【论文阅读】Beyond Short Snippets: Deep Networks for Video Classification
之前3DCNN网络的论文算是记录完了,虽然最近又出了几篇,但是时间有限,很快要去实习去了,剩下的以后有时间再讲吧。
本篇论文算是CNN+LSTM网络结构的开山之作,其实对于视频分析和行为识别这个任务目标,我们自然而然地想到的就是CNN+LSTM这种网络结构,简洁优雅,至于为什么这种方法没有达到理想中的结果,我们会根据之后的改进论文去进一步分析
论文地址:下载地址
代码地址(pytorch):下载地址
正文
这篇论文是15年的论文,很早了,当时3DCNN方法还是受限于数据集太小,所以主流的方法还是CNN+时间建模的方法,所以本文的作者实验了 CNN+时间池化 和CNN+LSTM两种方法,因为这篇博客主要是记录CNN+LSTM方法的,所以本文中的CNN+时间池化的方法就顺便一提。
CNN+时间池化的方法
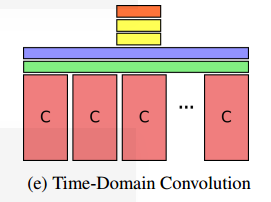
当时时间池化的方法一般包含平均池化、加权平均池化、最大池化。但是本文通过实验发现还是最大池化的效果比较好,所以本文中所有池化的方法都是最大池化。本文设计了五种CNN+池化的网络结构,每一种都有不同的特点,通过分析不同的网络结构也可以了解作者的思考方式,也是有益处的。五种网络结构如下所示:(下图中砖色是卷积层,蓝色是最大池化层,绿色是时域卷积层,黄色全连接层,橘色softmax层)
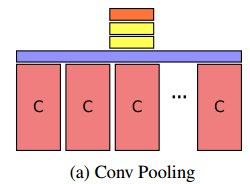
- Conv Pooling:第一种结构称为卷积-池化结构,其在卷积层的输出增加一个最大池化层,然后再连接两个全连接层,这种网络结构的特点是 因为卷积网络输出的卷积特征图都会保持其输入的空间结构,即卷积特征图的响应值与其感受野是相互对应的。所以通过最大池化可以沿着时间保留其空间信息。
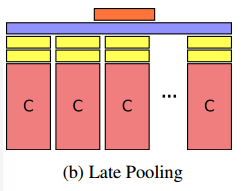
- Late Pooling:第二种结构称为滞后池化结构,这种结构首先将每一帧计算的卷积特征图通过两个全连接层,然后对全连接层的输出沿着时间最大池化,这种网络结构与Conv Pooling结构相比,不会保留池化前特征的空间结构,而是直接组合高维抽象特征的时间动态。
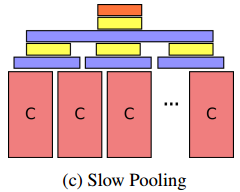
- Slow Pooling:第三种结构称为慢速池化结构,这种结构使用一个时间窗口分级地组合输入中的时间信息,对于卷积网络的输出,首先使用滑动窗口最大池化组合输入的局部时间信息,然后对每个局部时间组合连接全连接层,再对全连接层的输出结果通过最大池化组合全部的局部运动信息,最后通过全连接层获得最终的结果。这种网络结构的特点是在组合高维抽象的特征之前,可以先组合局部的时间运动信息。
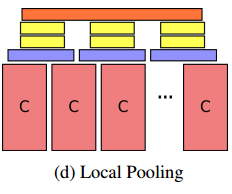
- Local Pooling:第四种结构称为局部池化结构,这种结构和Slow Pooling很像,对于卷积网络的输出,首先使用滑动窗口最大池化组合输入的局部时间信息,然后对每个局部运动特征连接两个全连接层直接获得抽象局部运动特征。这种网络结构与Slow Pooling的不同点在于该网络结构不会组合输入的全局运动信息,从而减少了时间信息的丢失(因为每一次时间池化都会丢失一定的时间信息)。
- Time-Domain Convolution:第五种结构称为时域卷积结构,这种结构与前边的四种结构相比多了一层时间卷积层,相当于在Conv Pooling结构的最大池化层之前增加一层时间卷积层。这种结构的特点是因为增加了时间卷积层,所以可以在最大池化层之前组合更短时局部的时间信息。
CNN+LSTM的方法
总算要介绍CNN+LSTM的方法了,因为是第一次介绍CNN+LSTM的论文,所以我就先详细地介绍一下RNN和LSTM的基础(大神请跳过),然后再详细地介绍本文中的CNN+LSTM的网络结构。
RNN和LSTM的基础讲解
循环神经网络RNN是用来对时间序列数据进行建模的,该网络结构会对前面的输入信息进行记忆,并结合当前的输入,计算出当前的输出。其非展开结构与展开后的结构如下图所示:
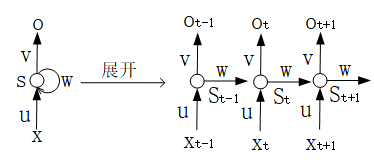
根据上图可以得到如下公式:
上式展开之后如下式所示,就能看到为什么说当前的输出会受到前面时刻输入的影响了。
LSTM 网络结构要比RNN复杂一些,但是万变不离其中,结构图太难画了,latex公式也太难打了,我直接把结构图和公式图片贴上了。LSTM的结构图如下图所示:

LSTM主要通过3个门来控制信息流,(3)是输入门,(4)是遗忘门,(6)是输出门,(5)是用来保存历史信息的cell,还是挺好理解的。
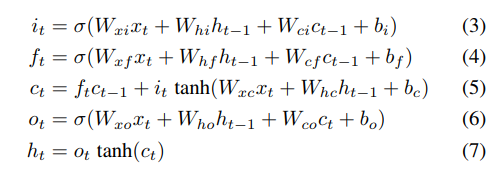
CNN+LSTM网络结构
文章中的CNN+LSTM结构中使用的是5层的LSTM网络,每一层包含512个记忆单元,最顶层连接softmax层用于分类,其结构如下图所示,也是很好理解的:

训练细节
CNN为AlexNet和GoogLeNet,在ImageNet上提前预训练。CNN和池化或者LSTM的训练是分开的,先使用单帧训练CNN,LSTM的每一个时刻的输出都计算损失,同时也加入光流作为输入,光流在15fps的视频中计算,首先筛选出数值在[-40,40]的光流,然后将其归一化到[0,255],第三个通道全部设置为0。
实验结果
挑选了一些有意思的实验。
五种卷积+池化网络结构的实验结果对比
文章首先实验了5种卷积+池化的网络结构,实验结果如下图所示:
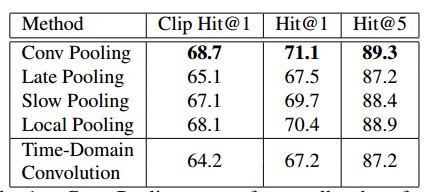
由上图可以看到实验效果最好的还是Conv Pooling。
输入视频帧长对实验结果的影响
文章同时实验了输入帧长变化对实验结果的影响,如下图所示:
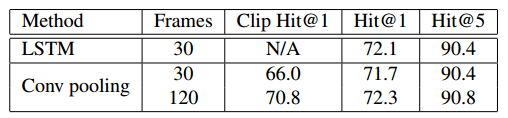
文章只在 conv pooling 网络结构上做了对比实验,可以看到随着输入帧长的增加,clip 和 video 的准确率都是提高的,这和3D卷积网络中的 LTC的结论差不多:输入较长时间的视频训练可以得到更好的效果。
其他的实验就不说了。