2016年09月19日 18:27:47 jiewuyou 阅读数:1224 标签: spark 更多
个人分类: 云计算
所属专栏: spark私房菜
本文将介绍spark的几种运行方式,及常用的参数
yarn cluster模式
例行任务一般会采用这种方式运行
指定固定的executor数
作业常用的参数都在其中指定了,后面的运行脚本会省略
spark-submit \
--master yarn-cluster \
--deploy-mode cluster \ #集群运行模式
--name wordcount_${date} \ #作业名
--queue production.group.yanghao \ #指定队列
--conf spark.default.parallelism=1000 \ #并行度,shuffle后的默认partition数
--conf spark.network.timeout=1800s \
--conf spark.yarn.executor.memoryOverhead=1024 \ #堆外内存
--conf spark.scheduler.executorTaskBlacklistTime=30000 \
--conf spark.core.connection.ack.wait.timeout=300s \
--num-executors 200 \ #executor数目
--executor-memory 4G \ #executor中堆的内存
--executor-cores 2 \ #executor执行core的数目,设置大于1
--driver-memory 2G \ #driver内存,不用过大
--class ${main_class} \ #主类
${jar_path} \ #jar包位置
param_list \ #mainClass接收的参数列表动态调整executor数目
spark-submit \
--master yarn-cluster \
--deploy-mode cluster \
--name wordcount_${date} \
--queue production.group.yanghao \
--conf spark.dynamicAllocation.enabled=true \ #开启动态分配
--conf spark.shuffle.service.enabled=true \ #shuffle service,可以保证executor被删除时,shuffle file被保留
--conf spark.dynamicAllocation.minExecutors=200 \ #最小的executor数目
--conf spark.dynamicAllocation.maxExecutors=500 \ #最大的executor数目
--class ${main_class} \
${jar_path} \
param_list- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
yarn client模式
边写脚本,边在集群上运行。这样调试会很方便
spark-shell \
--master yarn-client \
--queue production.group.yanghao \ #指定队列
--num-executors 200 \ #executor数目
--executor-memory 4G \ #executor中堆的内存
--executor-cores 2 \ #executor执行core的数目,设置大于1
--driver-memory 2G \ #driver内存,不用过大
--jars ${jar_path} #jar包位置- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
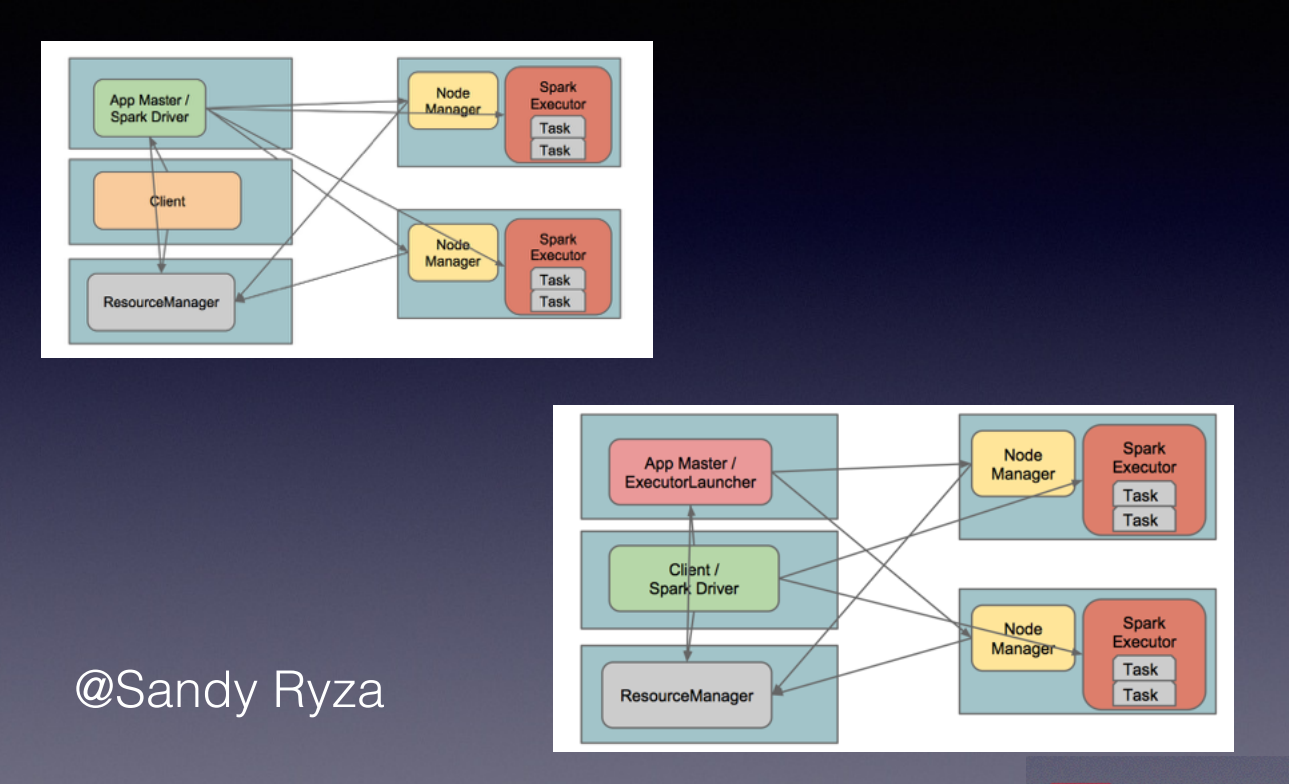
yarn cluster模式 vs yarn client模式
yarn cluster模式:spark driver和application master在同一个节点上
yarn client模式:spark driver和client在同一个节点上,支持shell
参考
http://stackoverflow.com/questions/21138751/spark-java-lang-outofmemoryerror-java-heap-space
扫描二维码关注公众号,回复:
4823541 查看本文章
