一、PMDK介绍
pmdk,全称Persistent Memory Development Kit ,它是一套用于在非易失性内存(Non-volatile Memory,后文简称NVM)上进程编程的用户态软件库。如图1所示,NVM存储器可以使用具有DAX特性的文件系统直接暴露在用户空间,用户态程序可以使用文件系统VFS的API来操作NVM,同样也可以使用mmap将其直接映射到用户空间然后直接操作虚拟地址,与传统将磁盘文件mmap修改后需要手动调用msync不同,对NVM的修改可以直接调用缓存刷新指令(如CLFLUSH、CLFLUSHOPT、CLWB等),这些指令直接将cache line中的内容刷新到NVM中而不像msync一样需要经过文件系统层的page cache,这样性能会有很大的提升(当然你使用msync也是允许的)。
在使用文件系统时,数据的完整性一般都由文件系统来保证,而NVM作为一种非易失性存储,在使用mmap方式来读写时,如何保证数据的完整性和一致性就显得尤为重要。通常可以有很多种方式可以做到这一点(也就是后文即将讨论的),比如靠上层应用程序自己的策略来保证,也可以使用第三方库来做,而pmdk(更具体点来说是pmdk中的 libpmemobj)就是用来完成这项工作的。
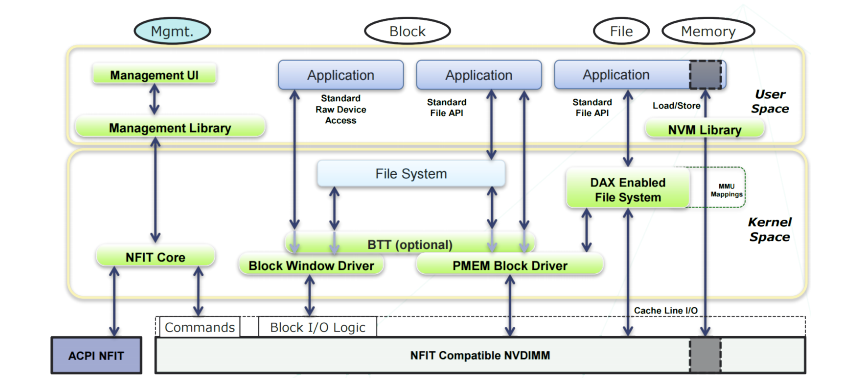
图1 PMDK在NVM编程中所处的位置
图2是pmdk的各个组件之间的依赖关系,其中libpmem提供底层的内存持久化、刷新接口,基于它,pmdk上层还提供了很多其他组件,比如本文重点介绍的libpmemobj就提供了存储的事务特性,其他组件的介绍将在以后的文章中逐步体现。
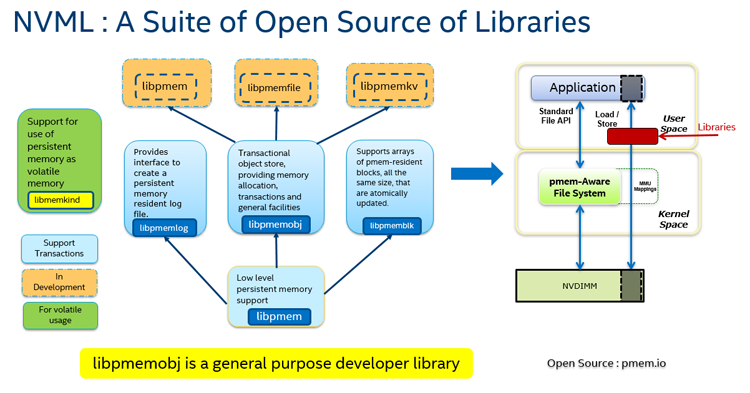
图2 PMDK包含的组件
二、基本概念介绍
1、内存池(Memory pools)
如前文所述,NVM作为一种快速、可字节寻址、持久型的存储,在被以DAX模式(通常NVM具有多种使用模式,比如memory mode 、app direct mode等)暴露在用户态以后(通常一块NVM DIMM在dev下回呈现出一个块设备,然后可以使用xfs等文件系统以dax的选项对其进行挂载),可以在其上创建很多文件,这些文件就称之为内存池(Memory pools),当然,有了pmdk之后,内存池的创建就不需要我们自己手动mmap了,可以使用pmemobj_create来完成,接口定义:
#define pmemobj_create pmemobj_createW
PMEMobjpool *pmemobj_createW(const wchar_t *path, const wchar_t *layout,
size_t poolsize, mode_t mode);其中path是要创建的文件的路径(也就是NVM被挂在的文件系统路径),layout可以理解为布局,也就是定义将来放入pool中的对象结构是如何定义的,poolsize是要创建的pool的大小,mode为文件的读写权限。
如果要打开一个已经存在的pool文件,那么可以使用pmemobj_open,接口定义:
#define pmemobj_open pmemobj_openU
PMEMobjpool *pmemobj_openU(const char *path, const char *layout);pmdk同样提供了pmemobj_check接口用来检测pool的完整性,接口定义如下:
#define pmemobj_check pmemobj_checkU
int pmemobj_checkU(const char *path, const char *layout);pmemobj_create和pmemobj_open都会返回一个PMEMobjpool指针,它就是创建或打开的pool的句柄(定义在pmdk/src/libpmemobj/obj.h),下面列出其主要成员:
struct pmemobjpool {
struct pool_hdr hdr; /* memory pool header */
/* 以下成员会保存在NVM中 (2kB) 进行持久化*/
char layout[PMEMOBJ_MAX_LAYOUT];//#define PMEMOBJ_MAX_LAYOUT ((size_t)1024)
uint64_t lanes_offset;
uint64_t nlanes;
uint64_t heap_offset;
uint64_t unused3;
/* 内存池描述符中持久化的部分占用的大小 (2kB) */
// #define OBJ_DSC_P_SIZE 2048
/* 内存池持久化部分未使用的部分大小 */
// #define OBJ_DSC_P_UNUSED (OBJ_DSC_P_SIZE - PMEMOBJ_MAX_LAYOUT - 40)
unsigned char unused[OBJ_DSC_P_UNUSED]; /* must be zero */
uint64_t checksum; /* 对以上成员的校验和 */
uint64_t root_offset; // 根对象在pool中的偏移,一个pool中只能最多有一个根对象
/* unique runID for this program run - persistent but not checksummed */
uint64_t run_id;
uint64_t root_size;// 根对象的大小
/*
* These flags can be set from a conversion tool and are set only for
* the first recovery of the pool.
*/
uint64_t conversion_flags;
uint64_t heap_size;
struct stats_persistent stats_persistent;
char pmem_reserved[496]; /* must be zeroed */
/* 以下成员为运行时状态,不会持久化到NVM中 */
void *addr; /* mapped后的地址 */
int is_pmem; /* 如果存储介质是PMEM就为true */
int rdonly; /* 如果内存池以只读方式打开就为true */
struct palloc_heap heap;
struct lane_descriptor lanes_desc;
uint64_t uuid_lo;
int is_dev_dax; /* 如果device dax模式就为true */
struct ctl *ctl;
struct stats *stats;
struct ringbuf *tx_postcommit_tasks;
struct pool_set *set; /* 内存池集合 */
struct pmemobjpool *replica; /* next replica */
struct redo_ctx *redo;// redo log,事务相关
/* 每个副本都需要的共用函数: pmem 或 non-pmem */
persist_local_fn persist_local; /* 内存持久化函数 */
flush_local_fn flush_local; /* 刷新缓冲区到内存 */
drain_local_fn drain_local; /* 排空缓冲区 */
memcpy_local_fn memcpy_persist_local; /* 持久型的memcpy函数 */
memset_local_fn memset_persist_local; /* 持久型的memset函数 */
/* 主副本: with or without data replication */
struct pmem_ops p_ops;
PMEMmutex rootlock; /* root object lock */
int is_master_replica;
int has_remote_replicas;
/* 远程副本,用于RDMA,不是本文讨论的重点 */
void *rpp; /* RPMEMpool opaque handle if it is a remote replica */
uintptr_t remote_base; /* beginning of the pool's descriptor */
char *node_addr; /* address of a remote node */
char *pool_desc; /* descriptor of a poolset */
persist_remote_fn persist_remote; /* 远端持久化函数,用于RDMA */
struct tx_parameters *tx_params;
};内存池的头pool_hdr定义在src/common/pool_hdr.h中:
struct pool_hdr {
char signature[POOL_HDR_SIG_LEN];
uint32_t major; /* format major version number */
uint32_t compat_features; /* mask: compatible "may" features */
uint32_t incompat_features; /* mask: "must support" features */
uint32_t ro_compat_features; /* mask: force RO if unsupported */
uuid_t poolset_uuid; /* pool set UUID */
uuid_t uuid; /* UUID of this file */
uuid_t prev_part_uuid; /* prev part */
uuid_t next_part_uuid; /* next part */
uuid_t prev_repl_uuid; /* prev replica */
uuid_t next_repl_uuid; /* next replica */
uint64_t crtime; /* when created (seconds since epoch) */
struct arch_flags arch_flags; /* architecture identification flags */
unsigned char unused[1888]; /* must be zero */
/* not checksumed */
unsigned char unused2[1992]; /* must be zero */
struct shutdown_state sds; /* shutdown status */
uint64_t checksum; /* checksum of above fields */
};
下面来重点讨论下pmemobjpool中提到的几个持久化函数,由于pmdk运行在模拟NVM的环境上运行,因此对于是否是pmem分别会有两种不同的缓存刷新策略,如下:
if (rep->is_pmem) {//如果是持久型内存
rep->persist_local = pmem_persist;
rep->flush_local = pmem_flush;
rep->drain_local = pmem_drain;
rep->memcpy_persist_local = pmem_memcpy_persist;
rep->memset_persist_local = pmem_memset_persist;
} else {// 否则就是普通内存,易失性内存
rep->persist_local = (persist_local_fn)pmem_msync;
rep->flush_local = (flush_local_fn)pmem_msync;
rep->drain_local = obj_drain_empty;
rep->memcpy_persist_local = obj_nopmem_memcpy_persist;
rep->memset_persist_local = obj_nopmem_memset_persist;
} 可以看到,针对非pmem时,persist_local被指向了pmem_msync,最终就是调用msync,这是个通用的函数(使用mmap映射的内存区域都可以只用msync进行刷新),但是这在NVM中会损失一些性能。针对NVM的特性,当pmdk处于NVM编程环境中时,persist_local就指向pmem_persist了,它的实现如下:
/*
* pmem_persist -- make any cached changes to a range of pmem persistent
*/
void
pmem_persist(const void *addr, size_t len)
{
LOG(15, "addr %p len %zu", addr, len);
// 将缓冲区中的内容刷新到NVM中
pmem_flush(addr, len);
// 等待排空缓冲区,本质是一个存储内存屏障
pmem_drain();
}进一步看看pmem_flush的实现:
/*
* pmem_flush() calls through Func_flush to do the work. Although
* initialized to flush_clflush(), once the existence of the clflushopt
* feature is confirmed by pmem_init() at library initialization time,
* Func_flush is set to flush_clflushopt(). That's the most common case
* on modern hardware that supports persistent memory.
*/
static void (*Func_flush)(const void *, size_t) = flush_clflush;
/*
* pmem_flush -- flush processor cache for the given range
*/
void
pmem_flush(const void *addr, size_t len)
{
LOG(15, "addr %p len %zu", addr, len);
Func_flush(addr, len);
}Func_flush是一个函数指针,它会根据当前cpu架构的型号、环境变量的设置等因素指向不同的处理函数,下午在讨论,下面再看pmem_drain函数:
/*
* pmem_drain() calls through Func_predrain_fence to do the fence. Although
* initialized to predrain_fence_empty(), once the existence of the CLWB or
* CLFLUSHOPT feature is confirmed by pmem_init() at library initialization
* time, Func_predrain_fence is set to predrain_fence_sfence(). That's the
* most common case on modern hardware that supports persistent memory.
*/
static void (*Func_predrain_fence)(void) = predrain_fence_empty;
/*
* pmem_drain -- wait for any PM stores to drain from HW buffers
*/
void
pmem_drain(void)
{
Func_predrain_fence();
}Func_predrain_fence同样也是一个函数指针,下面就看看Func_flush和Func_predrain_fence是怎么设置的,在pmem_get_cpuinfo函数中(该函数在pmem_init中被调用):
/*
* pmem_get_cpuinfo -- configure libpmem based on CPUID
* 根据cpu架构来配置libpmem
*/
static void
pmem_get_cpuinfo(void)
{
LOG(3, NULL);
// 当前cpu是否支持clflush指令
if (is_cpu_clflush_present()) {
Func_is_pmem = is_pmem_detect;
LOG(3, "clflush supported");
}
// 当前cpu是否支持clflushopt指令
if (is_cpu_clflushopt_present()) {
LOG(3, "clflushopt supported");
// 还可以手动设置环境变量来改变缓存刷新方式
char *e = os_getenv("PMEM_NO_CLFLUSHOPT");
if (e && strcmp(e, "1") == 0)
LOG(3, "PMEM_NO_CLFLUSHOPT forced no clflushopt");
else {
Func_flush = flush_clflushopt;
Func_predrain_fence = predrain_fence_sfence;
}
}
// 当前cpu是否支持clwb指令
if (is_cpu_clwb_present()) {
LOG(3, "clwb supported");
// 还可以手动设置环境变量来改变缓存刷新方式
char *e = os_getenv("PMEM_NO_CLWB");
if (e && strcmp(e, "1") == 0)
LOG(3, "PMEM_NO_CLWB forced no clwb");
else {
Func_flush = flush_clwb;
Func_predrain_fence = predrain_fence_sfence;
}
}
}针对 Func_flush,分别可能指向flush_clflushopt和flush_clwb,其定义为:
/*
* flush_clflushopt -- (internal) flush the CPU cache, using clflushopt
*/
static void
flush_clflushopt(const void *addr, size_t len)
{
LOG(15, "addr %p len %zu", addr, len);
uintptr_t uptr;
/*
* Loop through cache-line-size (typically 64B) aligned chunks
* covering the given range. 每次刷新一个缓存行
*/
for (uptr = (uintptr_t)addr & ~(FLUSH_ALIGN - 1);
uptr < (uintptr_t)addr + len; uptr += FLUSH_ALIGN) {
_mm_clflushopt((char *)uptr);
}
}同样flush_clwb函数定义为:
/*
* flush_clwb -- (internal) flush the CPU cache, using clwb
*/
static void
flush_clwb(const void *addr, size_t len)
{
LOG(15, "addr %p len %zu", addr, len);
uintptr_t uptr;
/*
* Loop through cache-line-size (typically 64B) aligned chunks
* covering the given range.
*/
for (uptr = (uintptr_t)addr & ~(FLUSH_ALIGN - 1);
uptr < (uintptr_t)addr + len; uptr += FLUSH_ALIGN) {
_mm_clwb((char *)uptr);
}
} 其中_mm_clflushopt和_mm_clwb定义为两个宏:
/*
* The x86 memory instructions are new enough that the compiler
* intrinsic functions are not always available. The intrinsic
* functions are defined here in terms of asm statements for now.
* 内联汇编指令
*/
#define _mm_clflushopt(addr)\
asm volatile(".byte 0x66; clflush %0" : "+m" (*(volatile char *)addr));
#define _mm_clwb(addr)\
asm volatile(".byte 0x66; xsaveopt %0" : "+m" (*(volatile char *)addr));
Func_predrain_fence函数指针在两种情况下都是指向predrain_fence_sfence,定义如下:
/*
* predrain_fence_sfence -- (internal) issue the pre-drain fence instruction
*/
static void
predrain_fence_sfence(void)
{
LOG(15, NULL);
_mm_sfence(); /* 就是一个内存屏障,为了保证CLWB指令或CLFLUSHOPT指令完成*/
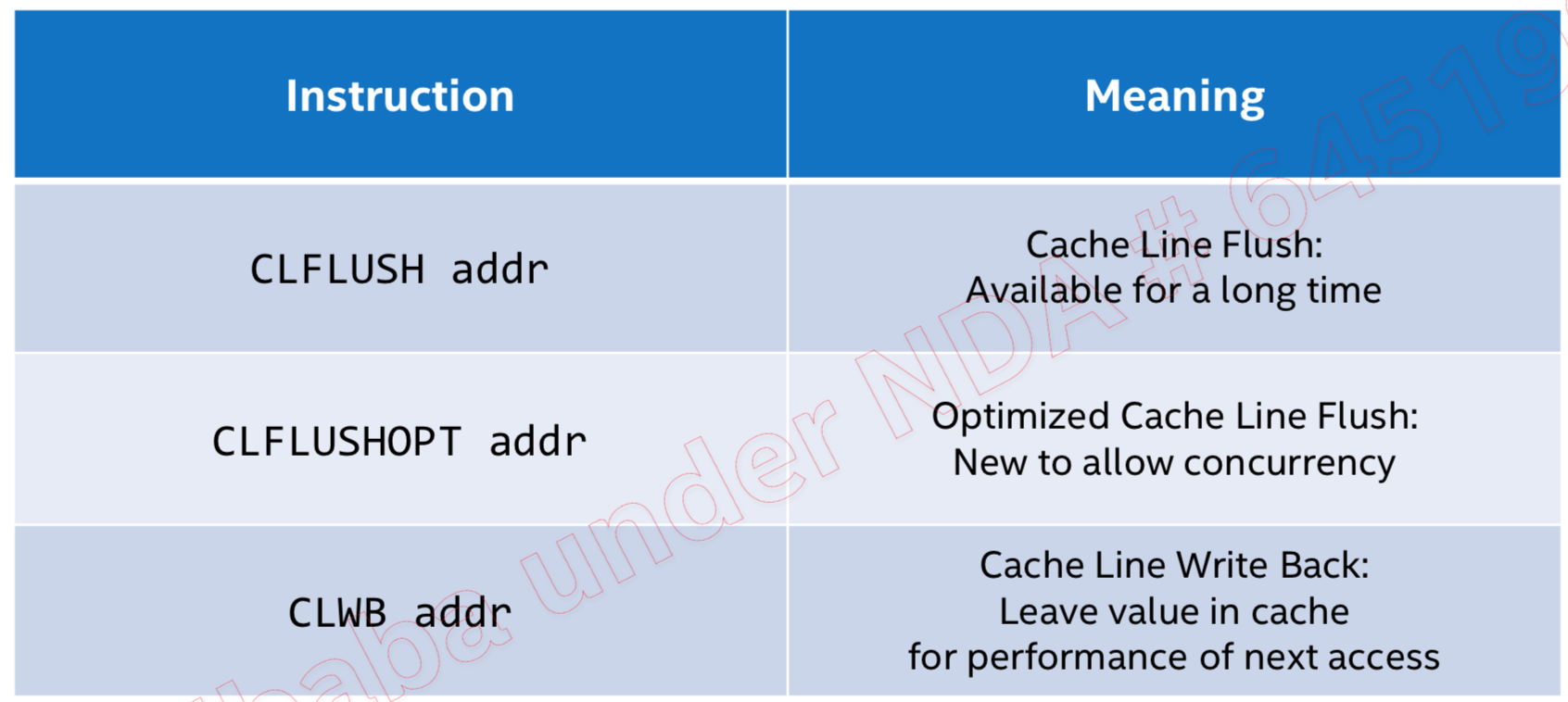
}clflushopt和clwb指令是Intel为了支持NVM特地加入的两条优化指令,他们都是用来将CPU多级缓存刷新到NVM中,下面先看看应用程序在向NVM中刷新一条数据时的过程。
首先,数据开始的时候被存储在cpu的多级缓存中,在执行CLFLUSH/CLFLUSHOPT/CLWB缓存刷新指令的时候,缓存中的数据会被刷新到内存控制器的写队列里面WPQ(也就是没有最终写到介质上),因此,理论上如果此时系统掉电,那么将会出现数据丢失的现象。但是在ADR(异步内存刷新)的保证下,即使掉电,写队列里面的数据也会在超级电容的作用下(电容里面存有足够的电量)安全的写到介质上。
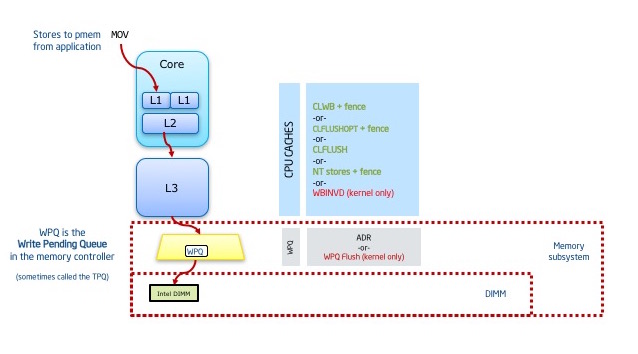
最开始,intel只支持CLFLUSH缓存指令,CLFLUSH的特点是顺序化、串行化的刷新缓存,其缺点是会导致cpu的流水线出现较大的stall时间,导致性能较差:
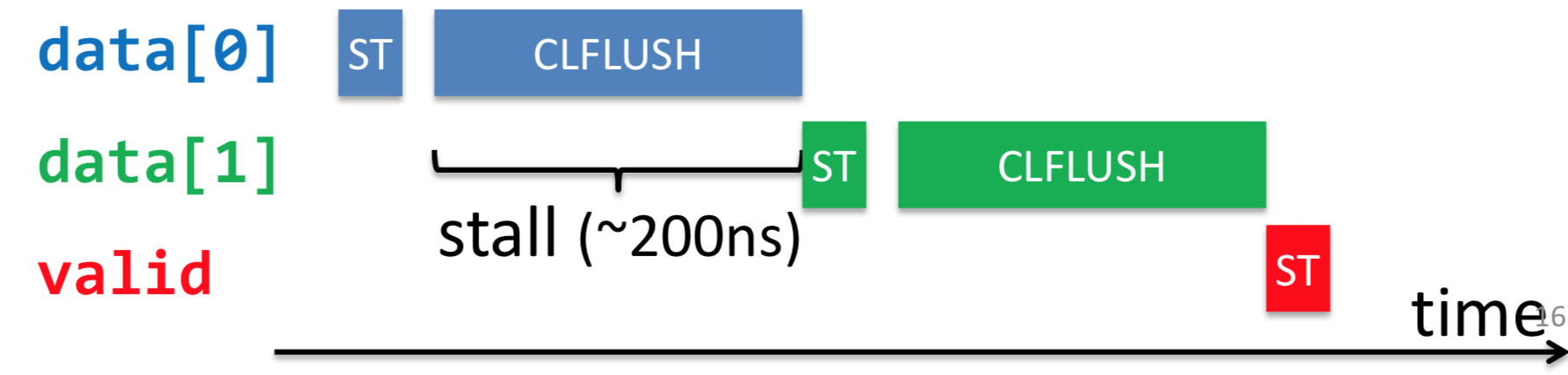
后来针对NVM加入了CLFLUSHOPT优化指令,他们之间的区别如下图所示:
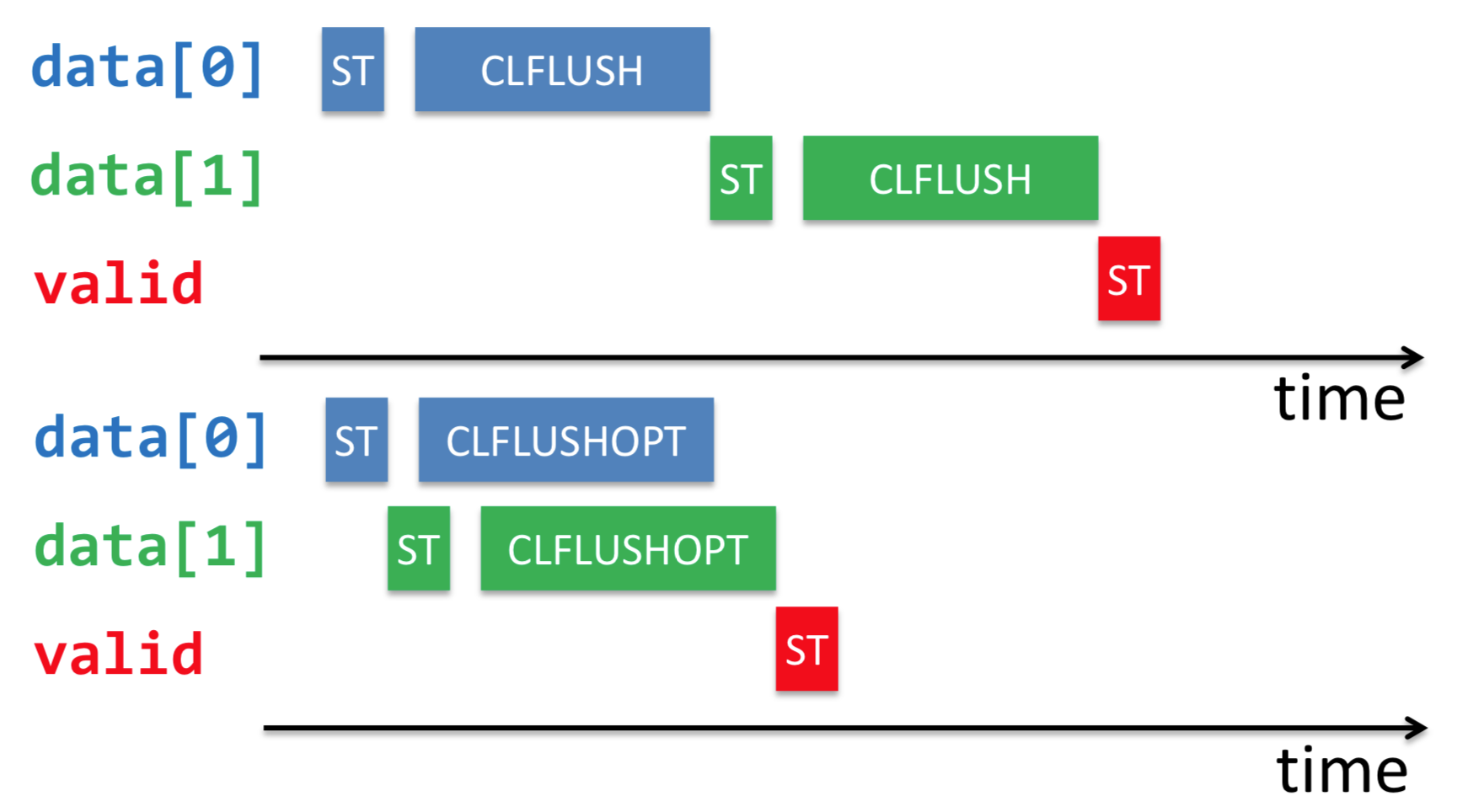
可见,CLFLUSHOPT就是相当于无序版本的CLFLUSH,新能自然会高很多,如下:
由于CLFLUSHOPT不在保证顺序顺序,因此对于上面的代码,需要在为valid置1之前加一个内存屏障,保证之前的CLFLUSHOPT操作全部完成(前文所说的pmem_drain就是完成这个功能)。
CLWB和CLFLUSHOPT完成的功能类似,唯一不同的是,CLWB在把缓存中的数据刷新之后,并不会失效它, 因此后续的读还是可以读到缓存中的数据,因此性能会好一些。下面总结一下他们之间的区别:
和操作系统中的其它资源一样,pool作为一种资源,在使用完成之后也需要进行关闭操作,该操作使用pmemobj_close函数完成:
/*
* pmemobj_close -- close a transactional memory pool
*/
void
pmemobj_close(PMEMobjpool *pop)