PointNet++论文学习笔记
本文记录了博主在学习论文《PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space》过程中认为重要的内容。更新于2018.11.05。
综述
之前博主学习过这篇论文的前序结构PointNet,并记录了笔记。与PointNet相比,PointNet无法获取每个点所在的度量空间所产生的局部结构,从而限制了其对于整齐排布的图形的识别能力以及对复杂场景的范化性。
论文作者指出,PointNet++的设计需要解决两个问题:如何生成点云的分区,以及如何通过一个局部特征学习算法抽象点云或局部特征。然而,这两个问题其实是相关的,因为分区的设计必须保证每个分区具有相似的结构,从而使得局部特征学习算法的参数可以在分区之间共享。
这里选择的局部特征学习算法就是PointNet,而分区则是选取了在最底层的欧氏空间内由质心(centroid)和尺寸(scale)描述的球形。为了保证整个点云被均匀覆盖,质心的选择应用了farthest point sampling(FPS)算法,其原理是先随机选一个点,然后选择离这个点距离最远的点(度量空间下距离度量最大的点)加入起点,如此迭代,直到选出需要的个数为止。相比较应用固定步长的卷积神经网络,这种适应性的结构既考虑了输入数据,也考虑了度量,因此论文声称这种方法更有效和高效。
这么做的难点在于如何确定球的尺寸,类似于如何确定CNN的卷积核尺寸。但是与CNN中不同的是,尽管有论文证明较小的卷积核尺寸可以提高CNN的表现(参考文献25),但是,论文的作者发现对于点云数据,小尺寸可能使得没有足够的点以供学习物体的模式。
论文的主要贡献在于,利用了多尺度邻域以同时实现鲁棒性和细节获取。
问题描述
假设 是一个度量继承自欧氏空间 的离散度量空间,其中 是一个点集, 是距离度量。且 在整个欧氏空间内的密度可能不同。
我们想要学习的是一个函数 ,其以 (和每个点的特征)作为输入,随后输出根据 生成的语义兴趣信息(information of semantic interest)。在实际应用中,这个 可能是给 标注类别的分类函数,也可能是给 的每个成员逐点标注的分割函数。
方法
结构介绍
论文首先回顾了PointNet,这里就不写了,感兴趣的看这里。相比较PointNet,PointNet++增加了获取不同尺度下的目标的能力,即新增了逐尺度抽象的结构,代替了原来的直接抽象整个点云的做法。下图是这一组集合抽象层(set abstraction layers)的结构:
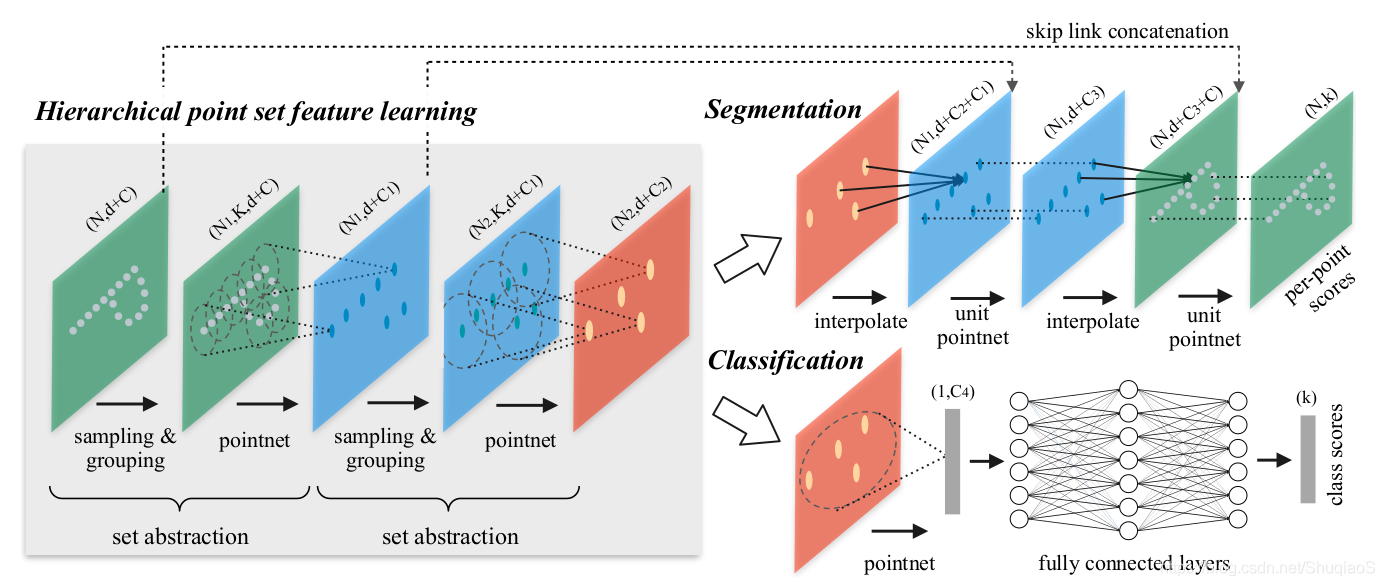
这个结构主要分为三个部分:
- 采样层(Sampling Layer):用于从输入点云中选取一部分点,这些点也就是局部区域的质心;
- 组合层(Grouping Layer):用于根据邻域规则,选取与质心“相邻”的点;
- PointNet层(PointNet Layer):用mini-PointNet将局部区域的图形编码成特征向量。
输入:维度为
的矩阵,含义是具有
维坐标信息和
维特征的
个点。
输出:维度为
的矩阵,含义是具有
维坐标信息和总结局部信息的新
维特征的二次抽样得到的
个点。
下面具体介绍一下这几个层:
采样层: 给定输入点集 ,论文中迭代应用最远点采样(Farthest Point Sampling, FSP)选取出一个子集 ,其中 是在度量空间内距离集合 最远的点。
组合层: 这一层的输入是一个尺寸为 的点集和一组尺寸为 的质心坐标。输出为尺寸是 的点集的组合,其中每个组都对应一个局部区域且 是质心点邻域的点数。需要注意的是,每组的 都是不同的,需要依靠随后的PointNet将它们转变成长度一致的局部特征向量。
相比较kNN而言,ball query方法使得邻域的区域尺寸固定,从而使提取的特征更能满足范化性要求。
PointNet层: 这一层的输入是 个点局部区域,数据尺寸为 。输出为每个区域的质心和描述质心邻域的局部特征,尺寸 。局部区域中的点的坐标先根据质心的坐标 调整为 ,其中 , 。
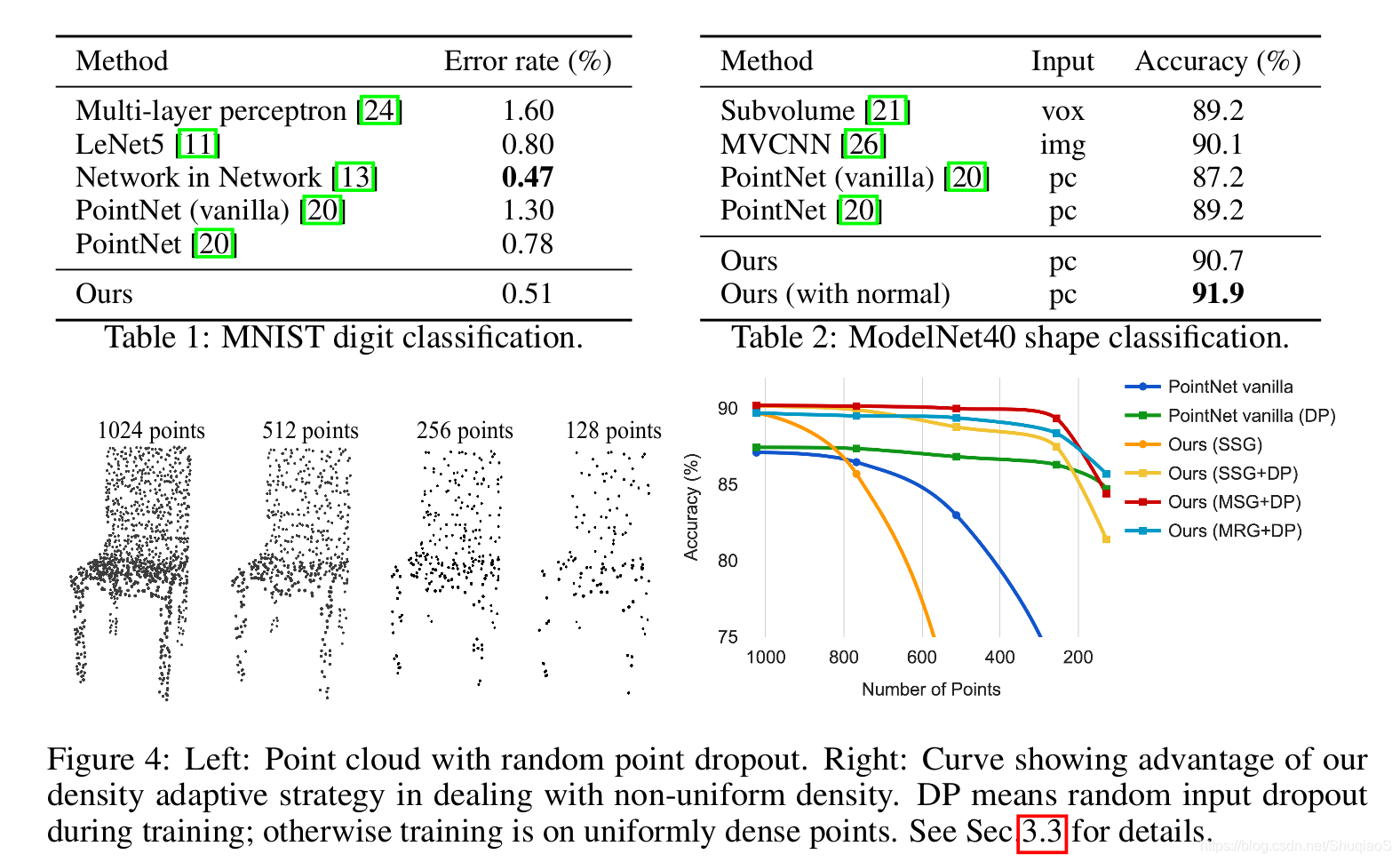
在非均匀采样密度下的鲁棒特征学习
非均匀采样密度:non-uniform sampling density
前文提到过点云数据在不同区域很有可能拥有不同的点密度,这就导致在稠密情况下训练出来的网络不一定适应稀疏条件下的估计,而满足稀疏条件估计的网络又很难范化至稠密区域。为了解决这个问题,论文提出了下面两个密度适应网络结构:
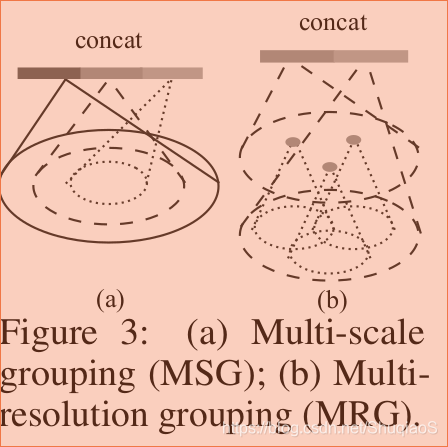
训练时,为了保证网络能够适应不同的点云密度,论文作者采用了随机选取的dropout概率 ,其范围在 之间,其中 。实际操作中,为了避免产生空集,作者取 。
这两个结构中,MSG的计算量非常大,因此作者提出了其替代结构MRG。
分割问题下的点特征传递
经过了前面的做法后,点云内包含的点的数量相比较原始输入是减小了的。因此,对于像分割这一类问题,就需要将点的个数恢复成原始水平。论文中采取了inverse distance weighted average的方法实现差值,公式如下:
其中, , 。
论文中默认取 。
实验
数据集
MNIST:手写数字数据集,60k训练,10k测试;
ModelNet40:40个类别的CAD模型(大部分是人造的),按照官方分成9843个训练形状,2468个测试形状;
SHREC15:50个类别的1200个形状,每个类别有24个形状,通常是结构体,姿势不同(如马、猫等),实验用5折交叉验证;
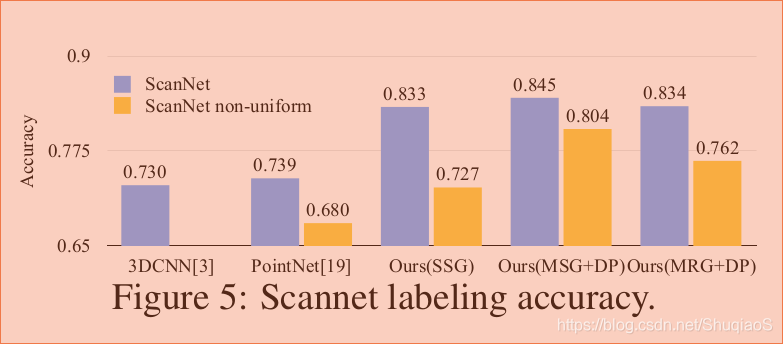
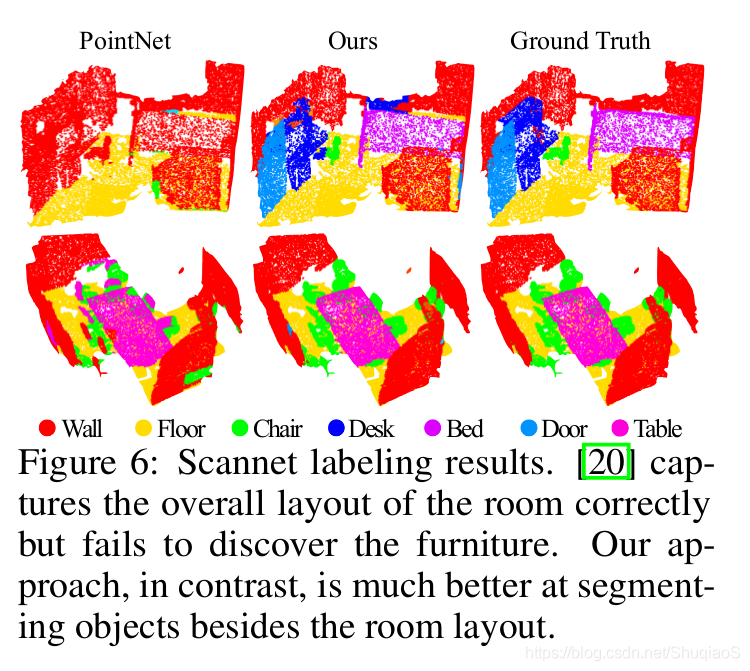
ScanNet:1513个扫描和重建的室内场景,用1201个场景训练,312个场景测试。
结果
分类:
分割: