文章目录
Strom是什么
为什么使用storm
Apache Storm是一个免费的开源分布式实时计算系统。Storm使得可靠地处理无边界的数据流变得非常容易,就像Hadoop处理批处理一样,能够实时处理数据流。Storm很简单,可以和任何编程语言一起使用,使用起来很有趣!
Storm有很多用例:实时分析、在线机器学习、连续计算、分布式RPC、ETL等等。Storm非常快**:一个基准测试记录了它在每个节点每秒处理超过一百万元组**。它是可伸缩的,容错的,保证您的数据都被处理,并且易于设置和操作。
Storm集成了您已经使用的排队和数据库技术。Storm拓扑使用数据流,并以任意复杂的方式处理这些流,当你需要的时候,可以在计算的每个阶段之间重新划分流。
小结:Strom能实现高频数据和大规模数据的实时处理
Storm发展历史
从Twitter说起
Storm产生于BackType(被Twitter收购)公司
storm开发时的需求:大数据的实时处理
自己来实现实时系统,要考虑的因素:
- 健壮性
- 扩展性/分布式
- 如何使得数据不丢失,不重复
- 高性能、低延时
Storm的成长
Storm开源
2011.9
Apache
底层源码Clojure 开发语言Java
Storm技术网站
- 官网: storm.apache.org
- GitHub: github.com/apache/storm
- wiki: https://en.wikipedia.org/wiki/Storm (event_processor)
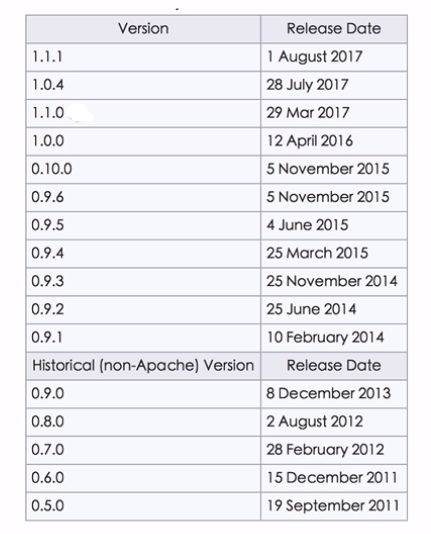
Storm和Hadoop的区别
Storm vs Hadoop
- 数据源/处理领域
Hadoop批处理/mapreduce;Storm实时处理/Spout Bolt - 处理过程
- Hadoop: Map Reduce
- Storm: Spout Bolt
- 进程是否结束
Hadoop进程结束后会停掉;Storm进程是实时流7*24小时运行 - 处理速度
Storm实时必须快速处理数据;Hadoop离线速度无所谓 - 使用场景
实时和离线
Storm和Spark Streaming的区别

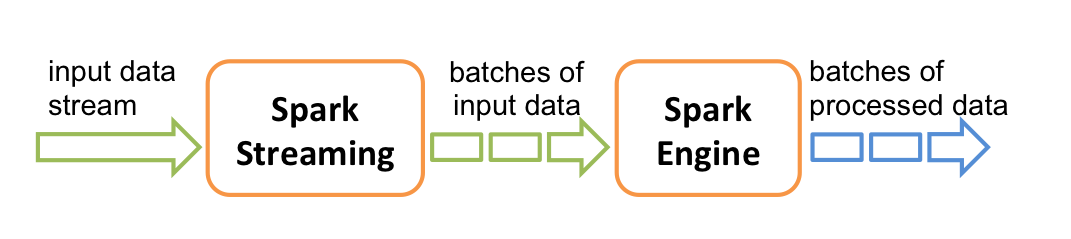
上半部分是从大方向来说sparkstreaming;下半部分是从内部分析saprkstreaming;它是把数据分为一个个batch交给engine来处理的;严格来讲它并不是实时流计算。
storm延迟是毫秒级别;虽然sparkstreaming目前也是可以设置秒级别,但是它需要设置微批的时间;到达时间周期后才会执行。
spark是一栈式的计算框架,解决各种环境各种需求,比如数据离线处理和实时处理,结果出来后又进行图计算和机器学习,spark可以在数据不落地的情况下进行下一步。而storm处理过的数据需要先落地再加入其他机器学习和图计算的框架工具。
实时要求很高,并且数据出来后没有其他操作,建议使用storm;实时要求不高可以忍受一两秒,或者数据出来后有其他操作如机器学习和图计,建议使用spark。
Storm的优势
编程模型:简易的接口,可以让java工程师快速上手
扩展性:分布式处理可横向扩展
可靠性:数据源发出的每一条数据都会进行处理,不会丢失;节点挂掉可以自动进行切换
容错性:硬件问题导致机器宕掉对应用程序没影响
Storm当前现状与发展趋势
发展趋势
1) 社区的发展、活跃度
2) 企业的需求
3) 大数据相关的大会, Storm主题的数量上升
4) 互联网 JStorm(阿里)