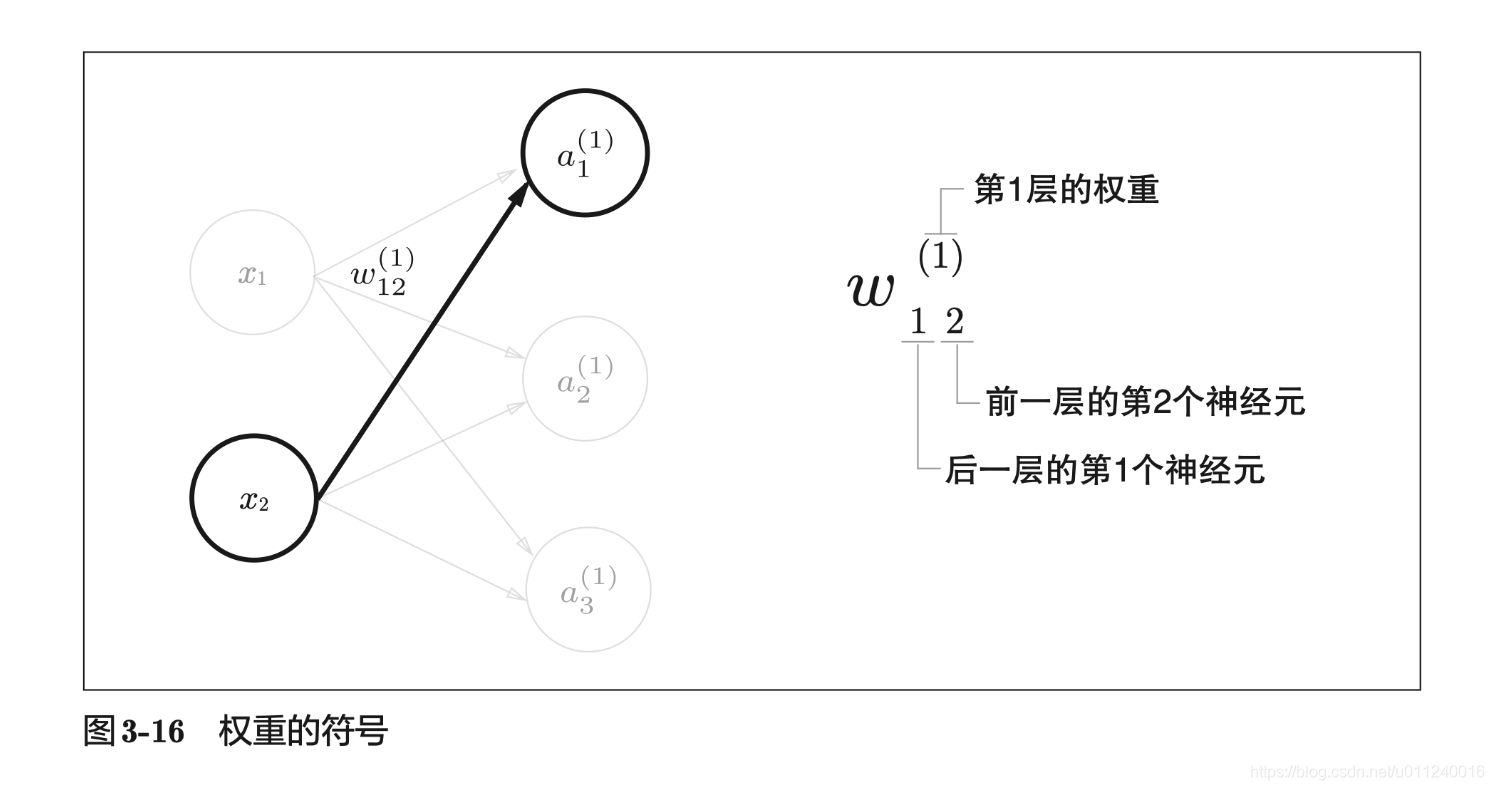
符号能帮助我们将概念表达清楚,上面这个,是站在当前神经元的立场来看,所以下标中第一个数字表示当前的神经元排序,第二个数字才是前一层的神经元排序,上标表示层数。
另外,每一层都会有一个偏置神经元,具体设定如下:
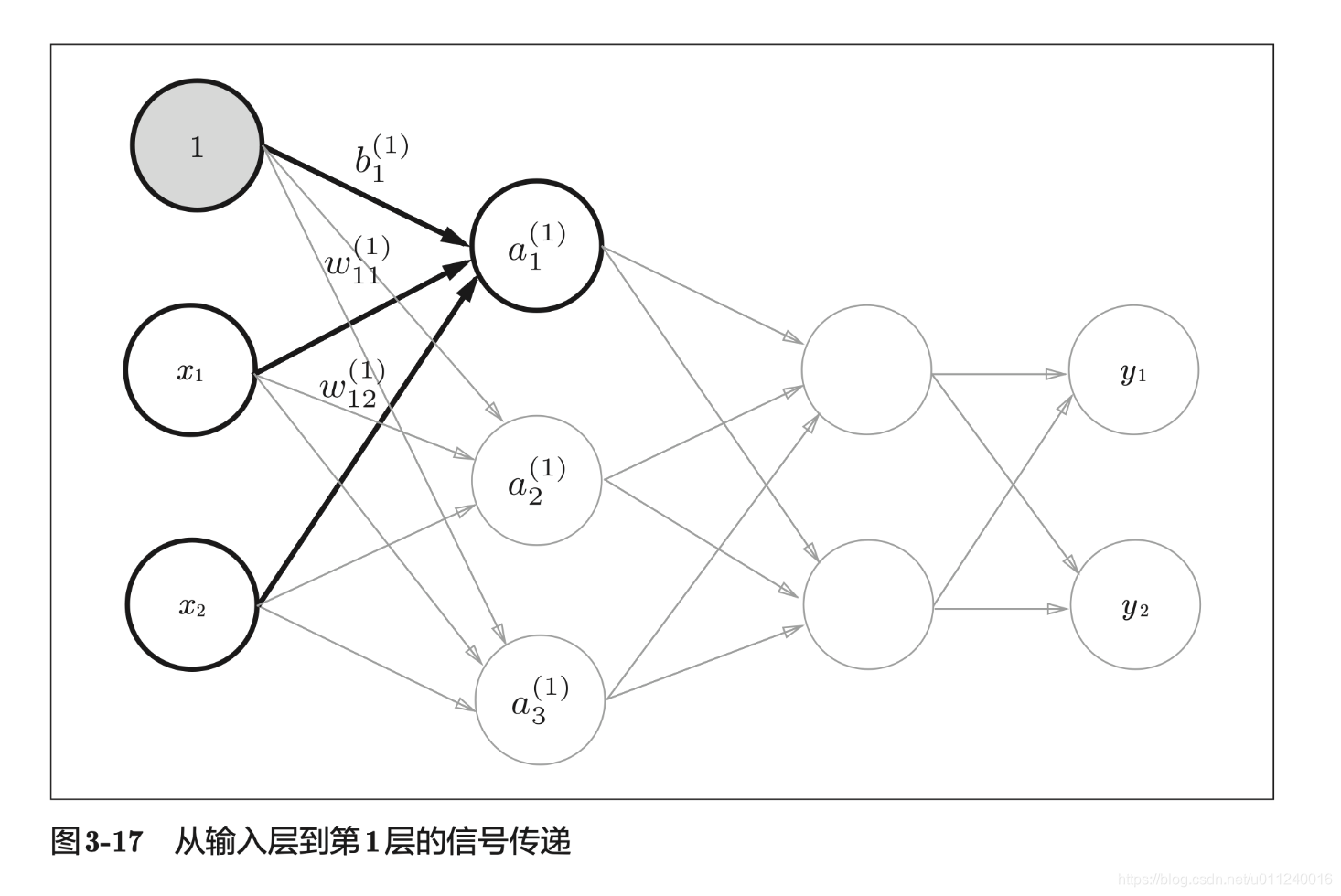
的下标就一个值,因为每一层只有一个偏置。
的表达如下
这只是表达了一个神经元的计算方式,而从更大一点的视角来看——矩阵的角度:
其中各个变量的表达如下:
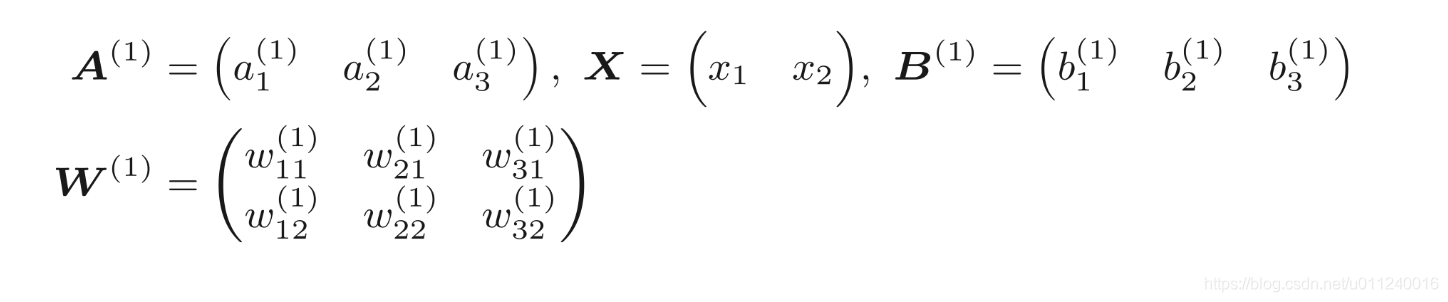
看起来非常复杂,其实就是前面的延伸,且无任何弯道。
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
print(W1.shape) # (2, 3)
print(X.shape) # (2,)
print(B1.shape) # (3,)
A1 = np.dot(X, W1) + B1
A1.shape # (3,)
总结:一维数组和矩阵点乘,数组在前则视为行向量,即形状视为 ;反过来,数组在后,则形状视为 ,其中 是一维数组元素个数。
我们输出一维数组的形状时,显示都是 ,往往会有一种感觉是,如果将其视作矩阵,则是m行,其实不一定,这是错误的看法。
上面的代码只完成了线性计算,再加上激活函数即可变成非线性的输出:
# 第一层到第二层的传递
Z1 = sigmoid(A1)
print(A1) # [0.3 0.7 1.1]
print(Z1) # [0.57444252 0.66818777 0.75026011]
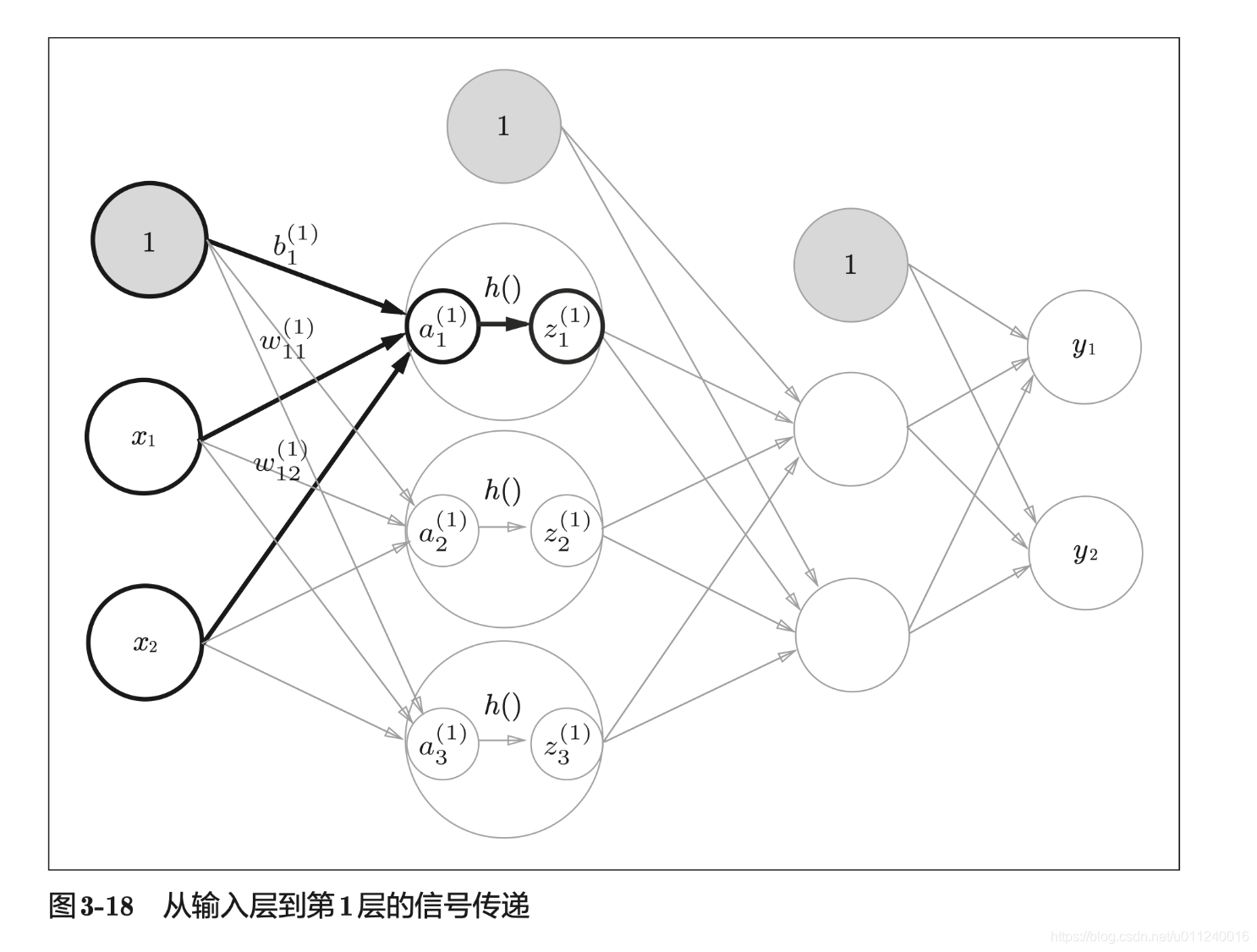
现在再向前推进一步:
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape)
print(W2.shape)
print(B2.shape)
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)
从第一层输出的结果是一维数组,元素有3个,现在我们再定义第一层向第二层传递时的参数,第一层的输出可以认为是
的行向量,则W的形状是3行2列,即当前层的神经元个数列。
最后再定义第二层向输出层传递:
# 输出层的激活函数:sigma
def identity_function(x):
return x
W3 = np.array([[0.1, 0.3],[0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_function(A3)
输出层激活函数定义
这里简单的梳理一下,输出层的激活函数,需要根据求解问题的性质来决定。
一般回归问题用的是恒等函数,二元分类问题用的是sigmoid函数,而多元分类问题则用softmax函数。
综合
# 按照惯例的实现
# 定义网络参数
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) # 2x3
network['b1'] = [0.1, 0.2, 0.3] # 3,
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]]) # 3x2
network['b2'] = [0.1, 0.2] # 2,
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]]) # 2x2
network['b3'] = [0.1, 0.2] # 2,
return network
def forward(network, x):
W1,W2,W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'],network['b2'],network['b3']
a1 = np.dot(x,W1) + b1 # 线性
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y # 最后的输出
# 实际调用
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [0.31682708 0.69627909]
这份综合的代码,将网络的设计和使用讲的非常通透,值得细细品味。其中,init_work()函数用来对权重和偏置的初始化,保存在network字典中,forward()函数则封装了将输入数据转化为输出信号的处理过程。且这里的forward表征的是数据的前向传递,后面训练会用到的后向backward。
总之,借助于Numpy,我们可以快速实现一个神经网络。
END.
完全参考:
《深度学习入门:基于Python的理论和实现》