感知机模型:
寻找一个超平面使数据集线性可分,寻找超平面的过程可以转化为最小化一个损失函数的过程:
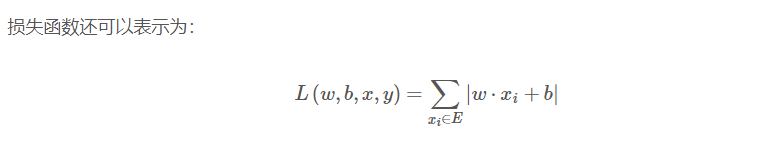
如何的来的?二元分类,y = +1使w⋅xi+b>0, y = -1使w⋅xi+b<0。
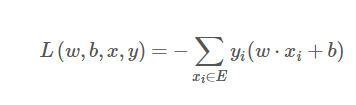
注意:需要强调的是,|w⋅xi+b|所描述的“相对距离”和我们直观上的“欧氏距离”或说“几何距离”是不一样的(事实上它们之间相差了一个∥w∥)。
感知机模型的随机梯度下降:
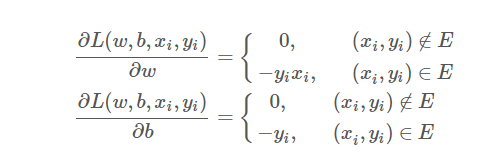
感知机模型的算法描述:
简单描述为:利用分错的点更新参数w和b,直到没有分错的点位置。
怎么选取分错的点,要么随机选取,要么选择分错的样本里面权重最大的点。
# 打乱标号
_indices = np.random.permutation(len(y))
# 取分错最严重的标号,没有样本权重,取打乱后第一个分错的标号
_idx = _indices[np.argmax(_err[_indices])]

感知机的代码实现:
# -*- coding: utf-8 -*-
import numpy as np
from Util.Bases import ClassifierBase
class Perceptron(ClassifierBase):
def __init__(self):
super(Perceptron,self).__init__()
self._w = None
self._b = None
def fir(self, x, y, sample_weight=None, lr = 0.01,epoch = 10**6):
x = np.atleast_2d(x)
y = np.array(y)
if sample_weight is None:
sample_weight = np.ones(len(y))
else:
# 这里的sample_weight为样本个数
sample_weight = np.array(sample_weight) * len(y)
# 初始化w,b
self._w = np.zeros(x.shape[1])
self._b = 0
# 训练
for _ in range(epoch):
# 得到预测值
y_pred = self.predict(x)
# 得到分错的向量:[样本] = 每个样本分错的权重,未分错为0
_err = (y_pred != y) * sample_weight
# 打乱标号
_indices = np.random.permutation(len(y))
# 取分错最严重的标号,没有样本权重,取打乱后第一个分错的标号
_idx = _indices[np.argmax(_err[_indices])]
# 都没有分错时,取得时分对了的标号,这是样本全部分对了,退出
if y_pred[_idx] == y[_idx]:
return
# 根据寻去的最大分错的方向yi,对应梯度lr*yi*xi
_delta = lr * y[_idx] *sample_weight[_idx]
self._w += _delta*x[_idx]
y += _delta
def predict(self, x, get_raw_result = False):
# np.sum相当于点乘的计算
rs = np.sum(self._w *x,axis=1) + self._b
if not get_raw_result:
return np.sign(rs)
return rs