通过《深入理解JAVA虚拟机》和《深入理解计算机系统》两本经典著作的学习,注重了解系统进程运行时内存结构的变化,以此彻底了解JVM虚拟机在运行JAVA程序时的内存结构!
主要有三个方面:
1、计算机系统的内部系统结构;
2、JVM运行时数据内存结构;
3、通过简单的JAVA程序彻底理解JVM执行流程。
一、计算机系统的内部系统结构
先看一张图,有个大体印象:
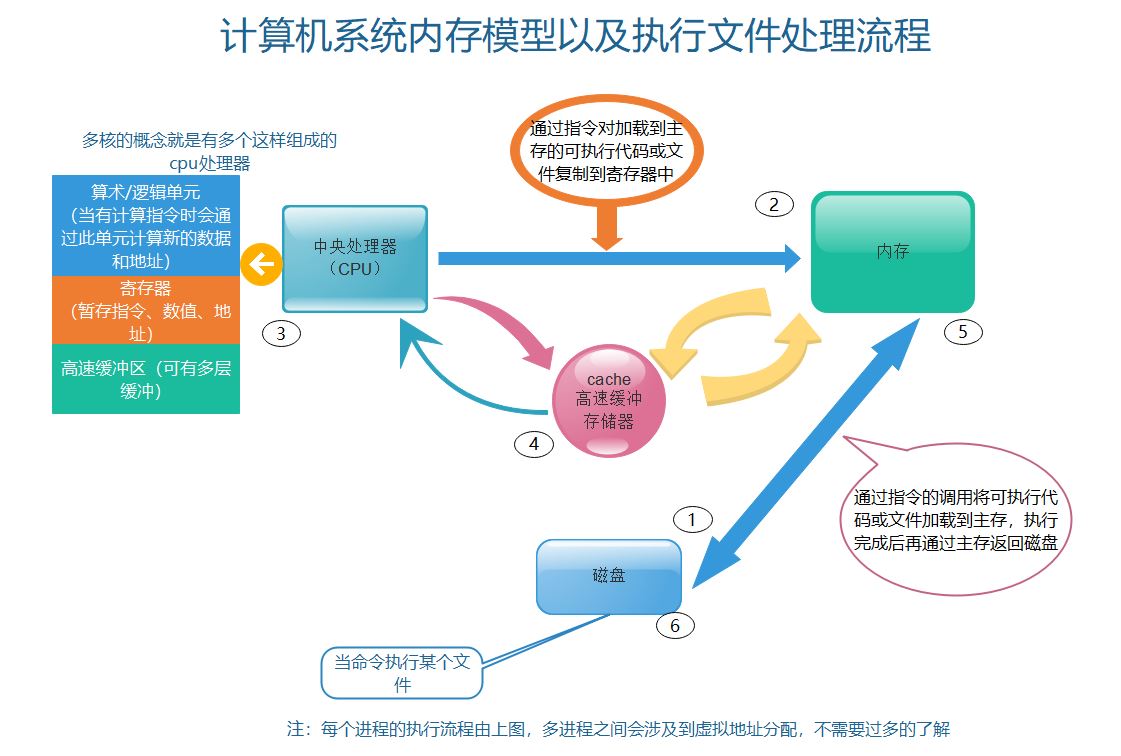
首先,要记住的是,一系列语言的的源文件保存在磁盘上,通过解释器解释后成可执行文件,也保存在磁盘上。
下面举个简单的例子,下面有一段简单的C程序,保存为hello.c:
#include <stdio.h>
int main()
{
printf("hello,world!");
return 0;
}C语言程序的设计是用来实现Unix操作系统的,那么就可以直接在linux的shell指令进行编译:
[root@localhost lgy] gcc -o hello hello.c上面命令的意思就是通过GCC编译器将hello.c源文件编程成文件名为hello的可执行文件。
[root@localhost lgy] ./hello上面命令回车后,发生了下面的流程:
1、通过指令将hello文件中的代码和数据复制到了主存
2、当处理器发现执行文件加载到了主存后,就处理器就会执行主存代码中的main程序,将主存的main程序中的字节复制到了处理器的寄存器中(如果代码中涉及到数据的运算,就会拷贝数据到算术/逻辑单元,计算完之后就会将数据返回寄存器)
3、寄存器执行完命令之后再将数据复制到界面。
这里,我们又会发现一个问题,就是简单的一个程序处理,涉及到了多次的复制,特别是在处理器与主存之间,当我们的程序中设计到函数的调用,结果再次返回主存,下次我们获取还得从主存复制到寄存器,就这影响了性能,这就出现了高速缓存。
高速缓存被设计在处理器中的一个部件,假如我们用的多核处理器,那么就意味着每核处理器里面都包含了寄存器、算术单元、高速缓存等组件。
以上就是计算机系统执行一个可执行文件的整个流程,对于我们Java攻城狮来说,对其有个大概的了解就可以了,其中具体的指令操作,内存分配等,不是那么重要,当然兴趣是最好的老师,下面的JVM才是我们必须彻底了解的一块。
二、JVM运行时数据内存结构;
通过一张JVM运行时内存结构图,有个大致的印象:
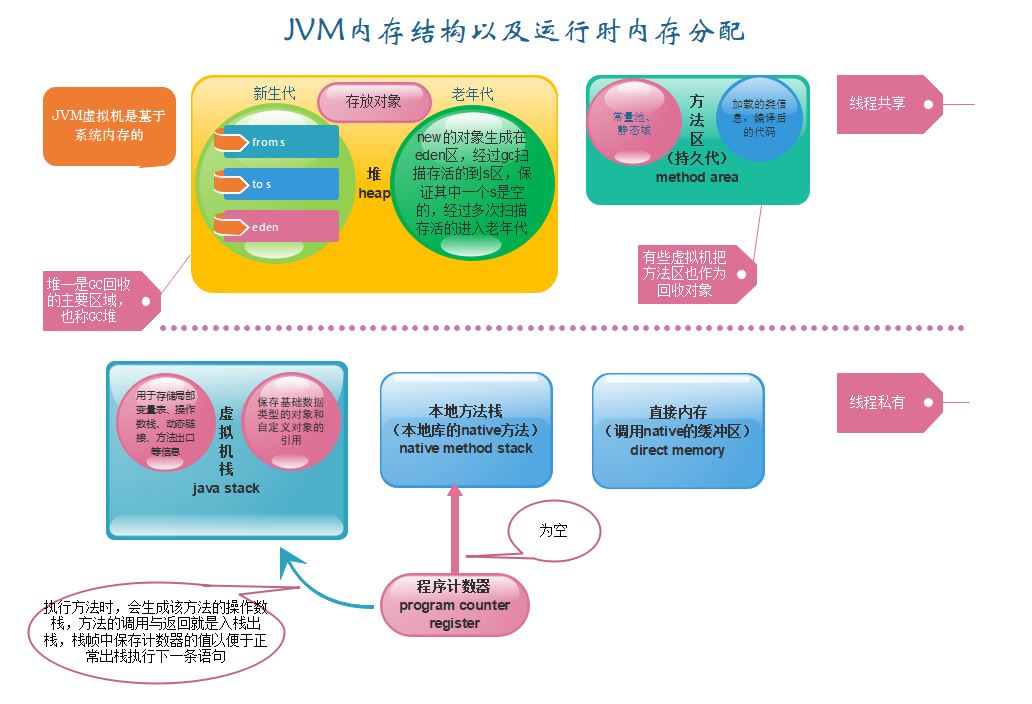
JVM运行时内存主要分有五块区域:
堆,方法区---------------------线程共享区域
虚拟机栈、本地方法栈、(直接内存)-------------------线程私有区域
简单分解概念:
程序计数器:是一块很小的内存空间,可以看作当前线程所执行的字节码位置指示灯。这里只需要知道,程序中所出现的分支、循环、跳转(方法调用)、异常处理、线程恢复等基础功能都依赖它。如图,可以看到它在支配着两个栈的计数,如果线程中执行一个Java方法,计数器就会记录正在执行的字节码指令的位置,若是执行的Native方法,计数器的值就是空的。
虚拟机栈:生命周期同线程。每个方法在执行的时候都会创建一个栈帧用来存储局部变量表、操作数栈、动态链接、方法出口等信息。其中,局部变量表存放的是编译器可知的基本数据类型,有int,short,byte,long,float,char,boolean,double,还有对象引用的类型。
本地方法栈:顾名思义,就是Java程序内部调用Native属性的方法所占用的内存空间。
Java堆:很显然,栈中存放的是对象的引用,堆里就存放了对象实例本身(作为了解,有些编译器也不是这么绝对)。堆中重点需要了解的是GC垃圾回收机制。
方法区:主要用于存储已被虚拟机加载过的类信息、常量、静态变量、即时编译器编译后的代码等数据。这个区域也被垃圾回收机制成为持久代,主要是对常量池中数据的回收和对类的卸载。
方法区中需要了解的是常量池,例如,public String s = "abc",那么“abc”和其符号引用就保存在常量池
直接内存:主要用于NIO,可以使用Native函数库直接分配堆外内存,存放这Java堆中的DirectByteBuffer对象的引用。
建议推荐https://blog.csdn.net/fuzhongmin05/article/details/78169044
概念的东西都讲完了,下面的就是重点了。
三、通过简单的JAVA程序彻底理解JVM执行流程。
一个Person类:
public class Person {
private String name;
private static String stat = "0";
private static final int index = 1;
public void work(){
String address = "renminlu";
int day = 0;
while(day < 365){
day ++ ;
}
System.err.println(address);
}
public static void main(String[] args) {
Person person = new Person();
person.work();
assert args.length < 0;
Integer i = 122;
Integer j = 122;
System.err.println(i == j);
}
}在这个类里面我们定义了一个普通属性name,一个静态属性stat并初始化“0”,一个static final修饰的属性index。
整个程序编译的过程如下图(网上摘抄):
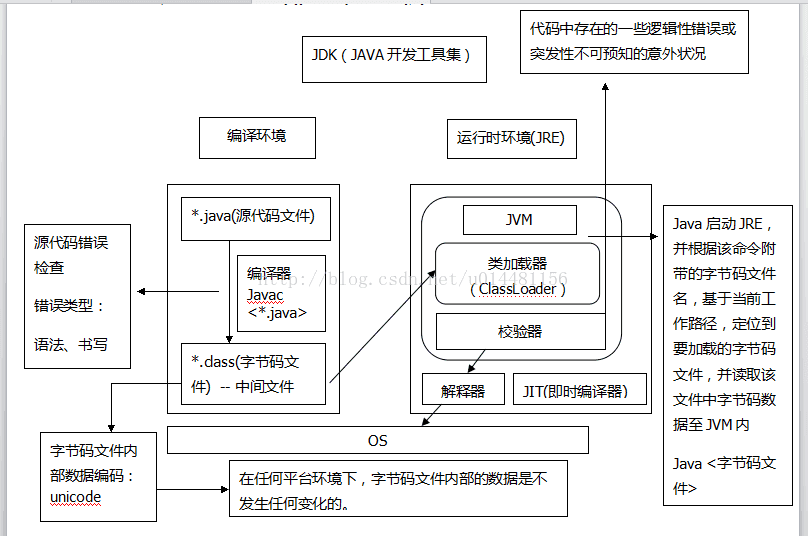
主要看其运行时数据的内存分配:
打开Person所在目录,执行:
javac Person.javajavap -v -c -l Person最后汇总一下JVM常见配置
- 堆设置
- -Xms:初始堆大小
- -Xmx:最大堆大小
- -XX:NewSize=n:设置年轻代大小
- -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
- -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
- -XX:MaxPermSize=n:设置持久代大小
- 收集器设置
- -XX:+UseSerialGC:设置串行收集器
- -XX:+UseParallelGC:设置并行收集器
- -XX:+UseParalledlOldGC:设置并行年老代收集器
- -XX:+UseConcMarkSweepGC:设置并发收集器
- 垃圾回收统计信息
- -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps
- -Xloggc:filename
- 并行收集器设置
- -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
- -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
- -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
- 并发收集器设置
- -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
- -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。