hello的一生
目录(点击之后会打开新的页面,用富文本编辑器直接生成的目录,以后再改吧)
第1章 概述
1.1 Hello简介
在键盘上敲下的一个个字符通过总线传输到寄存器和主存中,按下crtl+s,hello.c诞生了,经过预处理器,编译器,汇编器,链接器的处理,hello.c终于从一个文本文件进化为hello可执行文件。当我们在shell中输入./hello 1170301004 wanghang 的时候,shell为它fork了一个子进程,让他得以在系统中有一席之地。在子进程中,execve将还在硬盘上的它映射到虚拟内存上。终于系统调度这个进程开始执行,它才被缺页中断处理程序带到了主存中。hello忠实的执行自己的使命,它在执行的过程中或许会遇到各种信号的“干扰”,导致它前进不前,甚至直接被终止,但是最终都将会被shell回收,hello完美谢幕。
1.2 环境与工具
硬件环境:Intel Core i7-6700HQ x64CPU,16G RAM,256G SSD +1T HDD.
软件环境:Ubuntu18.04.1 LTS
开发与调试工具:gcc,edb,gedit,readelf,objdump,HexEdit
1.3 中间结果
| 文件名 |
描述 |
| hello.c |
源代码 |
| hello.i |
预处理之后的文件 |
| hello.s |
编译之后的文件 |
| hello.o |
汇编之后的文件 |
| hello_rel.s |
hello.o反汇编代码 |
| hello |
链接之后的可执行文件 |
| hello_obj.s |
hello的反汇编代码 |
1.4 本章小结
本章从总体上简述了Hello的整个生命历程,列出了整个过程所处的环境和开发用到的工具,并且列处理产生的中间结果文件。
第2章 预处理
2.1 预处理的概念与作用
概念:预处理就是预处理器根据#标识的命令(头文件、宏定义、条件编译等),修改原始c代码,将包含的头文件插入到c代码中,并将宏定义进行替换,去除注释等,形成一个.i文本文件。
作用:
(1)将所有的#define删除,并且展开所有的宏定义,即就是字符替换。
(2)处理所有的条件编译指令,#ifdef #ifndef #endif等,来决定要编译哪些代码。
(3)处理#include,将#include指向的文件插入到该行处。
(4)删除所有注释。
(5)添加行号和文件标示,这样的在调试和编译出错的时候才知道是是哪个文件的 哪一行。
(6)保留#pragma编译器指令,因为编译器需要使用它们。
2.2在Ubuntu下预处理的命令
预处理指令:gcc -E hello.c -o hello.i

图2.1预处理指令
如上图可以发现hello.i文件比hello.c文件要大许多
2.3 Hello的预处理结果解析

图2.2 hello.i文件

图2.3 hello.i文件与stdio.h文件的对比
打开hello.i文件进行查看,发现原始c程序中代码已经变到了3100行,之前的3条预处理指令与注释已经不见了,说明预处理器已经将所要包含的库文件包含了进来。进一步深入解析,找到默认环境变量下的stdio.h,打开/usr/include/stdio.h之后发现其内部又有很多预处理指令,通过在hello.i中搜素,发现了确实在stdio.h中含有的代码,在hello.i中也有。而预处理指令却没有,说明预处理器还会对头文件进行进一步的预处理,所以最后的.i文件中没有任何预处理指令。
2.4 本章小结
预处理是C程序编译的第一步,它将我们的c程序需要的代码加入进来。可以说我们是“站在巨人的肩膀上编程”,当然轮子既然已经造好了那为什么不用呢?
第3章 编译
3.1 编译的概念与作用
概念:编译器(ccl)将文本文件hello.i翻译成文本文件hello.s,它包含一个汇编语言程序。
作用:
(1)词法分析:词法分析阶段是编译过程的第一个阶段。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。
(2)语法分析:语法分析是编译过程的一个逻辑阶段。语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等.语法分析程序判断源程序在结构上是否正确.源程序的结构由上下文无关文法描述.
(3)语义分析:语义分析是编译过程的一个逻辑阶段. 语义分析的任务是对结构上正确的源程序进行上下文有关性质的审查, 进行类型审查.
(4)优化后生成相应的汇编代码
3.2 在Ubuntu下编译的命令
命令:gcc -S hello.i -o hello.s
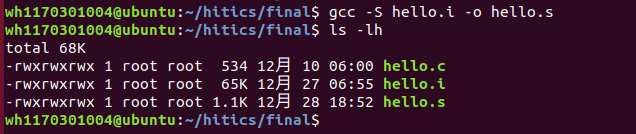
图3.1 编译指令
3.3 Hello的编译结果解析
3.3.1汇编代码中以“.”开头的指令
(即汇编指示(Assembler Directive)或伪操作(Pseudo-operation))

图3.2 汇编代码中的伪指令
其含义如以下表格:
| .file |
声明源文件 |
| .text |
代码段 |
| .globl |
声明一个全局可见的名字(可能是变量,也可以是函数名) |
| .align |
对指令或者数据的存放地址进行对齐 |
| .type |
用来指定一个符号的类型是函数类型或者是对象类型 |
| .size |
指定一个符号的大小 |
表 3.1 汇编代码中伪指令的含义
3.3.2数据:
1.全局变量:sleepsecs:

图3.3 全局变量sleepsecs的定义
.globl sleepsecs:定义也sleepsecs的全局符号
.data:将其存放在.data段(因为已经初始化)
.align 4:4字节对齐
.type sleepsecs, @object:指明该全局符号为变量
.size sleepsecs, 4:指明其大小为4字节
.long 2:赋初值为2(.long 声明一组数,每个数占32位,将sleepsecs作为该组数的首地址,在这里只声明了一个数,所以说将sleepsecs赋初值为2)
2.局部变量:int i;
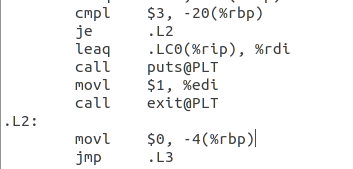
图3.4 main函数中局部变量i的定义
在栈中保存:如上图,当-20(%rbp)(即argc)等于3时,跳转到.L2执行循环,此时才给-4(%rbp)赋值为0,说明-4(%rbp)就表示局部变量i,所以说明程序将全局变量存放在了栈中。
3.字符串:
printf("Usage: Hello 学号 姓名!\n");
printf("Hello %s %s\n",argv[1],argv[2]);

图3.5 字符串的定义
两个printf函数中的格式字符串均被放到.rodata段,定义为.string类型,即字符串类型。其中汉字用utf-8编码表示,每个汉字占3个字节。
4常量:for(i=0;i<10;i++)
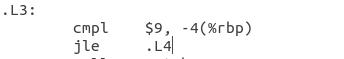
图3.6 常量的定义
直接用立即数表示,i<10,表示为i与9进行比较。
5.数组:char *argv[]

图3.7 对数组的引用
由函数调用的相关知识可以知道,%rdi存放printf的第一个参数,此处为格式串,%rsi存第二个参数,此处为argv[1],由此可以推断-32(%rbp)为argv的首地址,因为数组存放指针类型数据,大小为8B,所以argv[1]地址需要加8,然后通过(%rax)寻址argv[1]。同理argv[2]类似。
3.3.3 赋值操作:
1. int sleepsecs=2.5;
如图3.3,在开始的定义中就将sleepsecs赋值为2(因为类型转换的原因,下文会提到)
- i=0;
如图3.4,因为i为局部变量,所以将其存放在栈上,赋初值为0的语句为:
movl $0, -4(%rbp)
使用mov指令,根据数据大小使用不同的后缀。
| 指令 |
b |
w |
l |
q |
| 大小 |
1B |
2B |
4B |
8B |
表 3.2 汇编指令中后缀表示的数据大小
3.3.4 类型转换:
程序中只涉及到了一个隐式类型转换: int sleepsecs=2.5;
在c语言中小数默认为double类型,向int转换时会有精度上的损失,而这种转换只取整数,正如我们前面所提到的,sleepsecs被赋初值为2。其实float类型和double类型向int转换时,都只取整数。而如果只是限制小数个数时,则会发生四舍五入。
3.3.5 算术操作:
汇编中算术操作的指令有:
| 指令 |
效果 |
| LEAQ S,D |
D=&S |
| INC D |
D=D+1 |
| DEC D |
D=D-1 |
| NEG D |
D= -D |
| ADD S,D |
D=S+D |
| SUB S,D |
D=D-S |
| IMUL S,D |
D=D*S(有符号和无符号乘法,结果截断为64位) |
| Imulq S |
R[%rdx]:R[%rax]=S*R[%rax](有符号全乘法,结果保留128位) |
| MULQ S |
R[%rdx]:R[%rax]=S*R[%rax](无符号全乘法,结果保留128位) |
| IDIVQ S |
R[%rdx]=R[%rdx]:R[%rax] mod S(有符号除法) R[%rax]=R[%rdx]:R[%rax] div S |
| DIVQ S |
R[%rdx]=R[%rdx]:R[%rax] mod S(无符号除法) R[%rax]=R[%rdx]:R[%rax] div S |
表3.3 算术操作指令

图3.8 i++和计算字符串地址
1.i++:在循环体最后使用addl $1,-4(%rbp) 对i进行加1操作
2.leaq .LC1(%rip), %rdi:计算printf函数中格式串的地址,并传给%rdi
3.3.6 关系操作:
与关系操作相关的指令:
| 指令 |
效果 |
说明 |
| CMPX S1,S2 |
根据S2-S1的结果来设置条件码 |
后缀表示S1,S2的数据大小,这两类指令只设置条件码,而不改变任何其他寄存器 |
| TESTX S1,S2 |
根据S1&S2来设置条件码 |
|
| SETXX D |
根据XX设置D的值 |
目的数为低位单字节寄存器或一个字节的内存 |
| JMP Lable(或*LAble) |
无条件跳转到其他指令 |
分为之间跳转和间接跳转 |
| JXX Lable |
根据条件XX跳转到Lable |
条件跳转只能是直接跳转 |
表3.4 与关系操作和跳转有关的指令
程序中涉及到的关系操作:
1.!=: if(argc!=3):
cmpl $3, -20(%rbp)
je .L2
设置标志位之后直接利用je来判断$3和argv是否相等。
2.<: for(i=0;i<10;i++)
cmpl $9, -4(%rbp)
jle .L4
i<10等价为i<=9,所以将i与9比较后,用jle来判断。
3.3.7 数组操作:printf("Hello %s %s\n",argv[1],argv[2]);

图3.9 数组操作
根据函数调用的参数传递可知:%rsi存储的是argv[1],%rdx存储的是argv[2],-32(%rbp)存放的是argv[ ]的首地址,其中argc[ ]为字符指针类型,所以其元素大小为8字节,所以argv[1]的地址为:argv首地址-32(%rbp)+偏移量8,然后在对其进行寻址,得到argv[1]的值,同理argv[2]寻址与argv[1]类似,只是将偏移改为16即可。
3.3.8 控制转移:
1.if语句:if(argc!=3):
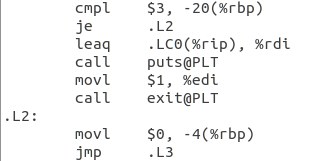
图3.10 if语句
如上图:比较-20(%rbp)(即argc)与3是否相等,若相等则表明条件不满足跳到.L2执行之后的语句,若不相等则表明条件满足,继续执行if内的语句
2.for循环:for(i=0;i<10;i++)

图3.11 for循环
先在.L2中对循环变量i(即-4(%rbp))赋初值0,然后跳到.L3判断i是否满足循环条件,若满足则跳到.L4执行循环体,否则执行循环体之后的语句,在循环体.L4的最后每次对循环变量i执行加1操作。
3.3.9 函数操作:
1.参数传递:
参数传递规则:
|
|
参数数量 |
||||||
|
|
1 |
2 |
3 |
4 |
5 |
6 |
>=7 |
| 存放位置 |
%rdi |
%rsi |
%rdx |
%rcx |
%r8 |
%r9 |
栈 |
表3.5 函数参数传递规则
程序中涉及到的参数传递有:
(1)main函数:int main(int argc,char *argv[ ]):
在进入main函数之前,其参数已经存在%rdi和%rsi中了。
(2)printf函数:
①printf("Usage: Hello 学号 姓名!\n");
![]()
图3.12 puts函数参数传递
因为这个printf函数只输出了一个字符串,所以被优化成了puts函数,其参数为字符串首地址,利用leaq .LC0(%rip),%rdi将字符串首地址放到%rdi中,然后再调用puts。
②printf("Hello %s %s\n",argv[1],argv[2]);

图3.13 printf函数参数传递
带有多个参数的传递,6个以内使用寄存器传参,超过七个则多出来的使用栈来传参,前三个参数依次分别使用%rdi,%rsi,%rdx进行传参。printf第一个参数为字符串地址,使用leaq .LC1(%rip),%rdi来构造,其余两个也是字符串首地址,但是是存在字符数组里的,所以通过内存寻址来构造,之前已介绍过,此处不再重复。
(3)exit函数:exit(1)
![]()
图3.14 exit函数的参数传递
同理只有一个参数,所以放到%edi中。
(4)sleep(sleepsecs);

图3.15 sleep函数的参数传递
此处先将全局变量放到%eax中,然后再放到了%edi中,为sleep构造参数。
2.函数调用:
参看“参数传递”中的图片,可知在参数构造好之后,使用“call 函数名”来调用函数。
3.函数返回 return

图3.16 函数返回
函数返回时,若有返回值,则先将返回值放到%rax中,再使用leave和ret返 回,其中leave是为了平衡堆栈,相当于push %rsp,%rbp pop %rbp,ret相 当于pop %rip,将%rip设置为函数调用结束后的第一条语句。
3.4 本章小结
编译器将.i文件翻译成.s文件,其中.s文件中使用汇编语言描述了低级机器语言指令。汇编语言是非常有用的,因为它为不同高级语言的不同编译器提供了通用的输出语言。接下来就轮到汇编器工作了。
(第3章2分)
第4章 汇编
4.1 汇编的概念与作用
概念:汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件hello.o中,该过程即为汇编器所起的作用。
4.2 在Ubuntu下汇编的命令
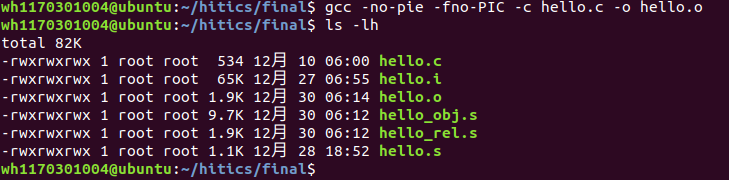
命令:gcc -no-pie -fno-PIC -c hello.c -o hello.o
从.s到.o的指令为:gcc -c hello.s -o hello.o,此处根据老师要求要使用-no-pie -fno-PIC命令,所以使用gcc -no-pie -fno-PIC -c hello.c -o hello.o生成hello.o

图4.1 汇编指令
4.3 可重定位目标elf格式
分析hello.o的ELF格式,用readelf等列出其各节的基本信息,特别是重定位项目分析。
通过命令readelf -a hello.o即可查看hello.o的ELF信息。
1.ELF头:

图4.2 ELF头
ELF头以一个16字节的序列开始,这个序列描述了生成该文件的系统的字的大小和字节顺序。
文件类型(Type):可重定位文件(REL)
机器类型(Machine):x86-64小端(Advanced Micro Devices X86-64)
入口地址(Entry point address):表明程序在虚拟地址0x0处开始运行。
ELF头大小(Size of this header):64bytes
节头部表的大小(Size of section headers):64bytes
节的个数(Number of section headers):13
2.节头部表:

图4.3 节头部表(Section Headers)
节头部表描述了每个节的大小、类型、位置还有偏移。
3.rela.text节(代码重定位节)
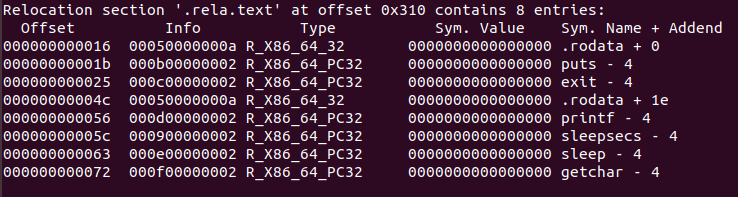
图4.4 .rela.text节
一个.text节中位置的列表,包含.text节中需要进行重定位的信息,当链接器把这个目标文件和其他文件组合时,需要修改这些位置。
每一行表示一条重定位条目,对应如下:
| Offset |
需要重定位的位置在.text(或.data)中的偏移 |
| Info高四个字节 |
symbol,要重定位到的符号(在符号表的序号) |
| Info低四个字节 |
type,采用的重定位方式 |
| Addend |
某些类型的重定位要用其对被修改引用的值做偏移调整 |
表4.1 .rela.text节中的重定位信息解读
我们来以第二个重定位记录作为示例模拟重定位:
第二个重定位条目r可以表示如下:
r.offset = 0x1b (说明要修改.text节中偏移为0x18位置处的代码)
r.symbol = b (说明要重定向到符号表中5的位置)
r.type = 2 (说明重定位方式为R-X86-64_PC32(即PC相对))
r.addend = -4 (用来对重定位位置做调整)
如下图可以在.rela.text节中找到该条记录

图4.5 通过hexedit查看.rela.text节
(1)r.offset具体说明:
在.text节的0x1b处需要被重定位,如下图所示:

图4.6 使用objdum查看hello.o

图4.7 使用hexedit查看hello.o
如上图,查询节头部表可知.text段在0x40处,由此可知如果是静态链接的话,第二个需要重定位的位置在hello.o中为0x40+0x1b=0x5b,当链接器工作时,将会修改这个地方。
- r.symbol说明:
这个表示需要重定向到的符号,在符号表(.symtab)中进行查询,如下图:

图4.8 符号表
说明该位置需要重定向到put函数。
(3)r.type = 2
表示该条重定位使用R-X86-64_PC32(即PC相对)来进行重定位。
假设链接器已经确定每个节和每个符号的运行时地址
(用ADDR(d)表示d的运行时地址)
①首先计算需要被重定位的位置
refptr = .text + r.offset
②然后链接器计算出运行时需要重定位的位置:
refaddr = ADDR(.text) + r.offset
③然后更新该位置
*refptr = (unsigned) (ADDR(r.symbol) + r.addend-refaddr)
此时,重定位就完成了。
有几个需要注意的点:
- 因为是PC相对的寻址方式,所以需要计算出运行时需要被重定位的位置和要重定位到符号的位置,然后计算两者的差,然后用这个差来修改当前.text中该位置的值,使其能够在运行时能够指向正确的位置。
- addend的作用:寻址全局变量时,使用%rip进行相对寻址,即下一条指令地址来进行寻址,所以此处addend = -4,就是为了调整上面计算出来的差变为符号与下一条指令地址的差,同理“call 相对地址”寻址也需要用到pc,所以addend也为-4。从图4.4中就可以看出。
其他重定位的处理类似。
4.rela.eh_frame

图4.9 .rela.eh_frame节的信息
这个节书上并没有介绍,发现其指向的符号的类型为ABS,书上介绍说是伪节,在节头部表中是没有条目的,ABS代表不该被重定位的符号。
5.symtab节:

图4.10 .symtab节
符号表,用来存放程序中定义和引用的函数和全局变量的信息。重定位需要引用的符号都在其中声明。
4.4 Hello.o的结果解析
使用objdimp -d -r hello.o>hello_rel.s 得到hello.o的反汇编代码,如下图所示

图4.11 hello.o的反汇编代码
1.反汇编.o文件得到的汇编代码和汇编.i文件得到的汇编代码的不同之处:
(1)汇编中mov、push、sub等等的指令后都有表示操作数大小的后缀,比如q、l等,反汇编得到的代码中没有。
(2)汇编代码中有很多以“.”开头的伪指令,用来指导汇编器和链接器工作,反汇编得到的代码中没有。
(3)汇编代码中调用函数是用“call 函数名”来表示,而反汇编代码中用“call 数字”表示,且相对应的机器代码中有PC相对引用的占位符。
(4)汇编代码中跳转“jmp Lable”的形式,在反汇编代码中直接为“jmp地址”的形式。
(5)对全局变量的访问,在汇编代码中是通过段名称+%rp,而在反汇编代码中是通过%rip+0,此处的0代表占位符,在链接时需要重定位。
2.机器语言的构成:
机器语言由二进制的机器指令序列集合构成,机器指令由操作码和操作数组成。
与汇编语言的映射关系:一条汇编语言对应一条机器指令,其中每条机器指令的长度不一定一致。(因为X86-64为CISC(复杂指令计算机),其指令编码长度可变(0-15个字节),与RISC(精简指令计算机)相对,其指令长度固定)
4.5 本章小结
汇编器将汇编指令翻译成了机器指令,.s文本文件终于变成了.o二进制文件,每个汇编程序因为大小不一,生成的.o文件中的机器代码和数据都不一样大,那么如何对这个只由01序列组成的文件进行解释呢?二进制文件不仅是代码和数据的集合,还有很多其他信息。因为它还要经过链接器和其他目标文件进行链接才能生成最后真正的可执行文件,所以必须要包含能够指导链接器工作的信息。这些信息可以通过readelf来查看,开始被称作ELF header的部分就是对整个.o文件的解释,接下来的section header描述了每个节的偏移和大小,这样汇编器就可以知道整个文件中的01序列到底该怎么解释了。其余部分就是各个节,有代码节,数据节,帮助链接器进行重定位的节等等。
(第4章1分)
第5章 链接
5.1 链接的概念与作用
概念:链接是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载(复制)到内存并执行。链接可执行于编译时,也就是在源代码被翻译成机器代码时;也可以执行与加载时,也就是在源代码被加载器加载到内存并执行时;甚至执行于运行时,也就是由应用程序来执行。
作用:链接使得分离编译成为可能,即可以将一个大项目分解为较小的、更好管理的模块,可以单独对其进行修改和变异,最后再将其链接到一起。
5.2 在Ubuntu下链接的命令
命令:
ld -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o/usr/lib/gcc/x86_64-linux-gnu/7/crtbegin.o-L/usr/lib/gcc/x86_64-linux-gnu/7 -L/usr/lib/x86_64-linux-gnu -L/usr/lib -L/lib/x86_64-linux-gnu -L/lib/../libhello.o-lc/usr/lib/gcc/x86_64-linux-gnu/7/crtend.o/usr/lib/x86_64-linux-gnu/crtn.o -z relro -o hello

图5.1 链接命令
5.3 可执行目标文件hello的格式
在ELF格式中,节头部表(Section Headers)对hello的各个节的信息做了说明,包括各段的起始地址(Address),大小(size),类型(Type),偏移(Offset)对齐要求(Align)等信息,如下图。


图5.2 hello各节的基本信息
链接器在链接可执行文件或动态库的过程中,它会把来自不同可重定位对象文件中的相同名称的 section 合并起来构成同名的 section。接着,它又会把带有相同属性(比方都是只读并可加载的)的 section 都合并成所谓 segments(段)。segments 作为链接器的输出,常被称为输出section。一个单独的 segment 通常会包含几个不同的 sections,比方一个可被加载的、只读的segment 通常就会包括可执行代码section .text、只读的数据section .rodata以及给动态链接器使用的符号section .dymsym等等。section 是被链接器使用的,但是 segments是被加载器所使用的。加载器会将所需要的 segment 加载到内存空间中运行。和用sections header table 来指定一个可重定位文件中到底有哪些 sections一样。在一个可执行文件或者动态库中,也需要有一种信息结构来指出包含有哪些segments。这种信息结构就是 program header table,如下图:

图5.3 hello的各个段的信息

图5.4 各个段包含的节
共有8个段,下面对各个段做以说明:
- PHDR:包含程序头表本身
- INTERP:只包含一个了section,即.interp,在这个节中,包含了动态链接过程中所使用的解释器路径和名称,如下图,可用hexedit进行查看

图5.5 hexedit查看INTERP段
- LOAD:第一个LOAD是代码段,第二个是数据段。在程序运行时需要映射到虚拟空间地址。
- DYNAMIC:保存了由动态链接器使用的信息
- NOTE:保存了辅助信息
- GNU_STACK:堆栈段,这一项除了 Flg/Align 两列不为空外, 其他列都为0。这是因为堆栈段在虚拟内存空间中,从哪里开始、占多少字节是由内核说了算的,而不决定于可执行程序。
- GNU_RELRO:指定在重定位结束之后那些内存区域是需要设置只读。
5.4 hello的虚拟地址空间
用edb加载hello,在Data Dump查看各段的信息:
根据图5.3,可以知道hello的每个段被映射到了哪段虚拟内存中。
以代码段和PHDR段为例进行对比分析,由图5.3可知,代码段偏移为0,被映射到虚拟地址0x0x0000000000400040,如图5.6和图5.7,可知位于hello开头的代码被加载到虚拟地址为0x400000的地方,同理PFDR段位于偏移0x40处,被加载到了0x400040处。

图5.6 代码段和PHDR段的虚拟地址空间

图5.7 hello的代码段和PHDR段
5.5 链接的重定位过程分析
objdump -d -r hello 分析hello与hello.o的不同,说明链接的过程。
结合hello.o的重定位项目,分析hello中对其怎么重定位的。
1.hello与hello.o的不同:
链接器在链接可执行文件或动态库的过程中,它会把来自不同可重定位对象文件中的相同名称的 section 合并起来构成同名的 section,在这里因为链接的时候指定了/lib64/ld-linux-x86-64.so.2,crt1.o、crti.o、crtn.o,所以将会把这些.o文件的每个节与hello.o的节合并。在合并的过程中,会根据重定位信息对相应的地方进行重定位,比如hello.o中的.text节和.data节,接着,它又会把带有相同属性(比方都是只读并可加载的)的 section 都合并成所谓 segments(段)。segments 作为链接器的输出,常被称为输出section。所以说hello.o只是hello的一部分。通过将两者的反汇编代码进行比对也能看出这一点,hello的反汇编代码中也比hello.o的反汇编代码节要多:.init .plt .text .fini,在这些节中多出了一些main函数运行必要的函数:_start,_init,__libc_csu_init,__libc_csu_fini,__libc_start_main,和在hello中调用的函数:printf、sleep、getchar、exit函数。
2.hello是如何进行重定位的:
在4.3节中我们举了一个具体的例子来说明重定位条目是如何来指导进行重定位的,这里我们继续这个例子来说明:
①首先计算需要被重定位的位置
refptr = .text + r.offset = 0x4005e7 + 0x1b = 0x400602
②然后链接器计算出运行时需要重定位的位置:
refaddr = ADDR(.text) + r.offset = 0x4005e7+0x1b = 0x400602
③然后更新该位置
*refptr = (unsigned) (ADDR(r.symbol) + r.addend-refaddr)
查看反汇编代码,与我们推出来的一致,如下图:

图5.8 puts函数的重定位
因为puts函数是共享库函数,共享库加载的时候运行时地址无法预测,所以它会在运行时由动态链接器采用一种叫做延迟绑定的技术来进行链接,所以这里被重定位为call 4004b0,而4004b0为puts函数对应的PLT表第一条指令的地址。详细介绍请看下一节。
5.6 hello的执行流程
使用edb执行hello,从加载hello到_start,到call main,以及程序终止的主要过程如下:
| 函数名 |
地址 |
| ld-2.27.so!_dl_start |
0x7f96ed2e1ea0 |
| ld-2.27.so!_dl_init |
0x7f96ed2f0630 |
| hello!_start |
0x400500 |
| libc-2.27.so!__libc_start_main |
0x7fbdf0cccab0 |
| hello!puts@plt |
0x4004b0 |
| hello!exit@plt |
0x4004e0 |
| hello!printf@plt |
0x4004c0 |
| hello!sleep@plt |
0x4004f0 |
| hello!getchar@plt |
0x4004d0 |
| libc-2.27.so!exit |
0x7f66b7b9e120 |
5.7 Hello的动态链接分析
分析hello程序的动态链接项目,通过edb调试,分析在dl_init前后,这些项目的内容变化。要截图标识说明。
1.PIC全局数据引用:
编译器在数据段开始的地方创建了一个表,叫做全局偏移量表(GOT),在GOT中,每个被这个目标模块引用的全局数据目标都有一个8字节条目。编译器还为GOT中每个条目生成一个重定位记录,在加载时,动态链接器会重定位GOT中的每个条目,使得它包含目标正确的绝对地址。
2.PIC函数调用:
GNU系统使用被称为延迟绑定(lazy binding)的技术来动态链接共享库中的函数。这个过程需要两个数据结构来实现:GOT和过程链接表(PLT),GOT是数据段的一部分,PLT是代码段中的一部分。
下面以调用puts函数为例进行说明:
第一次调用共享库函数:
0x4004b0 = 0x00000000004004b0 <hello!puts@plt+0>

图5.9 调用puts函数,实质上是跳转到puts函数的PLT条目处。
*0x200b62(%rip) = [0x0000000000601018] = 0x00000000004004b6 <hello!puts@plt+6>

图5.10 通过GOT表进行间接跳转到对应PLT的第二条指令
在调用puts函数时,实质上会跳转到puts对应的PLT代码处,执行PLT的第一条指令,第一条指令通过GOT进行间接跳转,第一次调用时,GOT表内存的是PLT的第二条指令地址,此时会把puts函数的ID压入栈,如图5.10,然后通过GOT间接地把动态链接器的一个参数压入栈中,如图5.11。最后动态链接器使用两个栈条目来确定puts的运行时位置,用这个地址重写对应的GOT表,如图5.12,再运行puts函数。第二次调用puts函数时,执行PLT第一条指令,这时第一条指令通过GOT表进行间接跳转会直接跳转到puts函数。

图5.11 通过GOT将动态链接器的一个参数压栈

图5.12 动态链接器确定puts运行时代码并修改GOT表代码
下面查看GOT表是否被修改:
由图5.10可知对应GOT表在0x601018处,未修改前是0x4004b6,即PLT第二条指令地址,如下图。
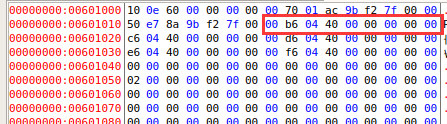
图5.13 dl_init执行前puts函数对应的GOT条目

图5.14 dl_init执行后puts函数对应的GOT条目
如图5.14,可知dl_init在第一次调用puts函数时,将其对应的GOT表条目修改为puts函数真正的地址。
5.8 本章小结
链接是将各种代码和数据片段收集并组合成为一个单一文件的过程。链接的时间可以在编译形成可执行代码时,也可以在可执行文件加载时,甚至可以在程序运行时。编译时链接就是链接器以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的、可以加载并运行的可执行文件作为输出,即这个文件再不需要任何东西就可以直接运行。但是系统中运行着很多程序,它们中很多函数是相同的,比如printf,每个程序都包含一个printf,那么将会占用很多内存。所以就出现了加载时链接,把一些共用的函数在内存中只放一个副本,当程序被加载到内存时,哪个程序需要它就直接去用。后面又出现了运行时链接,因为程序中有些函数甚至是不会被运行的,比如分支语句中。所以加载时链接也有些浪费,所以就出现了运行时链接,直到第一次调用它时才调用动态链接器去链接。这种动态链接也被成为延迟绑定(5.7节)。通过链接我们就能看到为了不必要的浪费,一件事能做到多极致。
(第5章1分)
第6章 hello进程管理
6.1 进程的概念与作用
进程是一个执行中程序的实例,系统中每个程序都运行在某个进程的上下文中。上下文是由程序正确运行所需的状态组成的。这个状态包括存放在内存中的程序的代码和数据,它的栈、通用目的寄存器的内容、程序计数器、环境变量以及打开文件描述符的集合。
进程为程序提供了一个假象:好像它是系统当前唯一运行的程序,好像是在独占的使用处理器和内存,处理器好像在无间断的执行该程序中的指令,好像它的代码和数据是系统内存中唯一的对象。
6.2 简述壳Shell-bash的作用与处理流程
作用:shell-bash是一个交互型的应用级程序,它代表用户运行其他程序。能够执行一系列的读/求值(read/evaluate)步骤,然后终止。
处理流程:
- 读入用户输入命令
- 将用户输入的命令进行解析
- 若命令为内置命令则立即执行
- 否则若是一个可执行文件,则会在一个新子进程的上下文中加载并运行这个文件,若用户要求在后台运行,那么shell继续等待用户输入其他的命令,否则shell将等待该程序运行结束后,再进行下一条命令的处理。
- shell还会接收用户通过键盘输入的信号(ctrl+z ctrl+c等),并执行相应的操作。
6.3 Hello的fork进程创建过程
当用户输入./hello 1170301004 王航 时,shell将对该命令进行解析,判断第一个参数./hello,不是shell内置的命令,所以会在指定目录下寻找该可执行文件,这里是当前目录下的hello文件。然后shell将会为hello fork一个子进程,并在子进程中执行hello。新创建的子进程几乎但不完全与父进程相同。子进程得到与父进程用户级虚拟地址空间相同(但是独立的)一份副本,包括代码和数据段、堆、共享库以及用户栈。子进程还获得与父进程任何打开文件描述符相同的副本,这就意味着当父进程调用fork时,子进程可以读写父进程打开的任何文件。父进程和新创建的子进程之间最大的区别在于它们有不同的PID。父进程和子进程是并发运行的独立进程,内核能够以任何方式交替执行它们的逻辑控制流中的指令。

图6.1 hello在前台运行时简易进程图
6.4 Hello的execve过程
在shell创建的子进程中将会调用execve函数,来调用加载器,加载器将可执行目标文件中的代码和数据从磁盘复制到内存中,然后通过跳转到程序的第一条指令或入口点来运行该程序。这个将程序复制到内存并运行的过程叫做加载。每个程序都有一个运行时内存映像,如图6.2所示。当加载器运行时,它创建类似图6.2所示的内存映像。在程序头部表的引导下,加载器将可执行文件的片(chunk)复制到代码段和数据段。接下来,加载器跳转到程序的入口点,也就是_start函数的地址。这个函数是在系统目标文件ctrl.o中定义的,对所哟额C程序都是一样的。_start函数调用系统启动函数_ _libc_start_main,该函数定义在libc.so中,它初始化执行环境,调用用户层的main函数,处理main函数的返回值,并且在需要的时候吧控制返回给内核。

图6.2 运行时内存映像
6.5 Hello的进程执行
逻辑控制流:即使在系统中通常有许多其他程序正在运行,进程也可以向每个程序提供一种假象,好像它在独占地使用处理器。如果使用调试器单步调试执行程序,我们会看到一系列的程序计数器(PC)的值,这些值唯一地对应于包含在程序的可执行目标文件中的指令,或是包含在运行时动态链接到程序的共享对象中的指令。这个PC值的序列叫做逻辑控制流,简称逻辑流。

图6.3 逻辑控制流,每个竖直的条表示一个进程的逻辑控制流的一部分
并发流:系统为每个程序都提供了一种只有它一个程序在运行的假象,但是实际情况却不是这样的,系统中很有很多其他程序在运行,比如我现在打字的word和我的虚拟机就是两个程序,它们都在运行。那么处理器是如何执行它们的,以至于让它们看起来都在不间断的一直运行呢?答案就是并发,如图6.3,处理器分时间段执行进程A、B、C,这个转换的时间非常短,所以看起来就好像每个进程都在持续不断的在运行。多个逻辑控制流并发执行的一半现象被称为并发。一个进程和其他进程轮流运行的概念成为多任务,一个进程执行它的控制流的每一时间段就成为时间片。如图6.3中进程A就由两个时间片组成。
内核模式和用户模式:内核模式和用户模式不是两个进程,而是一个进程的不同模式,由一个模式位来控制,当设置了模式位时,进程就运行在内核模式中,这时候这个进程就可以执行指令集中的任何指令,并且可以访问系统中的任何内存位置。没有设置模式位时,进程就运行在用户模式中。用户模式中的进程不允许执行特权指令,反之,用户程序必须通过系统调用接口间接地访问内核代码和数据。运行程序代码的进程一开始是处于用户模式,只有当发生中断、故障或者陷入系统调用这样的异常时,转而去执行异常处理程序,这时进程才会变为内核模式。当它返回到应用程序代码时,处理器就把模式从内核模式改为用户模式。
上下文信息:内核重新启动一个被抢占的进程所需的状态。它由一些对象的值组成,这些对象包括通用目的寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器、内核栈和各种内核数据结构。
上下文切换:内核为每个进程维持一个上下文,上下文就是在进程执行的某些时刻,内核可以决定枪战当前进程,并重新开始一个先前被抢占了的进程。这种决策就叫做调度。系统调用和中断也可能引发上下文切换。
有了上面这些知识,我们来看hello的进程执行:
- shell为hello fork了一个子进程,这个子进程和shell进程有独立的逻辑控制流,它们是并发进行的,但是若hello是以前台任务进行的,那么shell将会挂起等待hello运行结束,否则它们将会“同时运行”。
- 内核调度hello的进程开始进行,输出Hello 1170301004 wanghang,然后执行sleep(sleepsecs)函数,这个函数是系统调用,它显示地请求让调用进程休眠。内核转而执行其他进程,这时就会发生一个上下文转换。2s后(sleepsecs被隐式类型转换为2),又会发生一次进程转换,恢复hello进程的上下文,继续执行hello进程。如图6.4,其余9次sleep的执行类似。
- 循环结束后,后面执行到getchar函数,getchar函数是通过read函数实现的。这时hello进程将会因为执行系统调用read而陷入内核,内核中的陷阱处理程序请求DMA传输,这时读取数据一般需要很长的时间,所以将会发生一个上下文切换转而执行其他进程,当数据已经被读取到缓存区中,将会发生一个中断,使内核发生上下文切换,重新执行hello进程,与调用sleep时的进程执行情况类似。

图6.4 hello进程执行
6.6 hello的异常与信号处理
(以下格式自行编排,编辑时删除)
hello执行过程中会出现哪几类异常,会产生哪些信号,又怎么处理的。
程序运行过程中可以按键盘,如不停乱按,包括回车,Ctrl-Z,Ctrl-C等,Ctrl-z后可以运行ps jobs pstree fg kill 等命令,请分别给出各命令及运行结截屏,说明异常与信号的处理。
1.hello正常执行时:
在调用sleep和getchar时将会出现陷阱异常,内核会调度其他进程运行,之后会重新执行hello进程。程序会依次输出10条Hello 1170301004 wanghang,最后等待用户输入,当用户输入结束后,hello进程结束发送SIGCHLD信号,然后被shell回收掉。如下图所示:

图6.5 hello正常执行时
2运行途中乱按键盘
这时运行情况和前面的相同,不同之处就在于,shell将用户乱输入的字符除了第一个回车按下之前的字符当做getchar的输入之外,其余都当做新的shell命令,在hello进程结束被回收之后,将会解释这些命令。

图6.6 hello运行途中乱按键盘
3.使用ctrl+z:
在hello运行过程中按下ctrl+z将会发送一个SIGTSTP信号给shell,然后shell将转发给当前执行的前台进程组,使hello进程挂起。使用ps命令查看,发现hello进程依旧存在,之后使用fg命令使其继续运行。Hello进程继续输出字符串,在等待用户输入阶段,我们继续使用ctrl+z使其停止,然后使用kill命令发送SIGKILL函数给hello进程。hello进程接收到SIGKILL信号后,当内核重新调度hello进程,hello进程从内核模式转为用户模式之前,先会检查hello的未被阻塞的待处理信号的集合,然后执行相应的信号处理程序,此时hello程序将会终止。进而发送SIGCHLD信号被shell回收。

图6.7 hello执行过程中使用ctrl+z,并输入一些其他命令
6.7本章小结
一个系统中有成百上千个程序在同时运行,那么如何管理它们,让它们既能互不影响的运行,又能在必要的时候进行通信就是一个很重要的问题。一个系统要能够有效的运行,它必须建立一个简单但有效的模型。计算机系统为了解决这个问题,提供了两个抽象:进程让每个程序都以为只有它自己在运行,虚拟内存让每个程序都以为它自己在独占整个内存空间。这两个抽象使得计算机系统能够对每个程序都够以一致的方式去管理。多任务就通过进程之间快速的切换来实现,程序之间的影响就通过进程之间的通信——信号来实现。
第7章 hello的存储管理
7.1 hello的存储器地址空间
结合hello说明逻辑地址、线性地址、虚拟地址、物理地址的概念。
物理地址:加载到内存地址寄存器中的地址,内存单元的真正地址。在前端总线上传输的内存地址都是物理内存地址,编号从0开始一直到可用物理内存的最高端。这些数字被北桥(Nortbridge chip)映射到实际的内存条上。物理地址是明确的、最终用在总线上的编号,不必转换,不必分页,也没有特权级检查(no translation, no paging, no privilege checks)
逻辑地址:是指由程序产生的与段相关的偏移地址部分。例如,你在进行C语言指针编程中,可以读取指针变量本身值(&操作),实际上这个值就是逻辑地址,它是相对于你当前进程数据段的地址。
线性地址:跟逻辑地址类似,它也是一个不真实的地址,如果逻辑地址是对应的硬件平台段式管理转换前地址的话,那么线性地址则对应了硬件页式内存的转换前地址。线性地址即就是CSAPP书中所说的虚拟地址。
7.2 Intel逻辑地址到线性地址的变换-段式管理
逻辑地址的实际上是一对<选择符,偏移>,选择符的内容如下:

图7.1 逻辑地址的含义
从左开始,13位是索引(或者称为段号),通过这个索引,可以定位到段描述符(segment descriptor),而段描述符是可以真正记载了有关一个段的位置和大小信息, 以及访问控制的状态信息。段描述符一般由8个字节组成。由于8B较大,而Intel为了保持向后兼容,将段寄存器仍然规定为16-bit(尽管每个段寄存器事实上有一个64-bit长的不可见部分,但对于程序员来说,段寄存器就是16-bit的),那么很明显,我们无法通过16-bit长度的段寄存器来直接引用64-bit的段描述符。因此在逻辑地址中,只用13bit记录其索引。而真正的段描述符,被放于数组之中。
这个内存中的数组就叫做GDT(Global Descriptor Table,全局描述表),Intel的设计者门提供了一个寄存器GDTR用来存放GDT的入口地址。程序员将GDT设定在内存中某个位置之后,可以通过LGDT指令将GDT的入口地址装入此寄存器,从此以后,CPU就根据此寄存器中的内容作为GDT的入口来访问GDT了。除了GDT之外,还有LDT(Local Descriptor Table,本地描述表),但与GDT不同的是,LDT在系统中可以存在多个,每个进程可以拥有自己的LDT。LDT的内存地址在LDTR寄存器中。
图7.1中的TI位,就是用来表示此索引所指向的段描述符是存于全局描述表中,还是本地描述表中。=0,表示用GDT,=1表示用LDT。
RPL位,占2bit,是保护信息位。
找到段描述符之后,加上偏移量,便是线性地址。转换过程如下图:

图7.2 逻辑地址转换为线性地址
7.3 Hello的线性地址到物理地址的变换-页式管理
线性地址即为CSAPP书中所说的虚拟地址,所以这里使用虚拟地址来描述
物理内存被划分为一小块一小块,每块被称为帧(Frame)。分配内存时,帧是分配时的最小单位,最少也要给一帧。在虚拟内存中,与帧对应的概念就是页(Page)。
线性地址的表示方式是:前部分是虚拟页号后部分是虚拟页偏移。
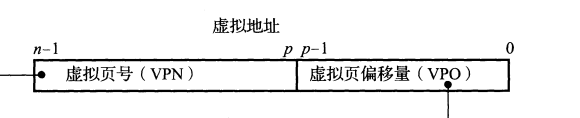
图7.3 虚拟地址的表示
CPU通过将逻辑地址转换为虚拟地址来访问主存,这个虚拟地址在访问主存前必须先转换成适当的物理地址。CPU芯片上叫做内存管理单元(MMU)的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址。然后CPU会通过这个物理地址来访问物理内存。
页表结构:在物理内存中存放着一个叫做页表的数据结构,页表将虚拟页映射到物理页,每次地址翻译硬件将一个虚拟地址转换为物理地址时,都会读取页表。
页表就是一个页表条目(PTE)数组,虚拟地址空间中的每个页在页表中的一个固定偏移量处都有一个PTE。PTE是由一个有效位和一个n个字段组成的。有效位表明了该虚拟页当前是否被缓存在DRAM中。如果设置了有效位,那么地址字段就表示DRAM中相应的物理页的起始位置。
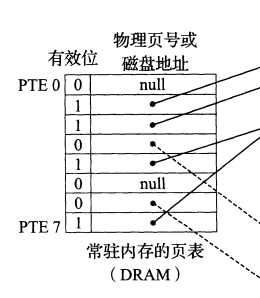
图7.4 页表结构

图7.5 虚拟地址到物理地址的翻译
如上图,MMU利用虚拟页号(VPN)来在虚拟页表中选择合适的PTE,当找到合适的PTE之后,PTE中的物理页号(PPN)和虚拟页偏移量(VPO)就会组合形成物理地址。其中VPO与PPO相同,因为虚拟页大小和物理页大小相同,所需要的偏移量位数也就相同。此时,物理地址就通过物理页号先找到对应的物理页,然后再根据物理页偏移找到具体的字节。
7.4 TLB与四级页表支持下的VA到PA的变换
TLB缓存了页表条目PTE,当需要进行地址翻译的时候,MMU先查询TLB,若是含有所需的PTE,则直接命中,否则MMU再从高速缓存中查找PTE。
从TLB中查询PTE的具体过程如下:

图7.6 虚拟地址访问TLB的解释
用于查询TLB所需要的组选择和行匹配的索引和标记字段是从虚拟地址中的虚拟页号提取出来的,若TLB有T=2^t个组,那么组索引就是VPN(虚拟页号)的低t位,其余位为TLB标记。当TLB不命中时,MMU必须从L1缓存中取出相应的PTE,如下图所示, 的PTE存放在TLB中,可能会覆盖一个已经存在的条目。

图7.7 TLB命中和不命中的操作图
多级页表用来压缩压缩页表,减少不必要的浪费,四级页表结构中,虚拟地址的36位VPN被划分成了四个9位的片,如下图,每个片被用作到一个页表的偏移量,CR3寄存器包含L1页表的物理地址。VPN1提供一个L1 PTE的偏移量,这个PTE包含L2页表的基地址。VPN2提供一个到L2PTE的偏移量,以此类推。

图7.8 四级页表下虚拟地址的翻译
下面将TLB和四级页表联合起来描述,虚拟地址是如何转换为物理地址的:
首先CPU计算出一个虚拟地址,将其传到MMU。MMU首先拿出虚拟地址的VPN查询TLB,若命中则直接将对应PTE中的物理页号与虚拟页偏移量组合起来形成物理地址,若没有命中。则去查询四级结构,查询方式上面已经介绍了。然后构造出物理地址,过程图如下:

图7.9 TLB和四级页表下的虚拟地址翻译
7.5 三级Cache支持下的物理内存访问

图7.10 三级cache支持下的物理访存

图7.11 cache组织结构
如图7.10是在三级cache支持下的物理访存情况,因为L2、L3和L1处理结果类似,所以这里只具体分析一级cache。因为一级cache为64组,8行,每行为64字节。所以组索引(CI)应该为log2(64)=6位,块内偏移(CO)也为6位,其余位为标记位(CT)。参看图7.11,首先根据组索引进行组选择,然后根据标记位来选择对应的行,若该行有效位为0,则表示miss即不命中,若有效位为1,则表示命中。不命中时,继续在L2cache查找,查找方法相同(可能组索引、行标记、块偏移的位数不同,依cache具体定),若找到了则要将其放进L1cache中。若L1cache中对于的组内有空闲的行,则直接放到该行内,否则要驱逐掉一行,有一种简单的策略是最不常用策略(LFU),它将会选择最近使用次数最少的一行替换掉。还有一种策略是最近最少使用策略(LRU),将会替换最后一次访问时间最久远的那一行。
7.6 hello进程fork时的内存映射
当fork函数被当前进程调用时,内核为新进程创建各种数据结构,并分配给它一个唯一的PID,为了给这个新进程创建虚拟内存,他创建了当前进程的mm_struct、区域结构和页表的原样副本。它将两个进程中的每个页面都标记为只读,并将两个进程中的每个区域结构都标记为私有的写时复制,当fork函数在新进程中返回时,新进程现在的虚拟内存刚好和调用fork时存在的虚拟内存相同。当这两个进程中的任一个后来进行写操作时,写时复制机制就会创建新页面,因此,也就为每个进程保持了私有地址空间的概念。
7.7 hello进程execve时的内存映射
execve函数在当前进程加载并运行包含在可执行目标文件hello中的程序,用hello程序有效地替代了当前程序。加载并运行hello需要以下几个步骤:
- 删除已存在的用户区域:删除当前进程虚拟地址的用户部分中已存在的区域结构。
- 映射私有区域:为新程序的代码、数据、bss和栈区域创建新的区域结构。所有这些新的区域都是私有的、写时复制的。代码和数据区域被映射为hello文件中的.text和.data区。bss区域是请求二进制零的,映射到匿名文件,其大小包含在hello中,栈和堆区域也是请求二进制零的,初始长度为零。图7.12概括了私有区域的不同映射。
- 映射共享区域:hello程序与共享对象链接,这些共享对象都是动态链接到这个程序的,然后再映射到用户虚拟地址空间中的共享区域内。
- 设置程序计数器(PC)。execve做的最后一件事就是设置当前进程上下文中的程序计数器,使之指向代码区域的入口点。下一次调度这个进程时,它将从这个入口点开始执行。Linux将根据需要换入代码和数据页面。
execve只是建立了映射关系,并未加载程序到物理内存中,当开始调度这个进程开始运行的时候,产生缺页故障,然后才会所需要的页面加载进去。

图 7.12加载器是如何映射用户地址空间的区域的
7.8 缺页故障与缺页中断处理
1.处理器生成一个虚拟地址,并把它传给MMU。
2.MMU生成PTE地址,并从高速缓存/主存中请求得到它。
3.高速缓存/主存向MMU返回PTE。
4. PTE中的有效位为0,那么此时MMU就触发了一次异常,传递CPU中的控制到操作系统内核中的缺页异常处理程序。缺页处理程序首先会对虚拟地址的合法性进行判断,即缺页处理程序搜素区域结构的链表,把该虚拟地址和每个区域结构中的vm_start和vm_end进行比较,若该虚拟地址没有在某个区域结构定义的区域内,那么将会触发一个段错误,进程终止。或者缺页是由对一个只有读权限的区域进行的写操作引起的,那么将会触发一个保护异常,从而终止这个进程。最后,若该虚拟地址时合法的,则继续下一步。如图7.14
5.缺页处理程序确定出物理内存中的牺牲页,如果这个页面已经被修改了,则把它交换出到磁盘。
6.缺页处理程序调入新的页面,并更新内存中的PTE。
7.缺页处理程序返回到原来的进程,再次执行导致缺页的指令。CPU将引起缺页的虚拟地址重新发送给MMU。因为虚拟页面现在缓存在物理内存中,所以就会命中,在MMU执行了图7.13中的步骤之后,主存就会将所请求字返回给处理器。

图7.13 缺页时的操作图

图7.14 缺页处理程序判断虚拟地址是否合法
7.9动态存储分配管理
printf会调用malloc,下面简述动态内存管理的基本方法与策略。
动态内存分配器维护着一个进程的虚拟内存区域,称为堆。假设堆是一个请求二进制零的区域,它紧接在未初始化的数据区域后开始,并向上生长(向更高的地址)。对于每个进程,内核维护着一个变量brk。它指向堆的顶部。
分配器将堆视为一组不同大小的块(block)的集合来维护。每个块就是一个连续的虚拟内存片,要么是已分配的,要么是空闲的。已分配的块显示地保留为供应用程序使用。空闲块可用来分配。空闲块保持空闲,直到它显示地被应用所分配。一个已分配的块保持已分配状态,直到它被释放,这种释放要么是应用程序显式执行的,要么是内存分配器自身隐式执行的。
分配器有两种分格:
- 显式分配器:要求应用显式地释放任何已分配的块。
- 隐式分配器:要求分配器检测一个已分配块何时不再被程序所使用,那么就释放这个块。隐式分配器也叫做垃圾收集器。
这里我们主要介绍一下带边界标签的隐式空闲链表分配器原理和带边界标签的显式空闲链表分配器原理。
隐式空闲链表:
1.空闲块的组织:
隐式空闲链表中,一个块是由一个字的头部、有效载荷、可能的一些额外的填充以及一个字的脚部组成的。32位中,块头部的高29位表示其块大小(末尾为3个0),最低位指明这个块是已分配的还是空闲的。其中有效载荷为用户申请的内存大小,填充是为了对齐,是可选择的。脚部为头部的一个副本。通过块头部或脚部就可以查找空闲块。
2.放置:
(1)首次适配:从头开始搜素空闲链表,选择第一个合适的空闲块。
(2)下一次适配:从上一次查询结束的地方开始搜素空闲链表,选择第一个合适的空闲块。
(3)最佳适配:检查每个空闲块,选择适合所需请求大小的最小空闲块。
3.分割空闲块:
若分割后剩余的块大于最小块,则进行分割,否则不进行分割。
4.合并:
(1)合并时间:立即合并和推迟合并。
立即合并:在每次一个块被释放时,就合并所有的相邻块
推迟合并:直到某个分配请求失败时,扫描整个堆,合并所有的空闲块。
(2)合并:(4种情况)
a.当前块前后的块都为已分配块:不需要合并
b.当前块后面的块为空闲块:用当前块和后面块的大小的和来更新当前块的头部和后面块的脚部。
c.当前块前面的块为空闲块:用当前块和前面块的大小的和来更新前面块 的头部和当前块的脚部。
d.当前块的前后块都为空闲块:用三个块大小的和来更新前面块的头部和 后面块的脚部。
其中,查询前面块的块大小时可以通过脚部来查,查询后面块的块大小时 可以通过头部来查。

图7.15 带边界标记的隐式空闲链表
显式空闲链表:
其基本原理与隐式空闲链表类似,其中不同的地方在于,除了用头部和脚部来标识块的大小和是否分配之外,内部还有两个指针,一个指向前驱节点,一个指向后继节点。如下图所示,其中pred指向前驱节点,succ指向后继节点
空闲块中含有指针,而分配块中无指针。
放置:每次通过指针来为malloc寻找空闲块,这样就不用每次都经过已分配的块来找下一个块,通过将某个空闲块前一个块和后一个块的指针连在一起,来删除空闲链表中所找到的适配的块。
释放:有两种方式将要free的块加入到空闲链表中,一种是LIFO,即每次都将释放的块插入到第一个块,这样操作时间短,但是会导致内存利用率低。还有一种是按地址顺序插进去,这样花费时间长一些,但是内存利用率接近最佳适配的利用率。

图7.16 使用双向链表的带边界标记的显式空闲链表
7.10本章小结
上章提到了计算机系统为了统一的管理程序,为程序提供了进程和虚拟内存的抽象,这一章就介绍了虚拟内存的实现,摘抄一句维基百科对虚拟内存的介绍:Virtual memory is the use of space on a hard disk drive (HDD) to simulate additional main memory.
虚拟内存使用硬盘的一部分来模拟主存,主存就是虚拟内存的一个cache,CPU寻址的时候首先会访问虚拟内存(使用页表来翻译成物理地址),若虚拟内存中的这个内容没有被缓存,那么就会触发一个缺页故障(miss),主存就会将这个内容从硬盘中拿出来,放到主存上。然后CPU重新访存,这就相当于CPU一直在CPU在主存中“取东西”(数据和指令),所以相当于虚拟内存也成了主存。为了更快的速度,CPU需要在主存上取东西的时候,也不是直接访问主存,而是先查看cache(查询页表先查询TLB,再查询cache)中有没有它想要的东西。由于局部性原理,这样使得CPU访存更快了。要执行一个新程序时,首先给新程序创建一个新进程(fork),创建新进程即就是复制一份父进程的各种的数据结构来表示它,这些数据结构中有可以表示虚拟内存的mm_struct、区域结构和页表等。加载可执行程序(execve),就是把在硬盘上的可执行文件的各个段映射到新进程的虚拟内存的各个段中,当CPU要执行的时候发现它还没有被缓存到主存上(缺页故障),此时就会将硬盘上的可执行文件复制到主存中,复制时是按页的大小来复制,需要哪一页就复制哪一页。动态分配就是将虚拟内存中的堆映射到一个匿名文件,当程序第一次要使用这个内存时,内核就会在主存中找到一个合适的牺牲页面,将其复制到硬盘中,将这块区域作为程序申请到的内存。
第8章 hello的IO管理
8.1 Linux的IO设备管理方法
设备的模型化:
一个Linux文件就是一个m个字节的序列:B0,B1,……,Bk,……,B(m-1)
所有的I/O设备(例如网络、磁盘和终端)都被模型化为文件,而所有的输入和输出都被当做对相应文件的读和写来执行。这种将设备优雅地映射为文件的方式,允许Linux内核引出一个简单、低级的应用接口,称为Unix I/O,这使得所有的输入和输出都能以一种同一且一致的方式来执行。
8.2 简述Unix IO接口及其函数
Unix I/O接口:
· 打开文件:一个应用程序通过要求内核打开相应的文件,来宣告它想要访问一个I/O设备。内核返回一个小的非负整数,叫做描述符,它在后续对此文件的所有操作中标识这个文件。内核记录有关这个打开文件的所有信息。应用陈谷只需记住这个描述符。
· Linux shell创建的每个进程开始时都有三个打开的文件:标准输入(描述符为0)、标准输出(描述符为1)和标准错误(描述符为2)。
· 改变当前的文件位置。对于每个打开的文件,内核保持着一个文件位置k,初始化为0.这个文件位置是从文件开头起始的字节偏移量。应用程序能够通过执行seek操作,显式地设置文件的当前位置为k。
· 读写文件:一个读操作就是从文件赋值n>0个字节到内存,从当前文件位置k开始,然后将k增加到k+n。给定一个大小为m字节的文件,当k>=m时执行读操作会触发一个称为EOF的条件,应用程序能检测到这个条件。写操作类似
· 关闭文件:当应用程序完成了对文件的访问之后,它就通知内核关闭这个文件。作为响应,内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池中。
I/O函数:
int open(char *filename, int flags, mode_t mode);
open函数将filename转换为一个文件描述符,并且返回描述符数字。返回的描述符总是在进程中当前没有打开的最小描述符。flags参数指明了进程打算如何访问这个文件,mode参数指定了新文件的访问权限。
ssize_t read(int fd, void *buf, size_t n);
read函数从描述符为fd的当前文件位置复制最多n个字节到内存位置buf。返回值-1表示一个错误,而返回值0表示EOF。否则,返回值表示的是实际传送的字节数量。
ssize_t write(int fd, void *buf, size_t n);
write函数从内存位置buf复制至多n个字节到描述符fd的当前文件位置。
8.3 printf的实现分析
先看printf的代码:
- int printf(const char *fmt, ...)
- {
- int i;
- char buf[256];
- va_list arg = (va_list)((char*)(&fmt) + 4);
- i = vsprintf(buf, fmt, arg);
- write(buf, i);
- return i;
- }
参数列表中的“...”表示不定长参数。代码中arg就是获取不定长阐述列表的首地址,因为C语言参数压栈的方式是从右往左,并且栈是从高地址向低地址生长的,而fmt为字符指针,在32位系统中,其大小为4字节,所以&fmt+4就为...中的第一个参数地址。再看vprintf函数。
- int vsprintf(char *buf, const char *fmt, va_list args)
- {
- char* p;
- char tmp[256];
- va_list p_next_arg = args;
- for (p=buf;*fmt;fmt++) { //将p赋值为buf,即之后用p构造buf内容
- if (*fmt != '%') { //%为格式控制符,若不为%则直接复制到buf中,然后continue
- *p++ = *fmt;
- continue;
- }
- fmt++;
- switch (*fmt) { //若为%则判断%之后的字符
- case 'x': //为x,则将不定长参数中的第一个参数解释为int型,并将其复制到buf中
- itoa(tmp, *((int*)p_next_arg));
- strcpy(p, tmp);
- p_next_arg += 4; //p_next_arg指向下一个参数
- p += strlen(tmp); //p指向第一个格式化之后的字符地址
- break;
- case 's': //若为s则break
- break;
- default:
- break;
- }
- }
- return (p - buf);
- }
给vprintf输入格式控制串和参数列表,它会构造出我们最终要输出的字符串buf。并返回字符串的长度i。
在hello程序中,这一步将会构造出“Hello 1170301004 wanghang”
接着再看write函数 write(buf, i);
- write:
- mov eax, _NR_write
- mov ebx, [esp + 4]
- mov ecx, [esp + 8]
- int INT_VECTOR_SYS_CALL
这段汇编是intel格式的,给寄存器传递了几个参数,
int INT_VECTOR_SYS_CALLA代表通过系统调用syscall
- sys_call:
- call save
- push dword [p_proc_ready]
- sti
- push ecx
- push ebx
- call [sys_call_table + eax * 4]
- add esp, 4 * 3
- mov [esi + EAXREG - P_STACKBASE], eax
- cli
- ret
call save,是为了保存中断前进程的状态
ecx中是要打印出的元素个数
ebx中的是要打印的buf字符数组中的第一个元素
这个函数的功能就是不断的打印出字符,直到遇到:'\0'
通过字符显示驱动子程序把字符的ASCII存到显示vram(存储每一个点的RGB颜色信息)上,然后显示芯片按照刷新频率逐行读取vram,并通过信号线向液晶显示器传输每一个点(RGB分量),最后“Hello 1170301004 wanghang”就被输出到屏幕上了。
8.4 getchar的实现分析
异步异常-键盘中断的处理:用户从键盘输入,触发了一个中断信号,当前进程被抢占,进而开始执行键盘中断处理子程序。键盘中断处理子程将输入的字符序通过按键扫描码转成ascii码,保存到系统的键盘缓冲区。
getchar底层实现使用了read系统函数,通过系统调用来触发一个中断信号,执行一次上下文切换,当前进程被挂起CPU去执其他进程,read读取按键ascii码,直到接受到回车键才返回,当read函数返回时,当前进程重新被调度,getchar获得输入的第一个字符。
8.5本章小结
还是那句话,一个系统想要高效的运行,必须建立一个简单有效的模型。我们在linux 的I/O管理中又看到了这一点。linux把所有的设备都模型化成了文件,这样就能用一致的一些操作来管理各种设备:打开文件、读取文件、向文件写入、关闭文件等等一系列操作。
(第8章1分)
结论
hello所经历的过程:
- 编写: 通过编辑器输入hello.c的C语言代码
- 预处理:预处理器对hello.c处理生成hello.i文件
- 编译: 编译器编译hello.i将其转化成汇编语言描述的hello.s文件
- 汇编: 汇编器将hello.s文件翻译成可重定位文件hello.o
- 链接: 链接器将hello.o和其他目标文件进行链接,生成可执行文件hello
- 运行: 在shell中输入./hello 1170301004 wanghang,开始运行hello程序
- 创建新进程:shell为hello程序fork一个新进程
- 加载: 在新进程中调用execve函数,将hello程序映射到虚拟内存中
- 执行: 内核调度该进程执行,进行虚拟地址的翻译,此时会发生缺页, 开始加载hello代码和数据到对应的物理页中,然后开始执行。
- 信号处理:在hello进程运行中,按下ctrl+z、ctrl+c等将会发送信号给hello,
进而调用信号处理程序进行处理。
- 终止: 输出完10遍对应的字符串后,执行getchar,等待用户输入,输 入字符按下回车后,hello进程终止。
- 回收: hello进程终止后发送SIGCHLD信号给shell,shell将其退出状态 进行回收,最后内核从系统中删除hello所有的信息。
感想:感受到了计算机系统的复杂。并且懂得了要想构建一个行之有效的系统,对每个部分进行抽象是非常重要的,它能让系统使用一些一致的操作来对系统中的每个任务进行有效的管理。子系统的局部优化也很重要,它能够让整个系统运行的更快。
附件
| 文件名 |
描述 |
| hello.c |
源代码 |
| hello.i |
预处理之后的文件 |
| hello.s |
编译之后的文件 |
| hello.o |
汇编之后的文件 |
| hello_rel.s |
hello.o反汇编代码 |
| hello |
链接之后的可执行文件 |
| hello_obj.s |
hello的反汇编代码 |
(时间有些仓促,不排除存在一些小错误的可能)
参考文献
[1] C语言真正的编译过程:https://blog.csdn.net/qq_29924041/article/details/54917521
[2] 可执行文件(ELF)格式的理解:http://www.voidcn.com/article/p-nucnoizt-pz.html
[3] linux下动态链接实现原理:https://www.cnblogs.com/catch/p/3857964.html.
[4] 虚拟地址、逻辑地址、线性地址、物理地址:https://blog.csdn.net/rabbit_in_android/article/details/49976101
[5] [转]printf 函数实现的深入剖析:https://www.cnblogs.com/pianist/p/3315801.html
[6] Randal E.Bryant,David R. O’Hallaron, 深入了解计算机系统:工业出版社,2016.