考虑到一些朋友对鄙人的性别判断方法感兴趣,而自己的代码又没妥善保存,因此特在这里进行弥补,将作业报告PPT内容公布,并进行简单地代码说明,希望对感兴趣的童鞋能有所帮助。

















代码:
代码主要根据opencv\modules\contrib\doc\facerec\src\facerec_fisherfaces.cpp来讲解,源代码内容如下:
/*
* Copyright (c) 2011. Philipp Wagner <bytefish[at]gmx[dot]de>.
* Released to public domain under terms of the BSD Simplified license.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of the organization nor the names of its contributors
* may be used to endorse or promote products derived from this software
* without specific prior written permission.
*
* See <http://www.opensource.org/licenses/bsd-license>
*/
#include "opencv2/core/core.hpp"
#include "opencv2/contrib/contrib.hpp"
#include "opencv2/highgui/highgui.hpp"
#include <iostream>
#include <fstream>
#include <sstream>
using namespace cv;
using namespace std;
static Mat norm_0_255(InputArray _src) {
Mat src = _src.getMat();
// Create and return normalized image:
Mat dst;
switch(src.channels()) {
case 1:
cv::normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC1);
break;
case 3:
cv::normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC3);
break;
default:
src.copyTo(dst);
break;
}
return dst;
}
static void read_csv(const string& filename, vector<Mat>& images, vector<int>& labels, char separator = ';') {
std::ifstream file(filename.c_str(), ifstream::in);
if (!file) {
string error_message = "No valid input file was given, please check the given filename.";
CV_Error(CV_StsBadArg, error_message);
}
string line, path, classlabel;
while (getline(file, line)) {
stringstream liness(line);
getline(liness, path, separator);
getline(liness, classlabel);
if(!path.empty() && !classlabel.empty()) {
images.push_back(imread(path, 0));
labels.push_back(atoi(classlabel.c_str()));
}
}
}
int main(int argc, const char *argv[]) {
// Check for valid command line arguments, print usage
// if no arguments were given.
if (argc < 2) {
cout << "usage: " << argv[0] << " <csv.ext> <output_folder> " << endl;
exit(1);
}
string output_folder;
if (argc == 3) {
output_folder = string(argv[2]);
}
// Get the path to your CSV.
string fn_csv = string(argv[1]);
// These vectors hold the images and corresponding labels.
vector<Mat> images;
vector<int> labels;
// Read in the data. This can fail if no valid
// input filename is given.
try {
read_csv(fn_csv, images, labels);
} catch (cv::Exception& e) {
cerr << "Error opening file \"" << fn_csv << "\". Reason: " << e.msg << endl;
// nothing more we can do
exit(1);
}
// Quit if there are not enough images for this demo.
if(images.size() <= 1) {
string error_message = "This demo needs at least 2 images to work. Please add more images to your data set!";
CV_Error(CV_StsError, error_message);
}
// Get the height from the first image. We'll need this
// later in code to reshape the images to their original
// size:
int height = images[0].rows;
// The following lines simply get the last images from
// your dataset and remove it from the vector. This is
// done, so that the training data (which we learn the
// cv::FaceRecognizer on) and the test data we test
// the model with, do not overlap.
Mat testSample = images[images.size() - 1];
int testLabel = labels[labels.size() - 1];
images.pop_back();
labels.pop_back();
// The following lines create an Fisherfaces model for
// face recognition and train it with the images and
// labels read from the given CSV file.
// If you just want to keep 10 Fisherfaces, then call
// the factory method like this:
//
// cv::createFisherFaceRecognizer(10);
//
// However it is not useful to discard Fisherfaces! Please
// always try to use _all_ available Fisherfaces for
// classification.
//
// If you want to create a FaceRecognizer with a
// confidence threshold (e.g. 123.0) and use _all_
// Fisherfaces, then call it with:
//
// cv::createFisherFaceRecognizer(0, 123.0);
//
Ptr<FaceRecognizer> model = createFisherFaceRecognizer();
model->train(images, labels);
// The following line predicts the label of a given
// test image:
int predictedLabel = model->predict(testSample);
//
// To get the confidence of a prediction call the model with:
//
// int predictedLabel = -1;
// double confidence = 0.0;
// model->predict(testSample, predictedLabel, confidence);
//
string result_message = format("Predicted class = %d / Actual class = %d.", predictedLabel, testLabel);
cout << result_message << endl;
// Here is how to get the eigenvalues of this Eigenfaces model:
Mat eigenvalues = model->getMat("eigenvalues");
// And we can do the same to display the Eigenvectors (read Eigenfaces):
Mat W = model->getMat("eigenvectors");
// Get the sample mean from the training data
Mat mean = model->getMat("mean");
// Display or save:
if(argc == 2) {
imshow("mean", norm_0_255(mean.reshape(1, images[0].rows)));
} else {
imwrite(format("%s/mean.png", output_folder.c_str()), norm_0_255(mean.reshape(1, images[0].rows)));
}
// Display or save the first, at most 16 Fisherfaces:
for (int i = 0; i < min(16, W.cols); i++) {
string msg = format("Eigenvalue #%d = %.5f", i, eigenvalues.at<double>(i));
cout << msg << endl;
// get eigenvector #i
Mat ev = W.col(i).clone();
// Reshape to original size & normalize to [0...255] for imshow.
Mat grayscale = norm_0_255(ev.reshape(1, height));
// Show the image & apply a Bone colormap for better sensing.
Mat cgrayscale;
applyColorMap(grayscale, cgrayscale, COLORMAP_BONE);
// Display or save:
if(argc == 2) {
imshow(format("fisherface_%d", i), cgrayscale);
} else {
imwrite(format("%s/fisherface_%d.png", output_folder.c_str(), i), norm_0_255(cgrayscale));
}
}
// Display or save the image reconstruction at some predefined steps:
for(int num_component = 0; num_component < min(16, W.cols); num_component++) {
// Slice the Fisherface from the model:
Mat ev = W.col(num_component);
Mat projection = subspaceProject(ev, mean, images[0].reshape(1,1));
Mat reconstruction = subspaceReconstruct(ev, mean, projection);
// Normalize the result:
reconstruction = norm_0_255(reconstruction.reshape(1, images[0].rows));
// Display or save:
if(argc == 2) {
imshow(format("fisherface_reconstruction_%d", num_component), reconstruction);
} else {
imwrite(format("%s/fisherface_reconstruction_%d.png", output_folder.c_str(), num_component), reconstruction);
}
}
// Display if we are not writing to an output folder:
if(argc == 2) {
waitKey(0);
}
return 0;
}
...
// If you want to use _all_ Eigenfaces and have a threshold,
// then call the method like this:
//
// cv::createEigenFaceRecognizer(0, 123.0);
//
Ptr<FaceRecognizer> model = createEigenFaceRecognizer();//定义pca模型
model->train(images, labels);//训练pca模型,这里的model包含了所有特征值和特征向量,没有损失
model->save("eigenface.yml");//保存训练结果,供检测时使用
Mat eigenvalues = model->getMat("eigenvalues");//提取model中的特征值,该特征值默认由大到小排列
Mat W = model->getMat("eigenvectors");//提取model中的特征向量,特征向量的排列方式与特征值排列顺序一一对应
int xth = 121;//打算保留前121个特征向量,代码中没有体现原因,但选择121是经过斟酌的,首先,在我的实验中,"前121个特征值之和/所有特征值总和>0.97";其次,121=11^2,可以将结果表示成一个11*11的2维图像方阵,交给fisherface去计算。
vector<Mat> reduceDemensionimages;//降维后的图像矩阵
Mat evs = Mat(W, Range::all(), Range(0, xth));//选择前xth个特征向量,其余舍弃
for(int i=0;i<images.size();i++)
{
Mat projection = subspaceProject(evs, mean, images[i].reshape(1,1));//做子空间投影
reduceDemensionimages.push_back(projection.reshape(1,sqrt(xth));//将获得的子空间系数表示映射成2维图像,并保存起来
}
Ptr<FaceRecognizer> fishermodel = createFisherFaceRecognizer();
fishermodel->train(reduceDemensionimages,labels);//用保存的降维后的图片来训练fishermodel,后面的内容与原始代码就没什么变化了
...这样就实现了pca+lda的训练过程,将训练好的pca和lda模型保存起来,在识别时用训练好的pca和lda模型对检测样本提取特征,根据其最终结果判断图片性别,就大功告成了。
pca+lda不但可以做性别识别,还可以做“年轻/年老”、“人种”、“表情”等多种识别,效果也不错,但这类识别都有一个特点:每类的样本个数大致相等,且分类应该是完备的,否则就不适合用pca+lda的方法来做,例如:在一大堆的图片中识别出梅西,这种事情就不太适合用pca+lda方法来做。
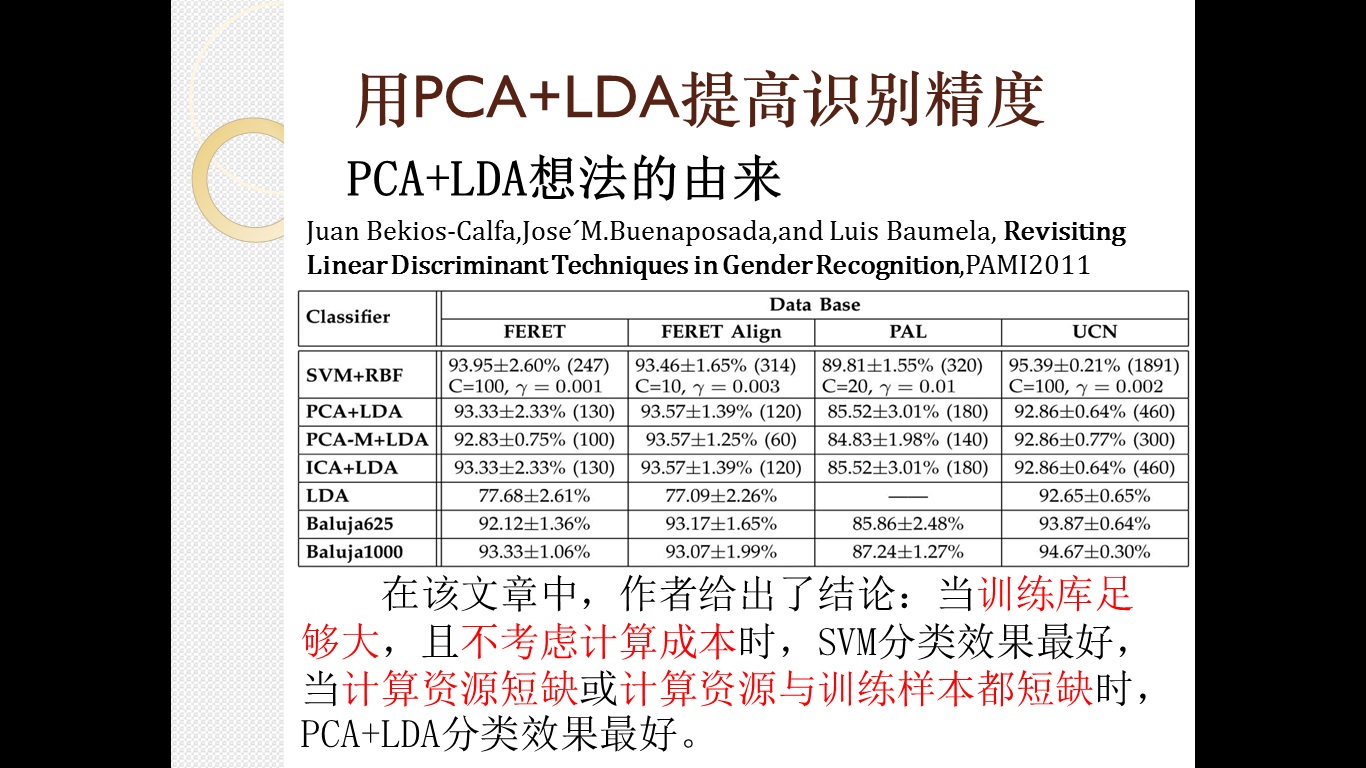
pca+lda方法在原理上和当前很火的深度学习存在着相似性,hinton大牛提出的多层结构:每层用无监督的方法提取特征,提取的特征又是下一层的输入,这一点和pca+lda很相似:pca是一种无监督的学习方法,提出的特征又作为lda方法的输入,大量实验证明多层深度学习会比浅层学习效果更好,这里的pca+lda就比单纯的lda或单纯的pca更好,大家也可以试试用多层pca+lda(即:pca+pca+...+pca+lda)会取的什么样的结果。