1.条件查询
使用where子句对表中的数据筛选,结果为true的行会出现在结果集中。
select * from 表名 where 条件;
- 比较运算符
等于=,大于>,大于等于>=,小于<,小于等于<=,不等于!=
查询id>2的学生

- 逻辑运算符,and 、or、not。
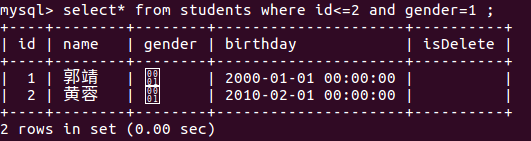
- 模糊查询
模糊查询关键字like,%表示任意多个任意字符,_表示一个任意字符。

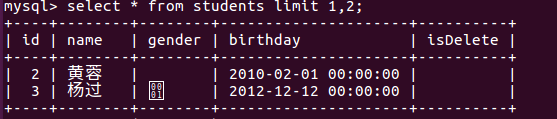
- 范围查询
- in表示一个非连续的范围内查询
- between ... and ...表示在一个连续的范围内


- 优先级
- 小括号>not>比较运算符>逻辑运算符
- and比or先运算,如果同时出现并希望先算or,需要结合()使用
2.聚合
为了快速得到统计数据,提供了5个聚合函数。
- count(*)表示计算总行数,括号中写星与列名,结果是相同的
- max(列)表示求此列的最大值
- min(列)表示求此列的最小值
- sum(列)表示求此列的和
- avg(列)表示求此列的平均值
查询id最小值得学生,并显示这个id具体信息:

聚合查询只能查询一个结果,所以需要嵌套一个子查询。
3.分组
按照字段分组,表示此字段相同的数据会被放到一个组中;分组后,只能查询出相同的数据列,对于有差异的数据列无法出现在结果集中;可以对分组后的数据进行统计,做聚合运算。分组的目的是为了更好的聚合。
select 列1,列2,聚合... from 表名 group by 列1,列2,列3...

对分组后的数据筛选。where是对from后面指定的表进行数据筛选,属于对原始数据的筛选;having是对group by的结果进行筛选。

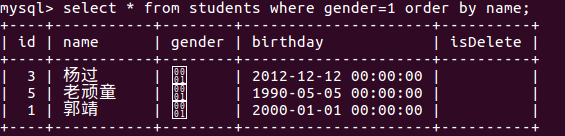
4.排序
为了方便查看数据,对数据进行排序。asc从小到大排列,即升序;desc从大到小排序,即降序。
select * from 表名 order by 列1 asc|desc,列2 asc|desc,...
5.分页
当数据量过大时,需要分页显示。一次性加载太多数据加大了服务器内存负载;网络中传输的数据过大;同是对用户游览器加载也是一个考验。
select * from 表名 limit start,count
从start开始,获取count条数据start索引从0开始。