6、Spark 的基本使用
6.1、执行第一个 Spark 程序
利用 Spark 自带的例子程序执行一个求 PI(蒙特卡洛算法)的程序:
$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop02:7077 \
--executor-memory 512m \
--total-executor-cores 2 \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar \
100
6.2、启动 Spark Shell
启动命令:
$SPARK_HOME/bin/spark-shell \
--master spark://hadoop02:7077,hadoop04:7077 \
--executor-memory 512M \
--total-executor-cores 2

注意上图中的 cores 参数,是 0,那么以后这个 spark shell 中运行的代码是不能执行成功的。
千万注意。必要要把 cpu cores 和 memory 设置合理
1、 executor memory 不能超过虚拟机的内存
2、 cpu cores 不要超过 spark 集群能够提供的总 cpu cores,否则会使用全部。最好不要使用 全部。否则其他程序由于没有 cpu core 可用,就不能正常运行
参数说明:

--master spark://hadoop02:7077 指定 Master 的地址
--executor-memory 2G 指定每个 worker 可用内存为 2G
--total-executor-cores 2 指定整个集群使用的 cup 核数为 2 个
注意: 如果启动 spark shell 时没有指定 master 地址,但是也可以正常启动 spark shell 和执行 spark shell 中的程序,其实是启动了 spark 的 local 模式,该模式仅在本机启动一个进程,没有与 集群建立联系。
Spark-2.X:
Spark Shell 中已经默认将 SparkContext 类初始化为对象 sc。 Spark Shell 中已经默认将 SparkSession 类初始化为对象 spark。 用户代码如果需要用到,则直接应用 sc,spark 即可
Spark-1.X:
Spark Shell 中已经默认将 SparkContext 类初始化为对象 sc。 Spark Shell 中已经默认将 SQLContext 类初始化为对象 sqlContext。 用户代码如果需要用到,则直接应用 sc,sqlContext 即可

6.3、在 Spark Shell 中编写 WordCount 程序
在提交 WordCount 程序之前,先在 HDFS 集群中的准备一个文件用于做单词统计:
words.txt 内容如下:
hello huangbo
hello xuzheng
hello wangbaoqiang把该文件上传到 HDFS 文件系统中:
[hadoop@hadoop05 ~]$ hadoop fs -mkdir -p /spark/wc/input
[hadoop@hadoop05 ~]$ hadoop fs -put words.txt /spark/wc/input在 Spark Shell 中提交 WordCOunt 程序:
sc.textFile("hdfs://myha01/spark/wc/input/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://myha01/spark/wc/output")
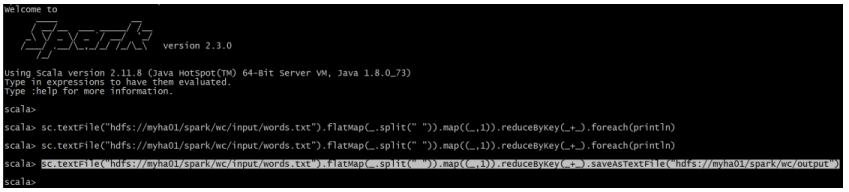
执行最后的结果:

说明:
sc 是 SparkContext 对象,该对象时提交 spark 程序的入口 textFile("hdfs://myha01/spark/wc/input/words.txt")是从 HDFS 中读取数据 flatMap(_.split(" "))先 map 再压平 map((_,1))将单词和 1 构成元组(word,1) reduceByKey(_+_)按照 key 进行 reduce,并将 value 累加 saveAsTextFile("hdfs://myha01/spark/wc/output")将结果写入到 HDFS 对应输出目录中
6.4、在 IDEA 中编写 WordCount 程序
Spark Shell仅在测试和应用我们的程序使用的比较多,在生产环境中,通常会在IDEA中编译程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖
1、创建一个IDEA的Maven项目

2、选择 Maven 项目,然后点击 next

3、填写 maven 的 GAV,然后点击 next

4、填写项目名称,然后点击 finish

5、创建好 maven 项目后,点击 Enable Auto-Import

6、配置 maven 的 pom.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.mazh.spark</groupId>
<artifactId>Spark_WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.3.0</spark.version>
<hadoop.version>2.7.5</hadoop.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<v ersion>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>7、将 src/main/java 和 src/test/java 分别修改成 src/main/scala 和 src/test/scala,与 pom.xml 中的配置保持一致

8、新建一个 Scala Class 类型为 Object,编写 WordCount 程序
package com.mazh.spark
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 创建一个 SparkConf 对象,并设置程序的名称
val conf = new SparkConf().setAppName("WordCount")
// 创建一个 SparkContext 对象
val sc = new SparkContext(conf)
// 读取 HDFS 上的文件构建一个 RDD
val fileRDD = sc.textFile(args(0))
// 构建一个单词 RDD
val wordAndOneRDD = fileRDD.flatMap(_.split(" ")).map((_, 1))
// 进行单词的聚合
val resultRDD = wordAndOneRDD.reduceByKey(_+_)
// 对 resultRDD 进行单词出现次数的降序排序,然后写出结果到 HDFS
resultRDD.sortBy(_._2, false).saveAsTextFile(args(1))
sc.stop()
}
}
9、使用 maven 进行打包 点击右侧的 maven project 选项。先点击 clean 再点击 package 进行打包

10、启动 HDFS 集群和 Spark 集群
11、上传打好的 jar 包到 spark 集群中的用来提交任务的节点
put c:/Spark_WordCount-1.0-SNAPSHOT.jar
执行命令:
$SPARK_HOME/bin/spark-submit \
--class com.mazh.spark.WordCount \
--master spark://hadoop02:7077 \
--executor-memory 512m \
--total-executor-cores 4 \ /home/hadoop/Spark_WordCount-1.0-SNAPSHOT.jar \ hdfs://myha01/spark/wc/input \
hdfs://myha01/spark/wc/output_11
